Distributed Transactions in Go: Read Before You Try

In the previous post, I looked into running transactions in a layered architecture. Now, let’s consider transactions that need to span more than one service.
If you work with microservices, a time may come when you need a transaction running across them. Especially if the way they are split was an afterthought (the unfortunate but likely scenario). Service A calls service B, which calls service C, and if something goes wrong at the end, the system becomes inconsistent. It would be helpful to have a way to roll back the changes in all the services.
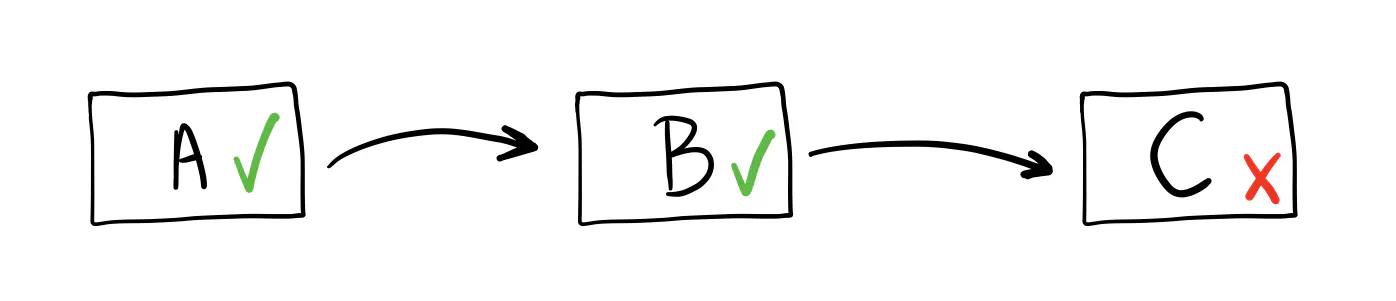
Now, you’re looking at distributed transactions or the saga pattern. It’s a solved problem. Sometimes, there are good reasons to use them. But more often, it’s overkill. If you go down this path, your architecture quickly becomes much more complex than you’d like. (I learned this the hard way.)
If you need things to be consistent, why split them in the first place? The whole idea of using microservices is to keep independent concepts separate.
Let’s face it: your microservice boundaries are likely wrong if you consider using a distributed transaction. This is super common and not easy to solve. But it can get much worse if you apply the wrong pattern to the mess you already have.
Before you try it, I want to show you an alternative that might be simpler. It’s not a silver bullet, but consider it before committing to distributed transactions.
❌ Anti-pattern: Distributed Transactions
Stay away from transactions that span more than one service, except when there's no other way.
They are hard to test, debug, and maintain.
Your system becomes tightly coupled and more challenging to extend.
The Example
The snippets below continue the example from the previous post. Here’s a quick refresher: we work with an e-commerce web app where users get virtual points. They can use these points as a discount for their next order. The challenge is keeping the user’s points and the applied discount consistent.
Let’s assume we work with two services: users for authentication and orders for placing orders and tracking users’ discounts.
Initially, the split seemed like a good idea because they are separate areas.
Later, we realized we couldn’t update users and their discounts within one transaction.
The orders service exposes an HTTP endpoint for adding a discount.
In the users service, the handler for using points as a discount looks like this:
func (h UsePointsAsDiscountHandler) Handle(ctx context.Context, cmd UsePointsAsDiscount) error {
err := h.userRepository.UpdateByID(ctx, cmd.UserID, func(user *User) (bool, error) {
err := user.UsePoints(cmd.Points)
if err != nil {
return false, err
}
return true, nil
})
if err != nil {
return fmt.Errorf("could not update user: %w", err)
}
err = h.ordersService.AddDiscount(ctx, cmd.UserID, cmd.Points)
if err != nil {
return fmt.Errorf("could not add discount: %w", err)
}
return nil
}
We first take the user’s points. After committing the transaction, we call the orders service to add a discount.
It works well in a happy path scenario, but the HTTP call works outside the transaction.
If anything goes wrong, the points are gone, but we add no discount.
The best we can do is log the error and fire an alert so someone on-call can manually add the discount for the annoyed customer.
Welcome to the distributed monolith.
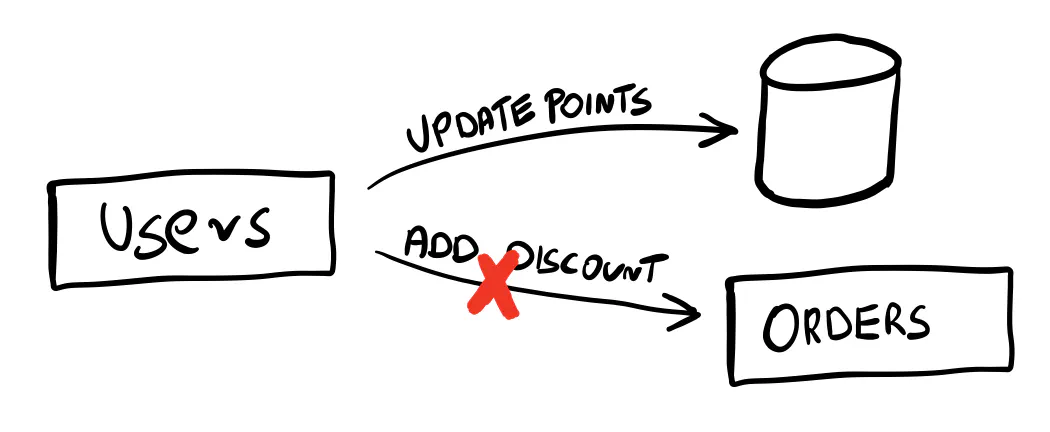
❌ Anti-pattern: The Distributed Monolith
Be extra careful when designing the boundaries of microservices. What seems like a minor decision in the beginning can have terrible consequences in the future. If in doubt, stick to a single service and decouple your code using modules — the modular monolith approach.
