Shipping an AI Agent that Lies to Production: Lessons Learned

The peak of hype isn’t the best moment to reflect on AI. Will it take your job, or is it the next fad like NFTs? Are AI startups ridiculously overvalued, or are the companies that sleep on AI doomed?
Time will tell. LLMs are far from perfect, but I’m excited they’re here anyway. Not because of a silly promise to make me 10x more productive, but because they can solve some problems that were previously unsolvable. If you enjoy building software like me and Robert, it’s a new tool worth trying. And there’s a chance AI experience helps you create a better product or land a good job.
Did you ever get stuck debugging your project at 2 AM, and went to sleep frustrated? We spent a few weeks adding an AI Mentor to our learning platform to help our students avoid this.
As always, it wasn’t as easy as most tutorials show. Trivial use cases, like a weather-checking assistant, are fun to make, but aren’t much more useful than the default chat interface of any model.
I’ve heard before that implementing an AI feature is easy, but making it work correctly and reliably is the hard part. You can quickly build an impressive demo, but it’ll be far from production grade.
We can now confirm this is true. Plus, we’ve seen something not talked about that much: how an AI feature can fail in production and mislead users.
I want to share what we learned in detail, hopefully saving you time on research. Let’s set aside the world-changing stories for a moment and see what we can build with this stuff.
Note
If you’re just starting out
I know many developers stay away from AI because they consider it overhyped, unethical, or useless. They also feel massive FOMO because there’s currently no other topic in tech.
If you feel this way, I’m not trying to change your mind.
I encourage you to approach it like an engineer trying out a new technology. Look for what problems it can solve, while most people are busy applying AI to everything.
Once you use it in practice, you’ll have a good idea where it’s useful and where it falls short. You’ll make up your mind much better this way than reading hot takes from CEOs and tech bros.
Why AI Mentor?
We’re not VC-backed and don’t seek to sell our company, so there’s little value in slapping “AI-First” on our homepage. We wanted to use LLMs to solve a real problem our users had.
Our Academy platform is all about learning by building real-life projects. One of our challenges is helping students finish the training. If you have ever tried an online course, you may know this problem — you put it off after a few days and never return, distracted by something else.
One reason to put learning off is that you get stuck. While working on complete projects, it can be difficult to spot a bug. Example solutions don’t always help, since each project is unique. We help students move forward by reviewing their solutions.
Often, it’s a small typo or mistake that’s easy to catch with fresh eyes. There’s no learning value in fighting with such bugs for hours. Frustrated and stuck, some people give up.
Last year, we thought LLMs could help. You can feed them entire codebases and ask them to point out or even fix errors. And they are always available, in contrast to our limited time for customer support.
Back then, the models were expensive, far less impressive (GPT-4 had just been released), and there were few sources to learn from. But most of all, we lacked time and postponed the project. We came back to it earlier this year.
(If you want to see it live, the first few modules of Go in One Evening require no login.)
Milestones
We decided to start with an MVP and focus on the fundamentals, so we’re not distracted by nice-to-haves. We picked a few milestones and planned to implement each one in production before moving on to the next one.
- A single “Help me!” button on the website for Go in One Evening. Users would receive a single message with a hint on what’s wrong with their code.
- Conversations. While a chatbot wasn’t our main goal, asking a follow-up question about the solution could be helpful.
- Enable the Mentor for Go Event-Driven.
Go in One Evening is a simpler training with shorter exercises. We assumed solving the issues found there would be easier compared to Go Event-Driven, where students build more complex projects. (The final project is about 4k lines of Go code.)
The “Help Me!” Button
We created a proof of concept that should be easy to extend.
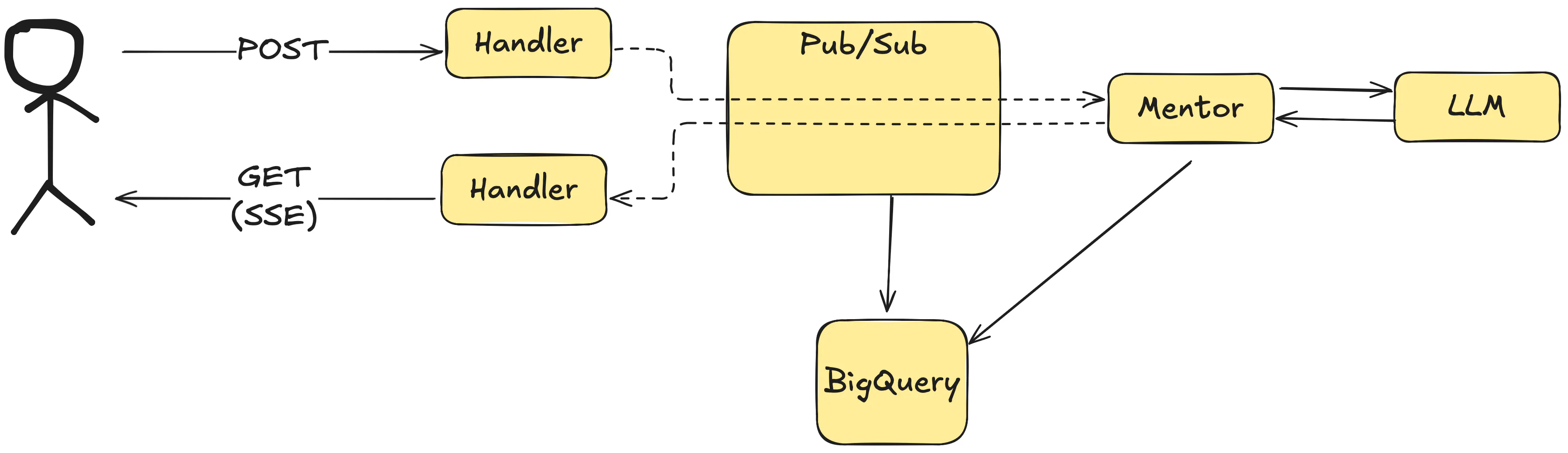
We started with two HTTP endpoints:
- a
POSTfor requesting help (for now with a constant “Help me” message) - a
GETstreaming all messages over Server-Sent Events (SSE).