One way out of this mess is to accept past mistakes and merge the microservices into one service. Depending on the approach used and the size of the services, it may not be a quick task. And if your product backlog is full and people who designed the microservices are still around, it’s unlikely to happen.
If you see the problem as “we miss consistency between services”, running a distributed transaction seems like a good solution. But the real problem is “the boundaries are wrong”. It’s easy to make the project much more complicated because of this misinterpretation.
One alternative is to embrace eventual consistency.
Eventual Consistency
The idea is that the data (the user’s points and applied discount in our example) stays consistent but no longer within a single transaction. In practice, there’s a slight delay — usually milliseconds — during which the system is inconsistent but then catches up.
The system may become out of sync for longer if something goes wrong. But the important part is that it eventually becomes consistent again. We don’t accept inconsistency — we’re just okay with waiting for it to happen. Think about sending a bank transfer. The money disappears from your account immediately but isn’t visible on the other account right away. You know it will eventually happen within a few hours or days, so it’s not an issue.
Whether it’s acceptable in a given scenario is often a business decision. Since business stakeholders generally don’t consider this, engineers must explain it and suggest solutions.
Having a transaction boundary sounds reasonable in the “using points as a discount” scenario. But since we already have to work with a distributed monolith, choosing eventual consistency might be the next best thing instead of implementing a distributed transaction.
Note
I could have picked another example that would be more fit for eventual consistency. In some cases, data doesn't need to be consistent at all.
But this scenario is closer to what you can see in your daily work.
Using a distributed transaction here may be tempting because it's not obvious if the data can be eventually consistent.
Events
Eventual consistency usually means working with events.
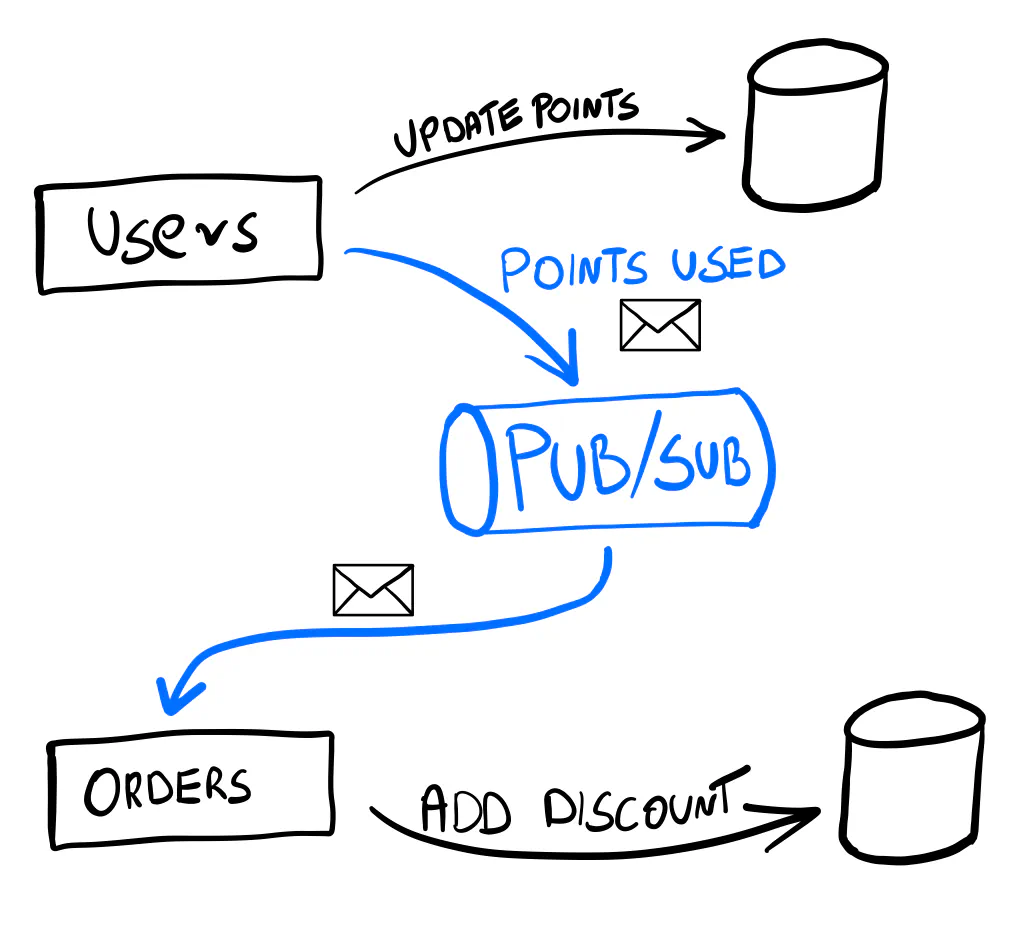
Going this path, we no longer call the orders service directly.