In theory, a single endpoint could do both, but we wanted it to be asynchronous by default. Users can click the button and refresh the page without losing the response. Separating writes from reads is a good practice, especially for long-running tasks.
The downside is a bit more complex setup, but we use proven tools that we know well. We prefer event-driven patterns for asynchronous architecture. We use Watermill and Google Cloud Pub/Sub to trigger the Mentor and send updates back to the user.
All of our events end up in BigQuery, so we get storage for conversations out of the box. This is important because we need the history of messages to include in the next prompts.
This seemingly simple setup already has some challenges, even without considering the AI part:
- How to handle race conditions between the frontend app, the Pub/Sub, and the SSE handler?
- How to handle errors and retries?
- How to deal with BigQuery’s insert and select latency?
- How to approach message ordering?
Events
Event-driven patterns turned out to be a good fit for working with LLMs. Behind the scenes, there are many moving parts, and most need no input from the user. Failures and retries often happen, but they are all hidden behind a single response.
It’s why we don’t recommend using a single HTTP handler for the whole process. There are delays and interruptions, and you need to handle them, so your users don’t see the mess.
Most LLM APIs support streaming chunks of messages. You can show them on the UI before the model has finished generating the response. SSE is a perfect fit for this.
The first response of the SSE handler is a list of all messages (for the given user and exercise). Then, we stream all chunks over the Pub/Sub to the SSE handler and then to the browser.
We had a great experience working with SSE before, and watermill-http supports it out of the box, so it integrates nicely with our architecture. We’ve improved the implementation by adding support for generics (although it’s not public yet, we may release it at some point).
It’s all hidden behind a high-level interface. The HTTP handler receives a channel of incoming events and a channel to send responses back to the client.
func (h *Handler) HandleEventStream(
r *http.Request,
events <-chan *events.MentorMessageSent,
responses chan<- any,
) {
// Send the initial response with all messages
messages, _ := h.getAllMessages(r)
for _, msg := range messages {
responses <- msg
}
// Process incoming events
for event := range events {
// ...
responses <- response{}
}
}
Note
If you want to learn more about Server-Sent Events, we have a dedicated post about implementing it in depth: Live website updates with Go, SSE, and htmx.
Calling LLMs
We initially used langchaingo for calling the LLMs, but the API felt a bit bloated for our needs.
We created a small wrapper on top of the official SDKs to be able to switch the models quickly.
The design of most LLM APIs is very similar. You can describe a prompt call like this:
type Model interface {
Prompt(history []Message) (Message, error)
}
It’s a function that accepts a chat history and returns the next message in the chat.
In practice, we ended up with a few more details:
func (l *LLM) Prompt(
ctx context.Context,
history []Message,
user User,
opts PromptOpts,
) (*Output, error) {
// ...
}
type PromptOpts struct {
MaxOutputTokens int
Model ModelName
Tools []ToolSchema
}
func (o *Output) Listen() (<-chan Chunk, error) {
// ...
}
func (o *Output) WaitAndGetAll(ctx context.Context) (string, error) {
// ...
}
This is a tiny abstraction over the LLM API, just enough to make it easy to switch between models.
Similarly to SSE, Go channels are the perfect API to stream chunks. It works well with the whole asynchronous model, and it’s great to have support for it on the language level.
Prompts & Context Engineering
We spent a lot of time iterating over the prompts and the context we fed to the model.
For example, we wanted the Mentor to hint at the right direction, but not simply give the complete answer. We ended up with quite a long prompt for something as simple as “Help with this exercise”.
We have many files related to each exercise (the user’s solution, an example solution, and many others). Even though models now easily handle long contexts, we still need to be careful about how much we feed them.
Deciding what context to provide needs careful balance. If you dump too much and the context window grows, the prompts get more expensive, and the models are less likely to follow the instructions. If you provide too little, the model may not understand the problem and give a useless answer.
There are really no rules that work for every case. One thing we found helpful is strong language in the prompt. The models seem to follow wording like “ALWAYS” or “NEVER” better than “should” or “shouldn’t”.
Free-form chat
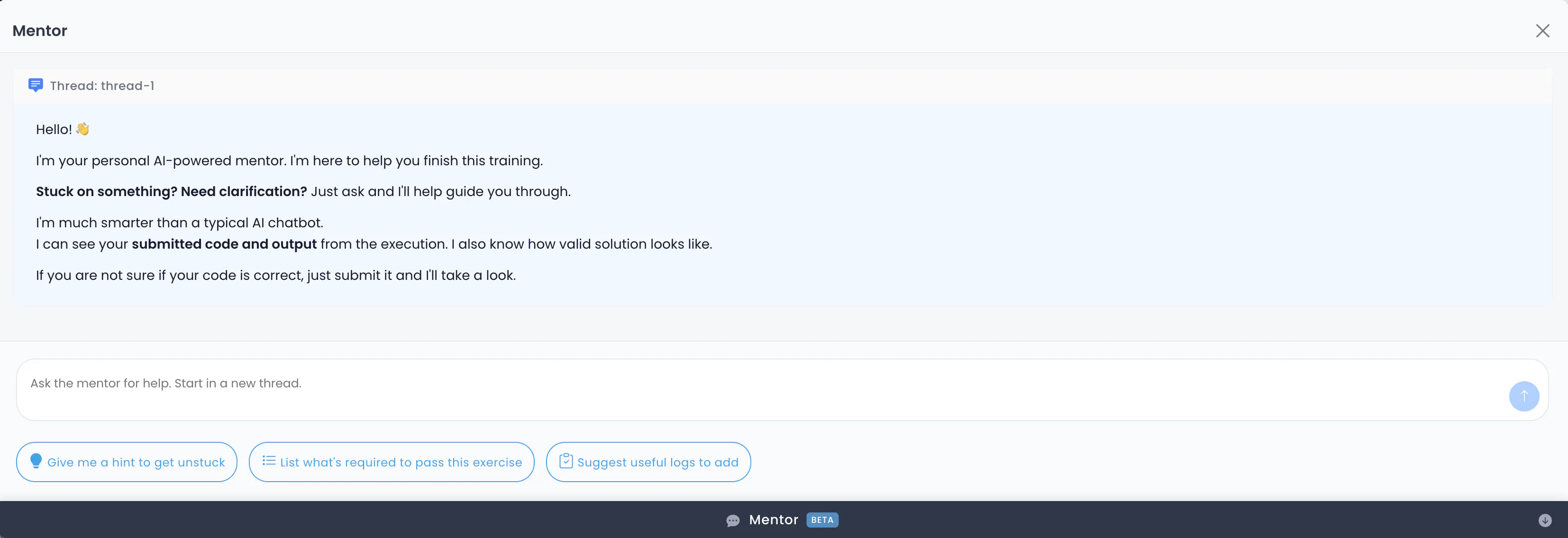
After the initial response, users can ask about the solution or other things related to the exercise.