We take the user’s points and publish an event, like PointsUsedForDiscount, to record that it happened.
The event is stored on a message queue (AKA a Pub/Sub), a reliable, highly-available infrastructure for messages.
The orders service receives this event and reacts by applying a discount for the next order.
We can then update the discount value on the website (for example, with Server-Sent Events).
Most of the time, it takes milliseconds, and the customers can’t tell a difference.
It’s sometimes better to retry the operation internally instead of showing a scary error message to the user. After all, the issue might be temporary, and retrying is often a good enough fix. However, you need to consider it separately for each scenario. It’s often crucial that the user knows an error has occurred.
If the orders service goes down, it won’t interrupt the process.
The event will be delivered again and again until it’s processed successfully.
Once the service comes up, the discount will be applied as expected.
It doesn’t fix all the issues. For example, the customer won’t see the discount if the service is down for a few hours. But it gives us a solid way of retrying the operation if it’s a short issue. In many scenarios, retrying for a few hours is also acceptable (generating reports, issuing invoices, etc.).
In most cases, we don’t need to manually investigate what data needs to be backfilled, and no one needs to wake up in the middle of the night. The system auto-heals with time.
✅ Tactic: Embrace Eventual Consistency
Not all operations need to be strongly consistent, even if it initially seems like it.
Keep eventual consistency in mind when designing distributed systems.
It's often simpler than going the distributed transactions way.
Note
Events or messages?
While sometimes used as synonyms, there's a difference between events and messages.
A message is a transport unit you publish to the Pub/Sub or receive from it. It's similar to an HTTP request with a method, path, headers, and body.
An event is a specific message. It represents a fact about something that has already happened in the system.
The event is represented by the payload held by the message (encoded as JSON or another format). It's what you would include in the HTTP request's body.
Join over 18k subscribers of our newsletter and get a free e-book!

Go With The Domain Three Dots Labs
Implementation
To start working with messages, you must pick a broker (the infrastructure part), just like when choosing a database. You publish messages to the broker, which asynchronously pushes them to all subscribers. In this post, I’m going to use Redis.
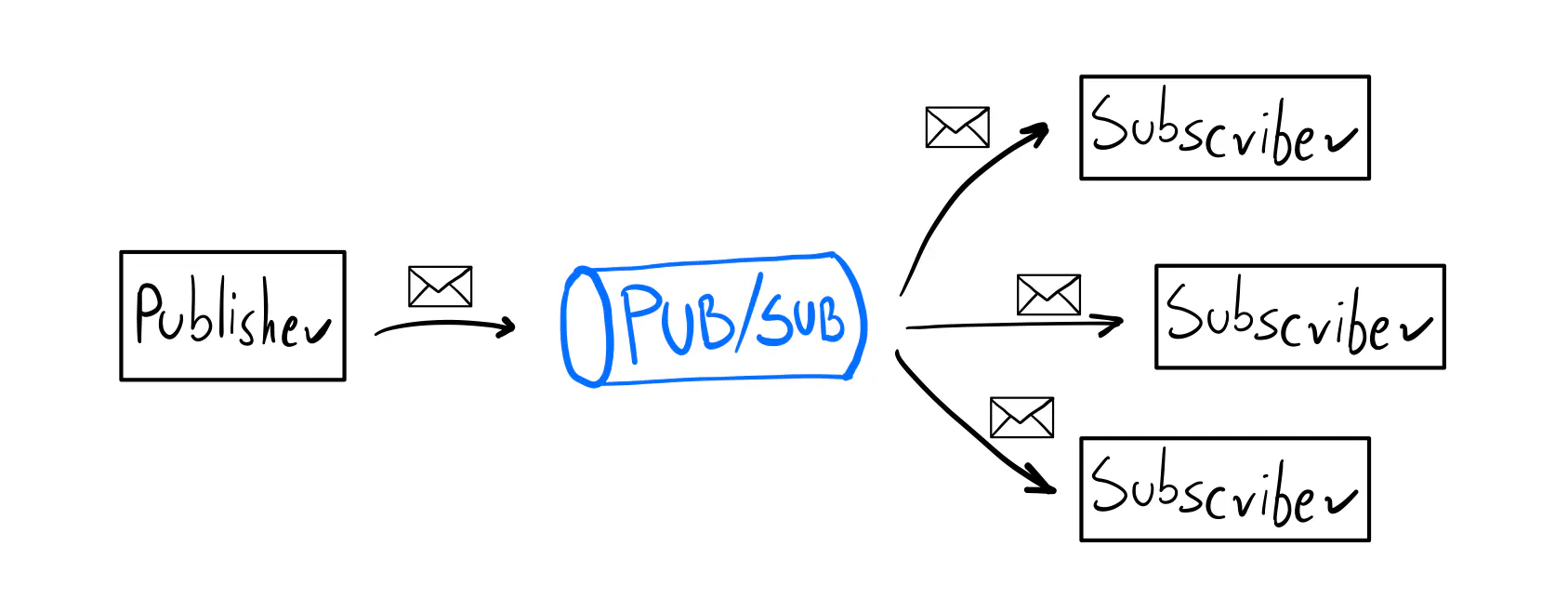
Most popular brokers (Pub/Subs) have a Go library (SDK) that lets you interact with it.
But they usually offer a low-level API.
As much as I like Go’s net/http, I still prefer using Echo or Chi for their high-level API. Similarly, I will use Watermill to work with messages.
Watermill is a Go library we maintain. I won’t explain how it works here in detail. See the Getting Started page for an overview. It supports many Pub/Sub backends, like Kafka, AMQP, NATS, or Redis.
Note
All the ideas below are universal and can be implemented with any other messaging library.
Watermill is not a framework, so it's easy to add or remove from a project. It's one of the core design ideas.
You can see that I won't include Watermill-specific code in the logic layer.
Feel free to use anything else if it fits your needs better.
We’ll use the pair of EventBus and EventProcessor components from Watermill’s cqrs package.
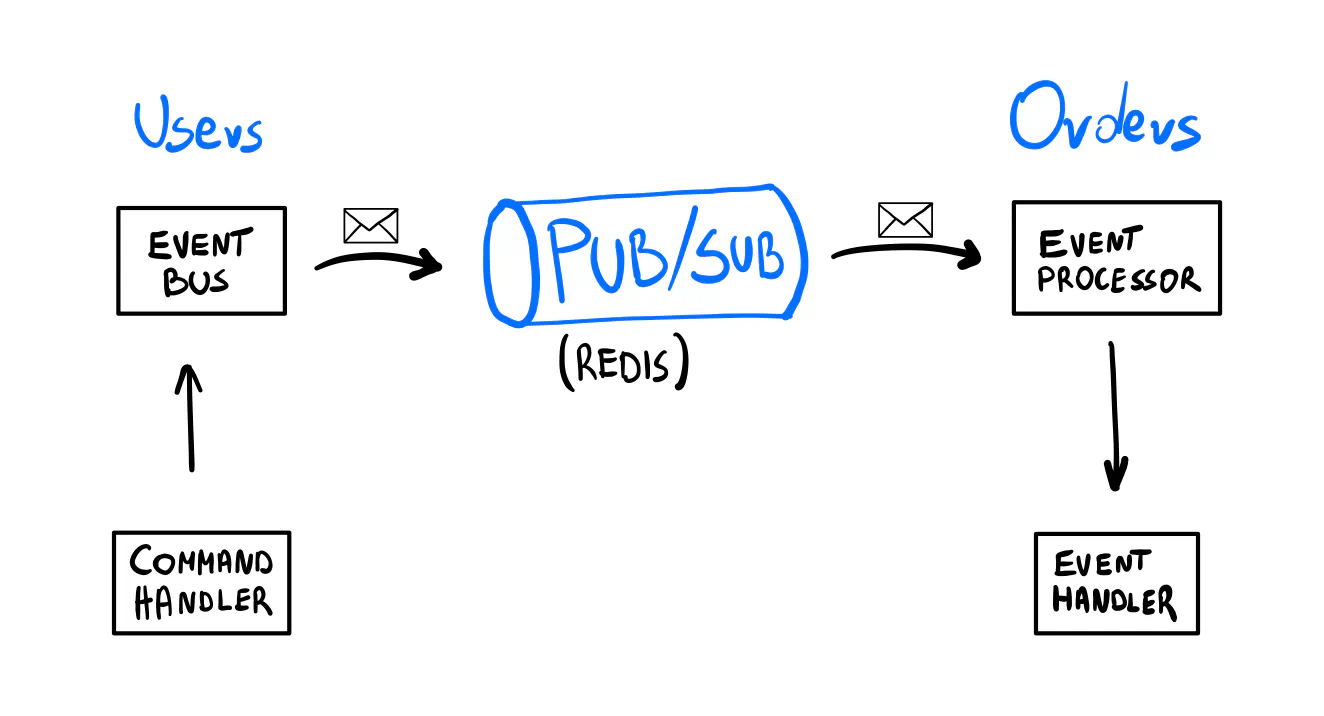
First, let’s replace the HTTP call with publishing an event. The event bus lets us publish messages with a JSON payload. The setup should be easy to grasp even if you don’t know Watermill yet.
client := redis.NewClient(&redis.Options{
Addr: redisAddr,
})
logger := watermill.NewStdLogger(false, false)
publisher, err := redisstream.NewPublisher(
redisstream.PublisherConfig{
Client: client,
},
logger,
)
if err != nil {
return nil, err
}
eventBus, err := cqrs.NewEventBusWithConfig(publisher, cqrs.EventBusConfig{
GeneratePublishTopic: func(params cqrs.GenerateEventPublishTopicParams) (string, error) {
return params.EventName, nil
},
Marshaler: cqrs.JSONMarshaler{},
Logger: logger,
})
We create a Redis publisher and an EventBus. It’s going to use the event’s name as a topic. (A topic is what you subscribe to to receive messages.) It’s going to marshal events into JSON.
In the command handler, we replace the synchronous call with publishing an event.
type EventPublisher interface {
Publish(ctx context.Context, event any) error
}
type PointsUsedForDiscount struct {
UserID int `json:"user_id"`
Points int `json:"points"`
}
func (h UsePointsAsDiscountHandler) Handle(ctx context.Context, cmd UsePointsAsDiscount) error {
err := h.userRepository.UpdateByID(ctx, cmd.UserID, func(user *User) (bool, error) {
err := user.UsePoints(cmd.Points)
if err != nil {
return false, err
}
return true, nil
})
if err != nil {
return fmt.Errorf("could not update user: %w", err)
}
event := PointsUsedForDiscount{
UserID: cmd.UserID,
Points: cmd.Points,
}
err = h.eventPublisher.Publish(ctx, event)
if err != nil {
return fmt.Errorf("could not publish event: %w", err)
}
return nil
}
In the orders service, we replace the HTTP handler with an event handler.