This part was quite straightforward since we had already made the MVP ready to work with threads of messages. The key here is getting the historical messages to include in the future prompts.
In our case, we fetch the chat history from BigQuery. We retrieve what we can concurrently, so the time to the first response chunk is short.
Solving Complex Projects
This approach worked pretty well, even though we used a single prompt. For shorter code snippets, it could guide students on what’s wrong with the solution.
But for complex exercises, it failed miserably. With big projects, the model often made mistakes. It tried to fix issues that didn’t exist or completely missed what was wrong.
We improved it a bit with better prompts and more context about common concepts. But for the most complex examples, it wasn’t enough. So we experimented with a more advanced approach, which you could consider an agentic system.
Fixing the Solution
The tricky part of generating hints is that we can’t be sure whether the model is right.
It’s how your AI feature can (and likely will) fail in production. To counter this, you need to be able to verify the model’s output.
In our case, we built a system similar to coding agents like Claude Code. We use it to fix the user’s solution before it gives any hints. If it succeeds, we have some confidence that the model is on the right track.
This approach solved the issue of the model making wrong assumptions. If it tried one approach, and it didn’t work, it would realize the issue is elsewhere.
Among other things, the agent can edit the user’s submitted files. These changes happen only in the Mentor’s context — the user doesn’t see them. It also plans what to do, can summarize the changes, and a few other tricks. Different models excel at different tasks, so we can use the best one for each step.
In the code, an agent is pretty much a for loop plus tool uses.
It’s a bit like a regular chatbot, except the model “talks” to itself.
You keep the history and add messages with feedback on the environment.
The context grows with each iteration, so it makes sense to limit the attempts.
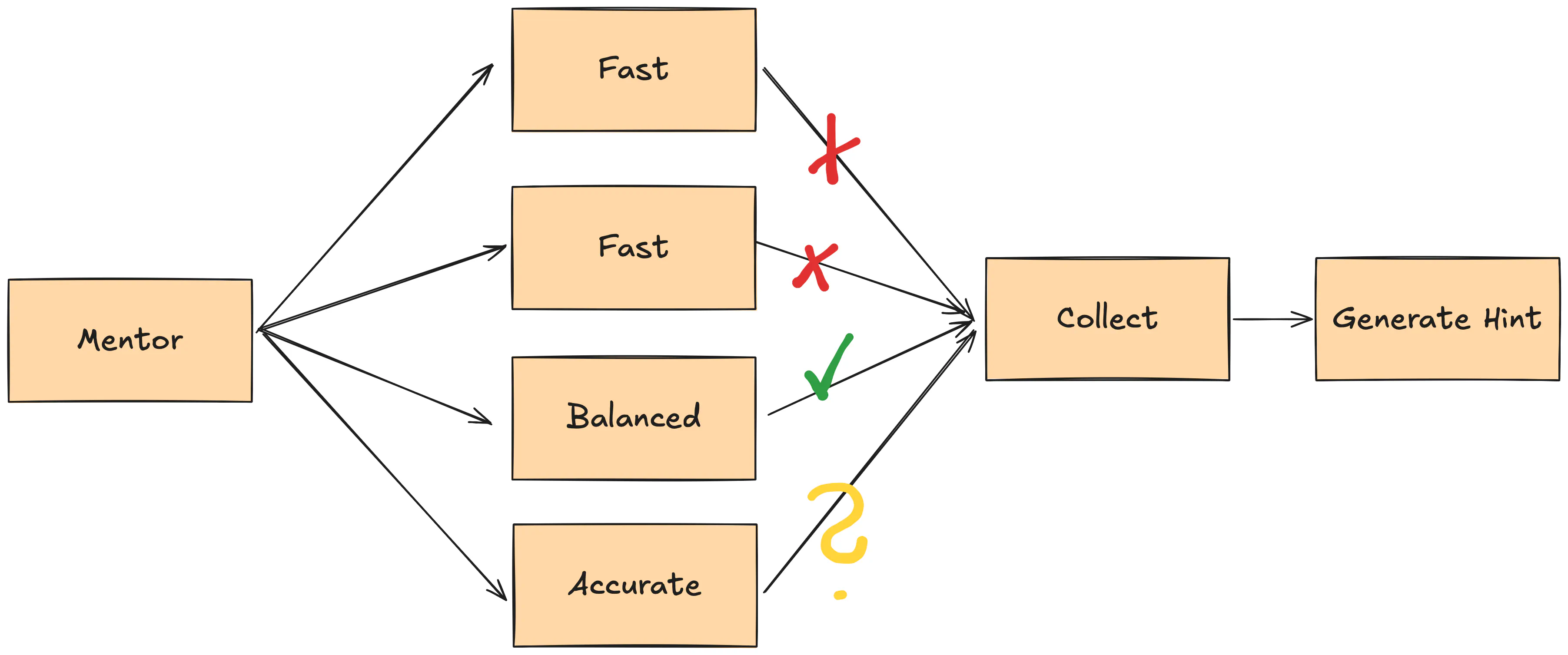
Parallel Runs
The new approach sometimes brilliantly succeeded. But other times it was stuck, failing to edit a file, or just not getting the original issue.
The good part was that it could now tell the user it didn’t know the solution, rather than making things up. That’s a huge improvement — if someone is already stuck, we don’t want to mislead them further. But it wasn’t able to fix the solution on each attempt. You had to retry a few times if it failed.
We noticed that if the model didn’t succeed in the first few attempts, it would only get worse. It made more sense to start over.
So we started running a few agents in parallel, each trying to fix the solution. Once one succeeds, we stop the rest.
Managing concurrent code like this is a pretty common pattern in Go. We feel it’s a great fit for AI engineering thanks to its concurrency model (compared to other languages, like Python).
wg := sync.WaitGroup{}
wg.Add(workers)
for i := 0; i < workers; i++ {
go func() {
defer wg.Done()
for cfg := range configsChan {
ctx, cancel := context.WithTimeout(ctx, workerTimeout)
defer cancel()
select {
case <-ctx.Done():
return
default:
}
result <- Solve(ctx, mentorContext)
}
}()
}
go func() {
wg.Wait()
close(result)
}()
for {
select {
case <-ctx.Done():
return nil, ctx.Err()
case r, ok := <-result:
if !ok {
return nil, ErrCantHelp
}
if r != nil {
return r, nil
}
}
}
We use many combinations of models to increase the chances, hence the configsChan.
Different models excel at different tasks, so we can use the best one for each step.
Also, if a cheaper model manages to finish the task fast, we can save some money on the expensive ones.
Often, a single call couldn’t reliably figure out the solution. This shotgun approach improved the chances. The tradeoff is cost: we pay for all started parallel runs, even if we finish them early.
Join over 18k subscribers of our newsletter and get a free e-book!

Go With The Domain Three Dots Labs
QA: Tests & Evals
In many projects, testing is an afterthought. It turns out it’s crucial when working with LLMs. And testing AI products can be a nightmare.
It doesn’t seem that different at first. Calling a model is similar to using any other API, so you need to prepare test cases with inputs along with the expected outputs. But there are some caveats.
Challenge #1 is judging the responses. An optimistic scenario is when you make the model return a structured output, with a well-known list of valid values. Good old unit tests can work well if you have enough test cases.
But if you let the model respond in free-form text, like in most chatbots, it quickly gets complex. You need an evals system where you judge if the output is correct. You could either use a human to do this or another LLM call.
Whatever you choose, expect to read lots of data. You need a realistic set of inputs and outputs, and you need to review and label them.
Once we kicked off the project, we spent a few days manually going through possible test cases based on production data. It seemed unproductive at first, but if we skipped this part, we would have no idea if what we built works. It also helped us understand the problems people actually face.
Challenge #2 is time. If you want to use the smartest or thinking models, a request can easily take tens of seconds. But even with faster models, running a few prompts in a sequence is far from unit test speed. This slow feedback loop is annoying to work with, especially if you tweak the prompt slightly and want to see the impact right away.
Challenge #3 is cost. The best models are also the most expensive. If your context grows (some of our evals have context with 100k+ tokens), each test run costs real money.
Because of #2 and #3, forget about running a big set of evals in CI on every commit (unless you have too much VC money to burn). You can run some of them, or do it only once in a while. In our case, the trivial test cases (fast and cheap) are not that interesting, because even the less capable models solve them easily. The longest and the most expensive ones are what we care about the most.
In regular tests, you can mock the expensive or slow resources. It makes little sense here, as you need to validate the same models you’ll run in production.
Since we run parallel workers for each mentor call, it also impacts the evals. While not a big difference in the production environment, it makes evals much more expensive. It was also easy to hit the API limits.
So, in the evals, we run the workers sequentially, starting with the cheapest ones. It slows down the tests, but saves us some money (this makes a difference, especially for bigger contexts).
On top of all this, LLMs are unpredictable, so you may want to run a few iterations of each eval for more realistic results. This multiplies both time and cost.
You need to balance many factors.
We didn’t use any framework, but a script written in Go that runs the evals and collects the results.
Because evals take a long time to run and could be interrupted by some error, we implemented a cache and retry mechanism, similar to what go test does.
It’s frustrating to spend five minutes waiting for tests, only to realize you forgot a simple change and have to start over.