Let’s set up an EventProcessor for subscribing, just like we set up the event bus for publishing.
client := redis.NewClient(&redis.Options{
Addr: redisAddr,
})
logger := watermill.NewStdLogger(false, false)
router := message.NewDefaultRouter(logger)
eventProcessor, err := cqrs.NewEventProcessorWithConfig(router, cqrs.EventProcessorConfig{
GenerateSubscribeTopic: func(params cqrs.EventProcessorGenerateSubscribeTopicParams) (string, error) {
return params.EventName, nil
},
SubscriberConstructor: func(params cqrs.EventProcessorSubscriberConstructorParams) (message.Subscriber, error) {
return redisstream.NewSubscriber(
redisstream.SubscriberConfig{
Client: client,
ConsumerGroup: "orders-svc",
},
logger,
)
},
Marshaler: cqrs.JSONMarshaler{},
Logger: logger,
})
The setup is almost identical to the publishing side. The main difference is that we provide a constructor instead of a single subscriber. I won’t dive into the reasons, as they are irrelevant to what we want to do. To receive messages correctly, we must use the same marshaler and topic configuration as in the event bus config.
Next, we need an event handler. It simply maps the event payload to the command and executes it, just like the HTTP handler did.
type OnPointsUsedForDiscountHandler struct {
addDiscountHandler AddDiscountHandler
}
func (h OnPointsUsedForDiscountHandler) Handle(ctx context.Context, event *PointsUsedForDiscount) error {
cmd := AddDiscount{
UserID: event.UserID,
Discount: event.Points,
}
return h.addDiscountHandler.Handle(ctx, cmd)
}
We add it to the event processor.
err = eventProcessor.AddHandlers(
cqrs.NewEventHandler(
"OnPointsUsedForDiscountHandler",
onPointsUsedForDiscountHandler.Handle,
),
)
The behavior is exactly the same as that of the HTTP endpoint. The message is just another transport, and the handler is another entry point to the application. The main difference is that it’s asynchronous, so no client waits for it to complete.
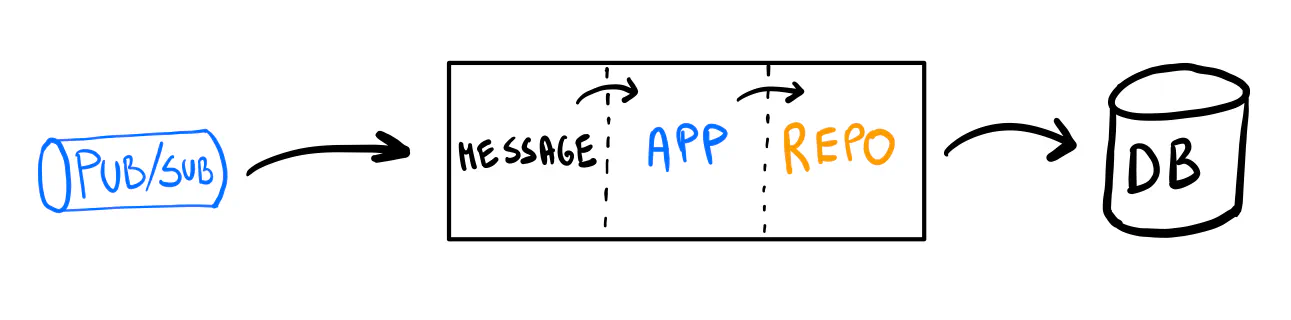
That’s it! With a few changes, we replaced the synchronous HTTP call with a message handler.
Of course, there’s the hard part of running a production-grade Pub/Sub. I used Redis, but you can pick what you feel comfortable with or what your cloud provider offers. You can even start with an SQL database if you don’t want to set up new infrastructure.
 Are you experienced engineer who wants to learn Go basics?
Are you experienced engineer who wants to learn Go basics?You don't become an engineer by watching videos.
Learn Go hands-on by building real projects.
The Outbox Pattern
There’s still one scenario when things can go wrong. Since publishing the message works over the network, it can fail, just like the HTTP call to another service. Pub/Subs are usually highly available, but issues still happen (never assume the network is reliable!). We could lose the messages after the transaction is committed.
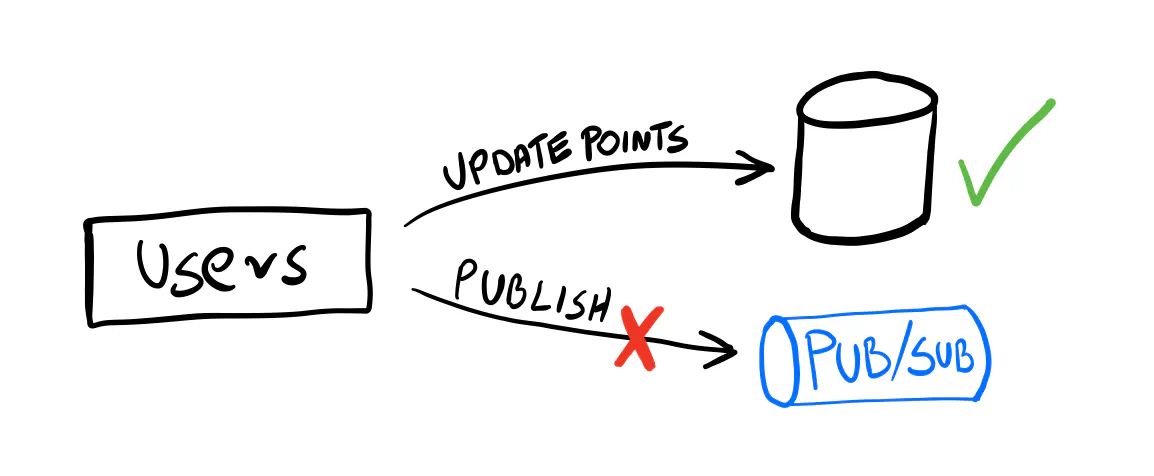
It’s one of the most common mistakes we’ve seen: ignoring this scenario with the hope it will never happen. It’s unlikely, sure, but you don’t want to take this risk. Imagine figuring out what events you lost and manually correcting the system’s state.
We need to store changes in the database and publish the event within the same transaction. Is this possible?
Yes, we can use the outbox pattern. The idea is to save the event in the same database as the regular data within the same transaction. Then, we asynchronously publish it to the Pub/Sub. This way, the event and the stored data will always be consistent, and we will not rely on the Pub/Sub to be around. The events can be simply stored in a dedicated SQL table.
The main challenge is waiting for new events and moving them to the Pub/Sub. Depending on the database, you can use some custom software, although configuring it is often quite complex. You can implement it from scratch, but it’s not trivial.
In this example, I’ll use Watermill’s Forwarder component to achieve this. Its behavior is straightforward, thanks to the heavy lifting done by the Pub/Sub implementation. It listens to messages from the given Pub/Sub and publishes them to another Pub/Sub.
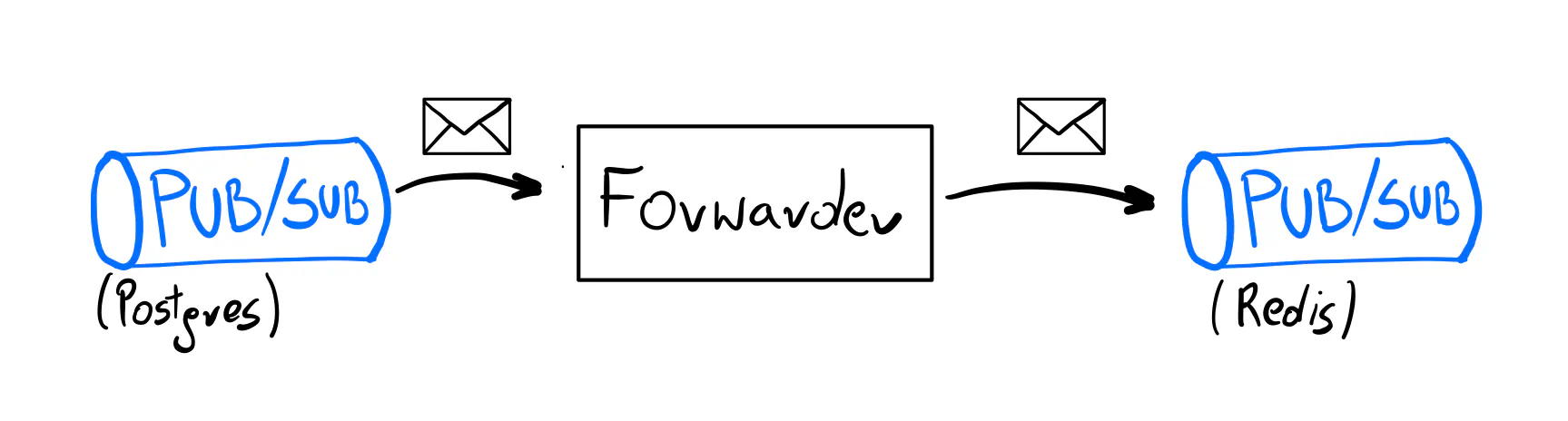
Watermill supports Postgres as one of the Pub/Sub implementations, so adding it to the existing setup is easy. (Yes, you can simply use an SQL database as your messaging infrastructure.)