Failing in production
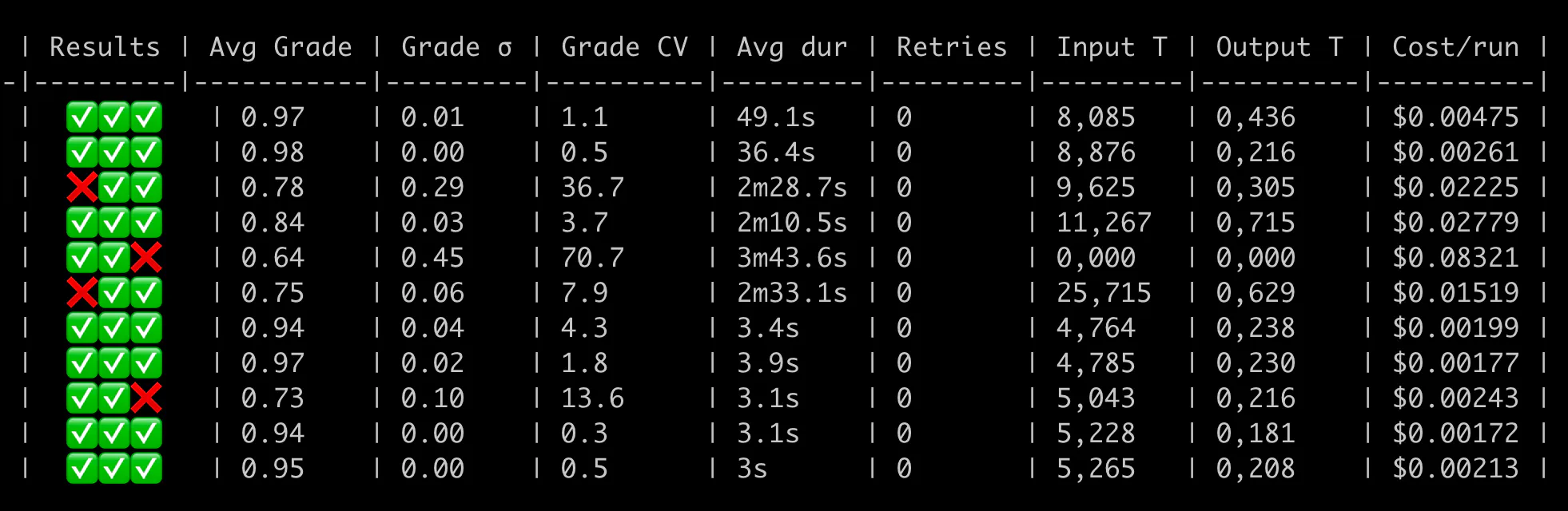
After rolling out the first version of the Mentor, we monitored the responses to see how it did. Shortly after, came this:

I started sweating when I saw this. People pay us to teach them, so it’s a huge risk if they learn obviously wrong things.
In this case, the student tried to understand if assigning a slice to another slice in Go results in a deep copy. The model happily agreed, even though it’s not true.
We take teaching people seriously. I almost wanted to scrape the entire feature when this happened. We contacted the student right away to clarify the issue. Thankfully, they appreciated the detailed explanation and weren’t angry.
To counter this, we switched to a better model for conversations and added more context to the prompts (details below).
The worst part about hallucinations is that the model is very confident about being right. When you just start working with LLMs, you’re surprised how often it happens. You need to be ready for it, because it WILL happen in production.
This is why I’m not comfortable learning something in-depth just from an LLM. If it’s something you can quickly check, it’s not a big deal. But learning fundamentals the wrong way is another story.
RAG and Sources
Initially, we assumed we didn’t need to use RAG (Retrieval-Augmented Generation), and we simply always added some documents to the context.
But after the first issues, we decided to implement a simple RAG with things like Go documentation, our blog posts, and other resources. We have a simple database of content in Markdown format.
The RAG hype presented it as some mindblowing technology, but it was rather simple to implement. It took us just two days to have an MVP in production. It helped that we could split the work and implement two parts in parallel: building the database and querying it in the mentor code.
As a bonus, we also link to the sources in the response, so students can read more about the topic.

Predictability
If you expect a structured output from the model, like “true” or “false”, or a set of answers, testing is much easier. But dealing with free-form answers, like with most chatbots, is entirely different.
One day, I started tweaking the temperature setting, assuming lower values should work well for our needs. Then, I realized there’s no way to tell unless I compare multiple responses manually or write an eval that focuses on this difference. And even then, I’m not sure if the reason was my change.
It’s very difficult to get predictable results from LLMs. Small changes in the prompt have effects on the whole pipeline. The more complex the system, the less predictable the outcome, and the harder it is to test.
After you change the prompt, you need to run the evals. But probably not all, since they are slow and expensive. But then, if you test only a few, you don’t know if it covers all cases.
If the response changes, you can’t be sure it’s due to your changes. Maybe it’s just a different random response. Or maybe the model has been updated overnight (you have no visibility into it). To have a better idea, you could run more iterations of each eval, but this increases both time and costs.
The developer experience of changing the prompt and waiting for results is quite poor. It’s nothing new: it’s like working with a slow or flaky CI/CD pipeline, where you commit changes and can’t spend the next five minutes on anything productive. The context switch is painful. You can counter this with parallel runs, but you can hit usage limits this way, and it’s then easy to burn money within a few seconds.
How you model your evals is key. We ended up with two kinds of evals:
- Strict evals, where we expect a given percentage of scenarios to pass. We can use them reliably in the CI pipelines.
- Graded evals, where we run a set of scenarios and manually compare how the results changed according to grading.
Shifting the Mental Model
How do you cope with software that doesn’t follow instructions?
Often, you like the LLM’s output 90% of the time, but the remaining answers are confusing or outright wrong. This can be frustrating if you’re used to working with code.
There are many ways to reduce hallucinations, but there’s no way to avoid them completely. Realizing this helped me change how I think of LLMs.
I see people go to two extremes:
- Treating LLMs as sentient beings, trusting the model to do exactly what they ask, if the prompt is good enough: “Bro, I found a way to make GPT never lie to me, just use this prompt.”
- Skeptical about using LLMs entirely, making fun of prompt engineers having to beg the model to do what they want.
A middle ground I found is to treat an LLM as a function that is excellent at parsing vague inputs, and the output is often brilliant, but sometimes nonsense. I treat prompts as code, but with less strict rules than I was used to.
With this mindset, it’s easier to be pragmatic and remember not to blindly trust the output. But also not getting discouraged after something breaks.
✅ Tactic: Expect LLMs to fail
LLMs are impressive but unpredictable. Don’t treat them like the code you’re used to.
Be ready for failures and hallucinations. If you can, verify the output.
Agentic systems or autonomous agents?
The top 2025 trend is running autonomous agents that make decisions independently.
But thinking of an agent as a sentient being that can figure out what to do in every scenario is a trap. Code always works in contrast to an unpredictable LLM.
We didn’t need to go all in on the agent running all workflows by itself. For example, we can just decide (in code) what steps the coding agent should take next.
When writing regular code, you need to control the agent loop more directly. It’s tempting to think you can just include in the prompt what the agent should do in every scenario. But the reality is, you have no guarantee it will follow your instructions exactly.
Our agent isn’t super complex, but it doesn’t need to be. If you can predict when to hand over to regular code or another LLM call, just do it in the code. No need for an agent framework where agents know about each other and can decide who to “talk” to.
Especially if you can’t verify the output, how can you trust the agent to make the right decisions?
This agentic hype feels like the early days of microservices when we told ourselves the story of independent entities talking to each other. Then everyone jumped to implement the solution, without considering whether it actually solved anything.
Many teams learned the hard way that distributed systems are difficult to get right. Even with classic, perfectly predictable code. I’m not eager to add unpredictable models to the mix.
✅ Tactic: Use LLMs where they shine
If you can handle the problem with regular code, there’s no need to use LLMs.
Don’t think of agents as sentient beings that can figure everything out by themselves.
Where is the complexity?
The length of this post shows how much goes into one AI feature, and not all of this effort is related to LLMs. Most of it is good old software engineering and product design.
I will risk saying that building the Mentor was 80% regular software development and 20% AI-specific parts. And 80% of the latter was creating and running evals.
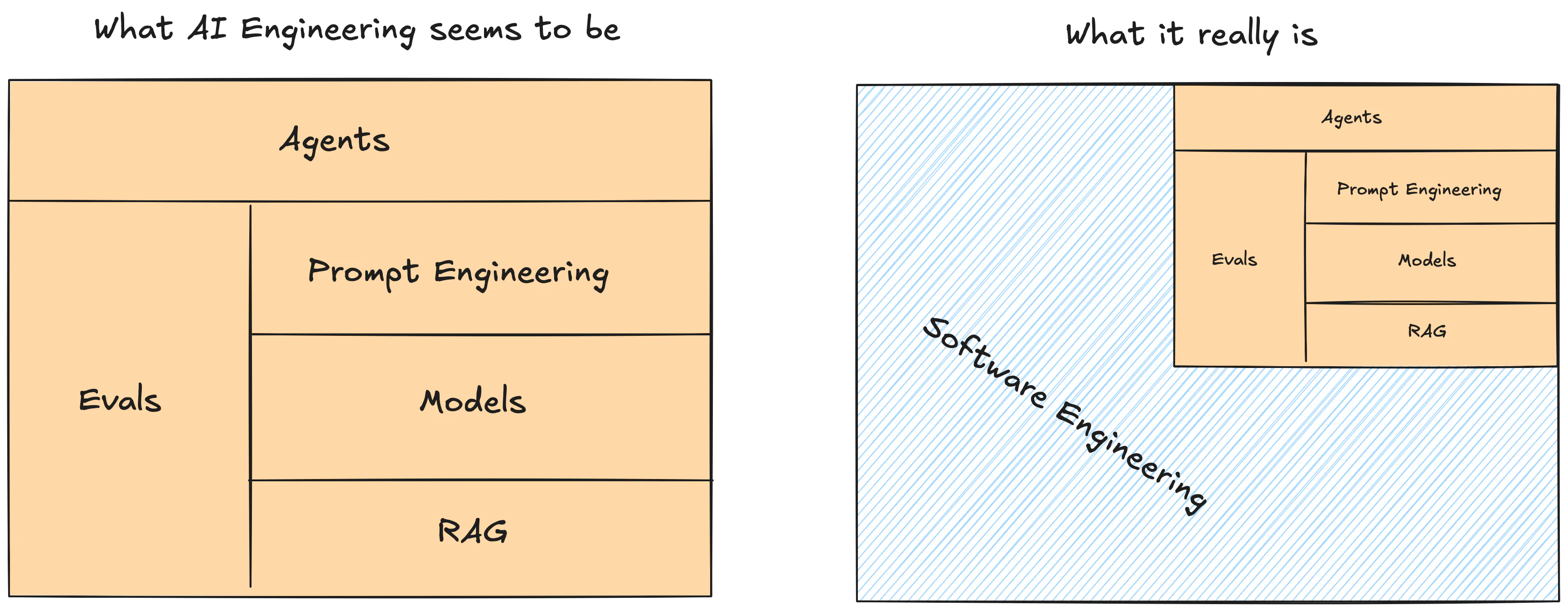
Most of the complexity is in the orchestration. All well-known patterns and good practices still apply. This agent-orchestrating code is your domain logic.
Once again, Go shines for such use cases. It’s trivial to run concurrent workflows, and channels are a great way to communicate between different parts of the system. The logic is easy to follow. (And Go is easy to learn!)
Models
We accidentally picked a hot moment in model releases.
We started with Gemini 2.0 Flash — it had a 1 million token context window, a generous free tier, and was relatively cheap overall. Then, Gemini 2.5 Pro came and made Flash look silly. It had a much better understanding of code. Then GPT-4.1-mini came and made Pro look expensive and slow.
In retrospect, it’s good we didn’t implement this feature one year ago, since the models got so much better over time.
Picking the right model is a balance between speed, cost, and quality. You need to be able to switch models easily for tests, so make sure your system is not tightly coupled to a specific model.
We eventually landed on OpenRouter. You can use the Go OpenAI SDK to call any provider’s model, which is great by itself. It also has no strict rate limits (we hit limits running evals on OpenAI). Finally, it centralizes billing and lets you set limits and budgets (something unheard of for Gemini — crazy!). The downside is some extra cost and latency.
Limits & Costs
One feature of our internal LLM library is limits.
We designed it so that calling an LLM is not possible without using the limits. Even tests track limits in-memory.
It’s too easy to lose track of how many tokens you use. One day, we spent $100 running evals. After that, we made the cost clearly visible in all of our tooling, including tests running in the CI.
Gemini is an especially awful experience. There’s no way to set budget limits, and the usage shows up with a delay. Thankfully, other providers offer basic services like budgets or prepaid payments. As mentioned above, OpenRouter also works great for this.