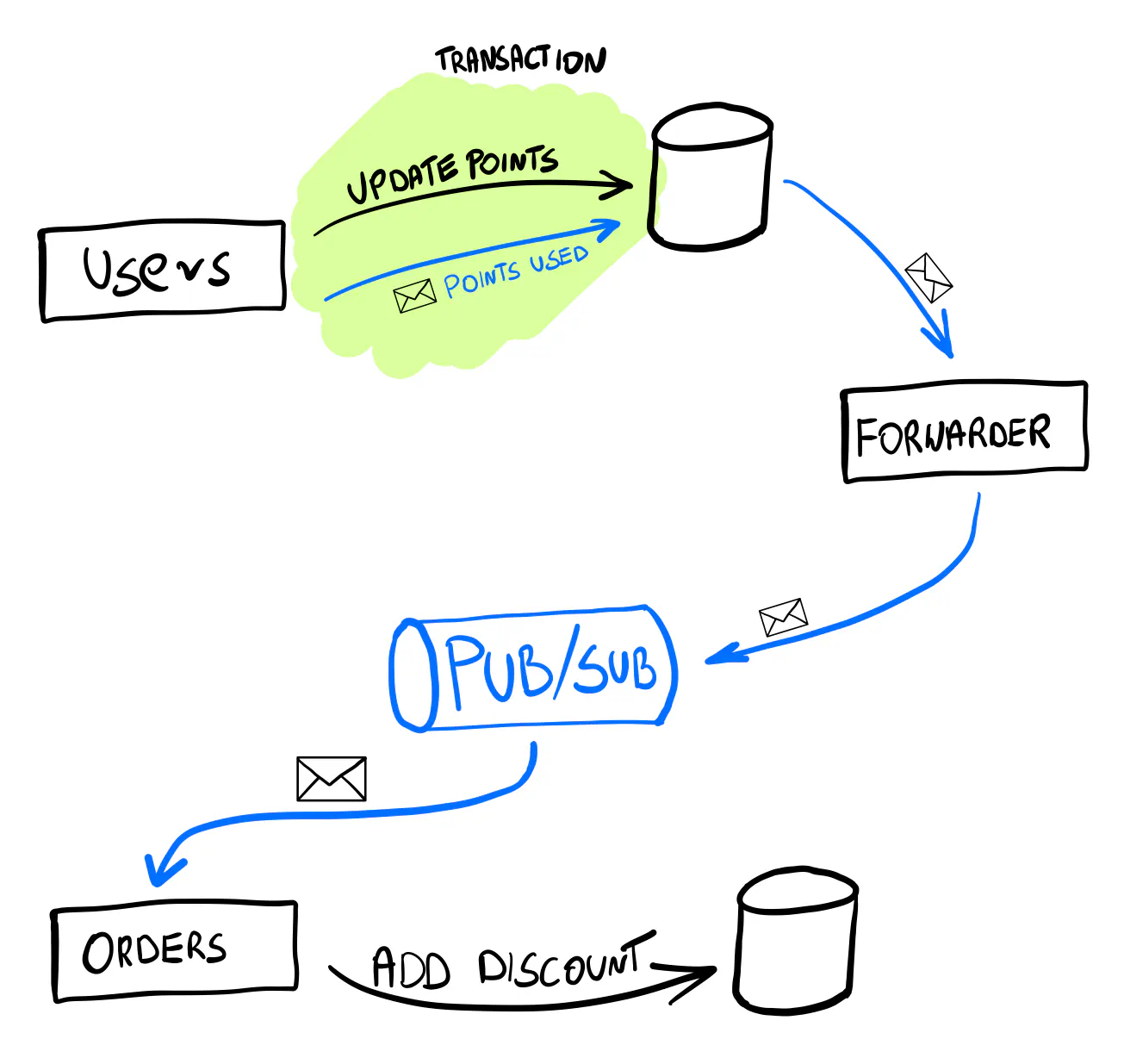
We face another design dilemma. How can the publisher and repository work together without mixing the logic and the database code?
We’ll extend the UpdateFn function so it decides what events should be published.
(For more on how this pattern works, see the post on database transactions.)
func (h UsePointsAsDiscountHandler) Handle(ctx context.Context, cmd UsePointsAsDiscount) error {
return h.userRepository.UpdateByID(ctx, cmd.UserID, func(user *User) (bool, []any, error) {
err := user.UsePoints(cmd.Points)
if err != nil {
return false, nil, err
}
event := PointsUsedForDiscount{
UserID: cmd.UserID,
Points: cmd.Points,
}
return true, []any{event}, nil
})
}
The repository publishes the returned events.
updated, events, err := updateFn(user)
if err != nil {
return err
}
if !updated {
return nil
}
_, err = tx.ExecContext(ctx, "UPDATE users SET email = $1, points = $2 WHERE id = $3", user.Email(), user.Points(), user.ID())
if err != nil {
return err
}
eventBus, err := NewWatermillEventBus(tx)
if err != nil {
return err
}
for _, event := range events {
err = eventBus.Publish(ctx, event)
if err != nil {
return err
}
}
Note how a new event bus is created using the tx variable.
This is how we ensure publishing happens within the same transaction.
We must amend how the event bus is created in the users service.
We will no longer publish directly to Redis.
We need to change the original publisher from Redis to Postgres.
publisher, err = watermillSQL.NewPublisher(
db,
watermillSQL.PublisherConfig{
SchemaAdapter: watermillSQL.DefaultPostgreSQLSchema{},
},
logger,
)
Next, we wrap this publisher with the forwarder’s Publisher.
It introduces an envelope around the message so the forwarder knows how to handle it. Its config is minimal.
publisher = forwarder.NewPublisher(
publisher,
forwarder.PublisherConfig{
ForwarderTopic: forwarderTopic,
},
)
The last part is running the forwarder.
While it could be a standalone service, keeping it running as another goroutine within the users service is also fine.