We can set limits on a few different levels. The primary one is per user. It’s not a perfect solution, since more complex projects can quickly exceed the limit. It’s something we will try to improve in the future.
The costs of running in production so far are just a tiny fraction of our infrastructure costs. The surprisingly expensive part has been running the evals. The faster you want them to run, the easier it is to burn money quickly. Thankfully, this happens only once in a while when we change the prompts or add new evals.
Observability & Tooling
As in any complex system, debugging AI features is difficult. Good tooling helps.
Tracing is a great way to understand how the system works. We didn’t use anything AI-specific for tracing, as we like simple tech stacks and proven technology. We already use tracing in our project, so it was just a matter of adding spans and propagating them.
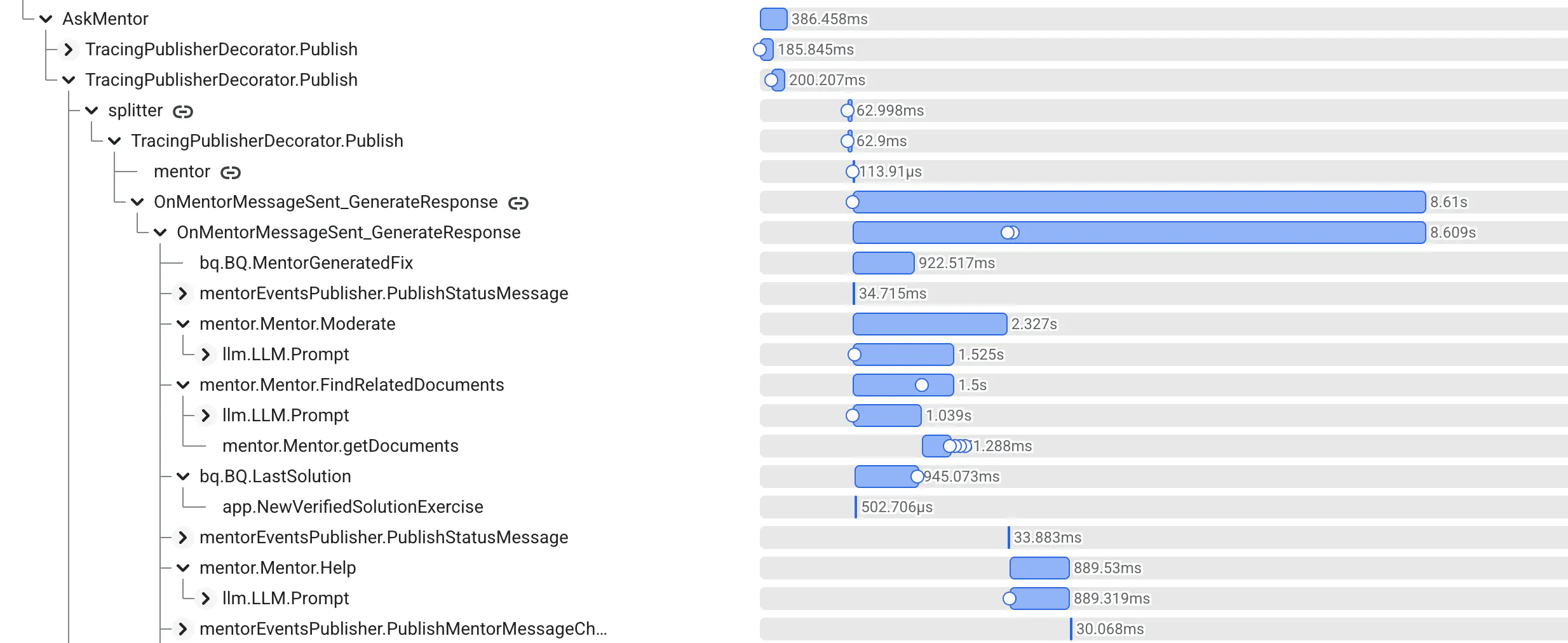
We also created a back-office dashboard to track the cost and usage, and a set of CLI tools to easily manage evals.
Moderator
We wanted the Mentor to avoid unrelated topics, as it was more likely to give incorrect answers then. We set some guardrails in the prompts, but it was easy to work around them.
Our second approach was a separate moderator prompt.
It has two functions: filter out irrelevant topics and decide if the user needs help with the exercise or just asks a question. If it’s just a question, we don’t need to fix their solution, so it’s a much simpler and faster prompt.
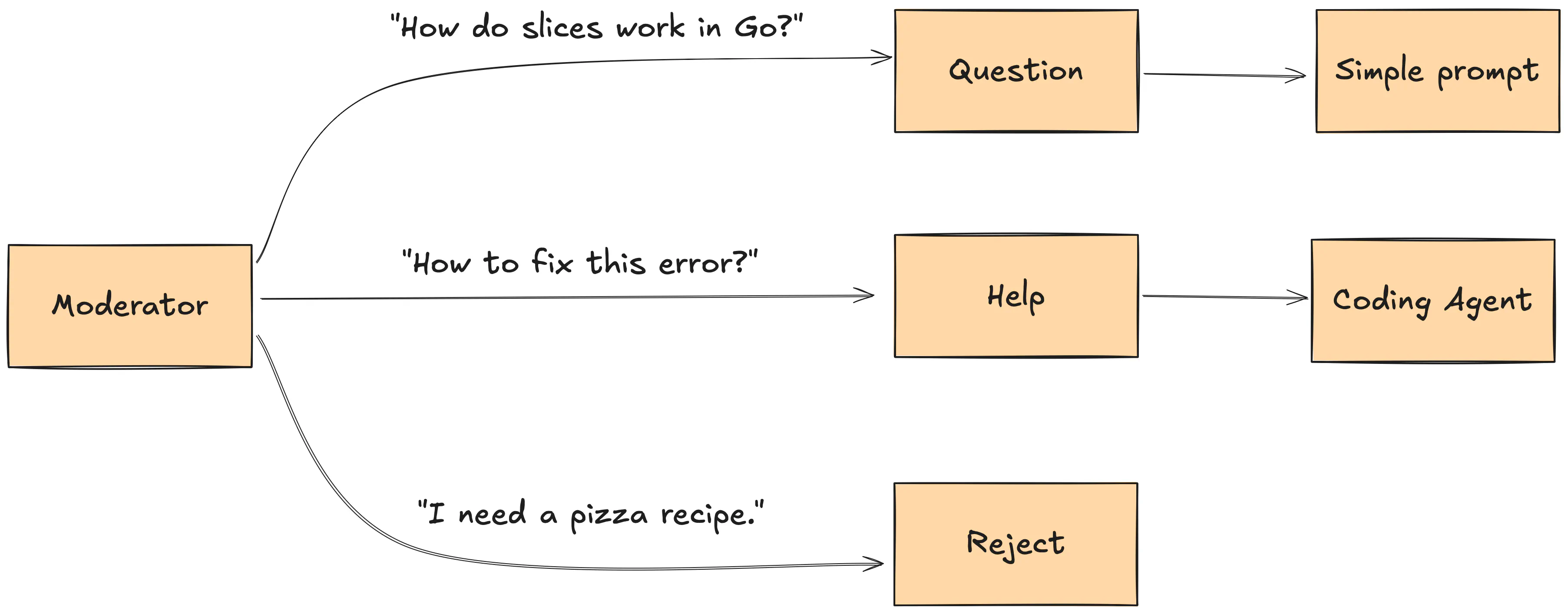
It’s a classic example of how asking the model to do too much at once is problematic. Similar to classic software, the separation of concerns is a good idea. One prompt should focus on one task.
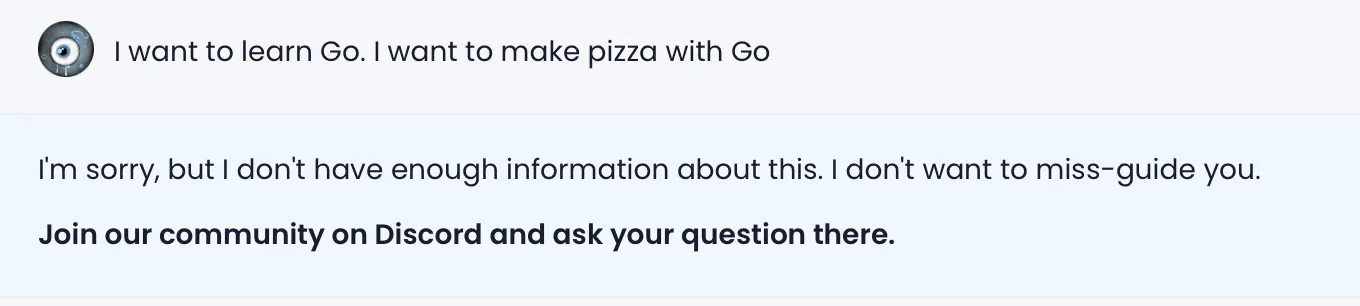
Encouraging students to ask for help
Implementing the Mentor was one thing, but it wouldn’t be effective if students didn’t know it existed.
People are already fed up with companies shoving AI features their way, and since most chatbots are dumb, it’s not tempting to click the button.
We track the failures and show small hints in the CLI. Plus, we use the same SSE endpoint to stream hints and show an indicator on the website.
Sometimes, students still ask us directly for help. We don’t want to point them straight to the Mentor, as our support is part of the product. Now, we can use the Mentor ourselves to find what the issue is, and then we just need to explain it to the student. Finding a small typo is much easier this way.
The UI
We’re not frontend experts, so I will shortly mention the UI parts for completeness.
We use React and have vibe-coded most of the Mentor’s frontend code. We’ve been working with frontend for many years, but it’s not something we enjoy. Generating the code was a great way to start: we understand enough to know what we want, but we don’t have to write it ourselves.
We find AI-assisted coding works well for software that has no “strict behavior”, and you can quickly tell if it works, like UI and video games. For example, if the generated CSS is silly, but looks fine, it’s not a big deal. Especially if it’s just a single component. Of course, if you go too far with it, it can turn your project into a mess.
We use a polyfill for SSE. It supports features not in the official spec, like passing custom headers in the API (Authentication), and it works out of the box.
One thing to consider with a chat interface is that you need to animate the chunks when streaming (delay the letters slightly). If you make them appear as they come, it doesn’t look as good.
At some point, we added status messages to show that the Mentor is working on the response. Sometimes it takes a few minutes, so it’s easy to lose patience and think it stopped working. These messages are not fake — we stream them from the backend via the same SSE endpoint.

Outcomes
We ended up with something good enough to make it public and observe what happens. We see people use it, and most of the time, the response does the job.
What we haven’t tried yet:
- Running an open-source model on our own.
- Fine-tuning models.
- Judging the responses by another LLM on the fly.
- Pre-computing hints before someone asks for help.
- Partially reading files instead of dumping the whole codebase to the context.
Even without these, we feel the result is pretty impressive compared to most chatbots.
The key lessons learned for us (hand-crafted by a human so you don’t need to paste this post into an LLM):
- LLMs are not magic, but they can solve some problems that were previously unsolvable.
- Building an AI feature is easy, but making it work reliably is a whole different story.
- The complexity is in the orchestration, and the old software engineering practices still apply.
- You don’t need a framework to get started. A tiny wrapper around the LLM API is enough.
You need to watch out for:
- The hype stories don’t mention the full picture. Try things yourself!
- LLMs WILL hallucinate in production, be ready to handle it.
- Testing AI systems (evals) is difficult to get right and can be expensive.
- It’s easy to go over budget. Implement limits early.
If you want to see the Mentor live, you can try the free part of Go in One Evening (no login required).