We need an SQL subscriber to receive the stored events from the database,
and a Redis publisher to publish the messages where the orders service expects them.
sqlSubscriber, err := watermillSQL.NewSubscriber(
db,
watermillSQL.SubscriberConfig{
SchemaAdapter: watermillSQL.DefaultPostgreSQLSchema{},
OffsetsAdapter: watermillSQL.DefaultPostgreSQLOffsetsAdapter{},
InitializeSchema: true,
},
logger,
)
if err != nil {
return nil, err
}
client := redis.NewClient(&redis.Options{
Addr: redisAddr,
})
redisPublisher, err := redisstream.NewPublisher(
redisstream.PublisherConfig{
Client: client,
},
logger,
)
if err != nil {
return nil, err
}
fwd, err := forwarder.NewForwarder(
sqlSubscriber,
redisPublisher,
logger,
forwarder.Config{
ForwarderTopic: forwarderTopic,
},
)
Note that the forwarder topic needs to match between the forwarder publisher and the forwarder itself.
In this case, it’s the same forwarderTopic constant (can be any string).
Finally, we run the forwarder.
go func() {
err := forwarder.Run(context.Background())
if err != nil {
panic(err)
}
}()
No changes are necessary on the orders service side.
As far as it’s concerned, it receives events from Redis, as it used to.
✅ Tactic: The Outbox Pattern
Use the Outbox pattern to publish events within a database transaction. Don’t leave it to chance whether all events will be successfully published.
Simplifying or Complicating?
There are many moving parts here. Event-driven patterns are not trivial, and you need to understand what you’re doing to some degree. If you never used these concepts before, it can seem complex.
I used to have these concerns as well. The system seems simpler with just the synchronous APIs and a database. Why complicate it with adding all this background processing?
As counterintuitive as it is, you can simplify your distributed system using these ideas. Because you work with facts that happened (events), you don’t need to consider rollbacks, which terribly complicate your flow.
A rollback can interfere with other flows, so you need distributed locks to protect the state. Rollbacks can also fail. What do you do when this happens?
As the snippets show, little code is needed to start working with events, and the handlers are also straightforward. This is where Watermill helps by removing the low-level boilerplate. You can focus on setting up the handlers and publishing messages with an API that’s easier to use than HTTP endpoints.
Once you grasp the basics, your mental model will start changing, and eventually, it will click. You’ll get the intuition on how to design event-driven systems.
Events & Coupling
Make no mistake, events are still a form of a contract. The fact you use them doesn’t magically make your services decoupled. Incorrectly designed events are another trap you can fall into.
What I like about the pattern is that it limits what the services know about each other. But it’s easy to fail at this.
The example above shows that the event is designed quite poorly.
The UsePointsAsDiscount name makes the users service aware of what happens in the orders service after it receives it.
It’s too late to escape this now, though.
The service boundaries are just wrong from the beginning.
Well-designed events state a fact that happened in this service’s domain. The service publishing the event should not know or care what happens when another service consumes it.
Testing
Testing event-driven services is not much different, but here are some tips.
Run your Pub/Sub locally in a Docker container and test against it. Cloud-based Pub/Subs usually offer an emulator (but often with no feature parity, so watch out).
Testing the event handler code makes little sense. Event handlers should just execute your application logic with the data from the event. Instead, use component tests to test the behavior of the service using the public API.
A test scenario can be something like:
- Once this event is published, an entity read over HTTP should change.
- Once this HTTP endpoint is called, an event should be published.
- Once this event is published, another event should be published.
If you use testify, the Eventually and EventuallyWithT functions are helpful.
(The second one allows using asserts inside).
They run the assert code periodically until it’s successful or until it times out.
Use these instead of plain sleeps, as they slow down your tests.
assert.EventuallyWithT(t, func(t *assert.CollectT) {
row := discountDB.QueryRowContext(context.Background(), "SELECT next_order_discount FROM user_discounts WHERE user_id = $1", userID)
var discount int
err := row.Scan(&discount)
require.NoError(t, err)
assert.Equal(t, expectedDiscount, discount)
}, 2*time.Second, 100*time.Millisecond)
When reading events, watch out for others that may interfere. With many tests running in parallel, it’s common to have many events of the same type published. You need to filter them based on the ID or some metadata. Using UUIDs for this is best so your tests are completely independent.
Finally, run your tests in parallel to speed them up. With lots of time spent on I/O and waiting, this quickly adds up. There are some quirks to running Go tests in parallel, though. Robert is currently working on an article on how to do it right — join our newsletter, and we’ll let you know once it’s ready.
Monitoring
Observability is a long topic, and there’s much to be said about metrics and tracing for event-driven systems. This is beyond the scope of this post, but I want to mention monitoring the queue of waiting messages.
If a message fails to be processed (i.e., the handler returns an error for whatever reason), it will be delivered again. Depending on the Pub/Sub you picked and its configuration, it can block other messages from being delivered.
This is your key metric to monitor. Having unprocessed messages for a long time usually means something went wrong, and it’s not a temporary issue. You need manual intervention, or your system will be out of sync.
More Examples
This scratches the surface of switching to eventual consistency, but it should be enough to get you started. To learn about different use cases, check Watermill examples. There are some basic ones, but also more advanced and interesting examples.
As with most programming topics, reading about something is rarely enough to fully get it. For me, building something on my own is what makes me fully understand it. But it’s often hard to come up with an idea for a project to build. We wanted to recreate this way of learning, so we designed a hands-on event-driven training. Consider joining us if you like learning like this.



