Iteration #1: "Go Faster"

We registered Three Dots Labs as a company in 2014, hoping to quit our jobs soon to work on our products. The “soon” turned into ten years of launching side projects and working evenings and weekends. We finally decided to take the leap last year, and we plan to share how it’s going. If you’re in a similar spot, you may find it helpful.
By the end of 2024, we spent some time planning the next year and our approach to work. We reviewed our backlog and discussed what we wanted to do next. We’ll experiment with 11-week iterations, with a week off in between. It’s not like the usual sprint — it’s more a way to stay focused during this time.
We’ve just wrapped up the first iteration, and you’ll find the summary of it below. Our main goal was to get ready for the next iterations. There were many things we wanted to wrap up before starting new projects. We also gave ourselves time to chill a bit after working two full-time jobs for a long time.
The main theme was “go faster”, so it’s mostly housekeeping stuff. We decided it’s important to do it now because there are just two of us, and we can’t afford to waste time during development. Our ultimate goal is to create a place where we love to work, and frustrating things like slow CI or a messy codebase are real motivation killers.
What we do now falls roughly into three categories:
- Academy (our learning platform).
- Watermill (our open-source library).
- Content (blog posts, podcast, etc.).
Academy
We had an idea for hands-on programming training a few years ago, but we weren’t sure if people would enjoy learning like this. We created an MVP to see if it’s technically possible. Go in One Evening was the first training we created.
The project started as a scraped-together prototype that we iterated on to improve the UX. When it gained traction, we built more features and created another, much bigger training. We did all this while still working full-time, so we struggled to find time and never bothered to refactor the project. We ended up with quite a low-quality codebase that made the most money out of all our products. (I used to half-joke that if the codebase ever leaked, our reputation would be over.)
If you ever worked on a professional project, you know it’s an extremely common scenario. There are projects with great technical quality that no one uses, and they die. And there are terrible big balls of mud that make millions. But having technical debt is fine if you take time to clean up some of the mess.
For us, it’s an interesting place to be in. When you work as a developer, it’s easy to complain about not having enough time to do things right, while the business needs to move fast and make money. Now, we feel both pressures at the same time. We need to move the product forward but don’t want to get stuck working with a messy codebase. The frustration quickly adds up.
We finally have time for things like this, so we focused on them during the last few months.
Moving to a monorepo and updating the CI
Our CI got slow and fragile over time, and as you may know, it’s one of the most frustrating things to have around when working on a project. It’s also your main feedback loop when committing code. You waste precious time if you have to wait or fight to make the CI pass.
While cleaning it up, we also decided to move to a monorepo, which makes sense when only the two of us are working on it. We ended up with one repository that keeps all of our active projects (including this blog) and a set of GitHub Actions that run only when the relevant project changes.
It went smoothly, apart from the regular experience of testing the CI (commit, push, wait, read the error, repeat). It also improved the developer experience right away.
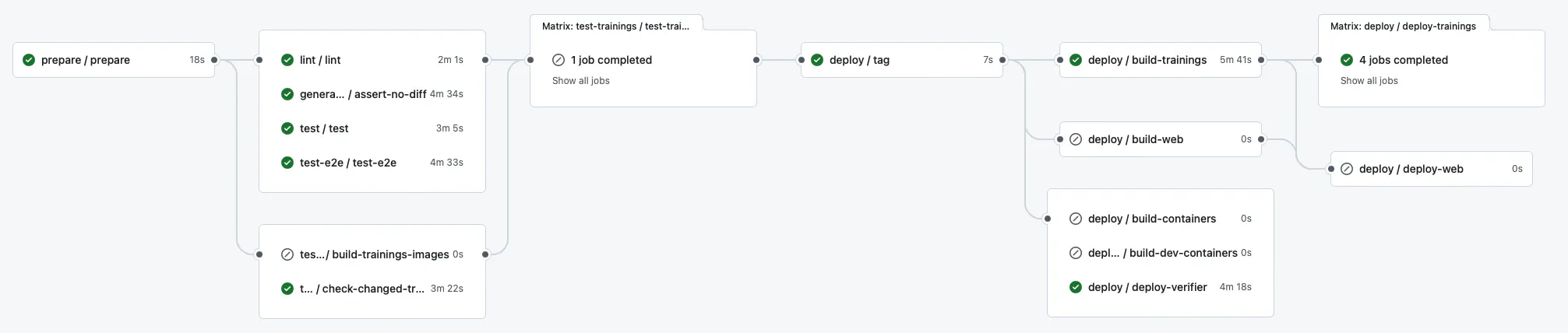
As you can see, the test times could still be improved. That’s mainly because of the cache and dependencies.
The best part is that we can now deploy just what has changed. For example, changing something on the website won’t deploy the backend, and vice versa.
Migrating out of Firestore
We started Academy with Firestore as the database. It’s easy to start a project with it, as there’s no need to set up any infrastructure. It was also about 10x cheaper for our use case than hosted SQL.
But working with the document model is far from ideal for typical web applications. You can’t just run a quick SQL query to get the data you need among all collections. Migrations are painful, as you must write code to transform the data. And the emulator used in the local environment often has its own issues.
So, we decided to migrate to Postgres.
Do you know how useful it is to hide your storage code behind an interface in case you want to change the database? We promote it a lot, but we didn’t care that much for the MVP. Some people claim you never change the database, so it’s not an argument for using interfaces. But we had to deal with this exact use case.
First, I changed the code to use the clean architecture pattern. Thanks to this, I could test both implementations with the same tests, and changing between databases was a single config change. It’s super helpful to be able to quickly roll back a risky change like this. It also helped to clean up the code from a few hacky patterns we used in the MVP.
Still, the change wasn’t as easy as just replacing the implementations. Migrations are always more complex than they seem. I spent about two weeks finishing everything. The refactoring alone took a few days. Then, I had to set up the infrastructure, write the migration script, run tests, and debug issues. We also keep two regions of the platform (EU and US), so it was another factor to consider.
It’s a good example of a tough refactoring decision since this change did not improve the product in any way. In this case, we agreed it’s worth it for the long-term benefits. Small issues add up over time, especially if it’s something as critical for the project as the database.
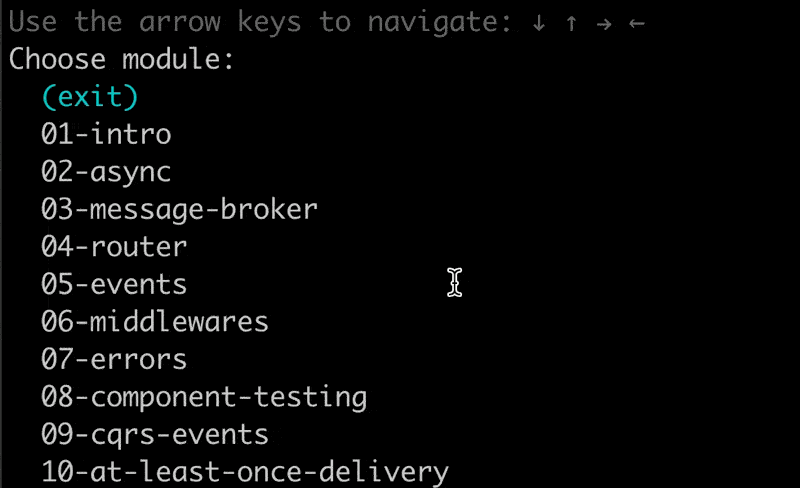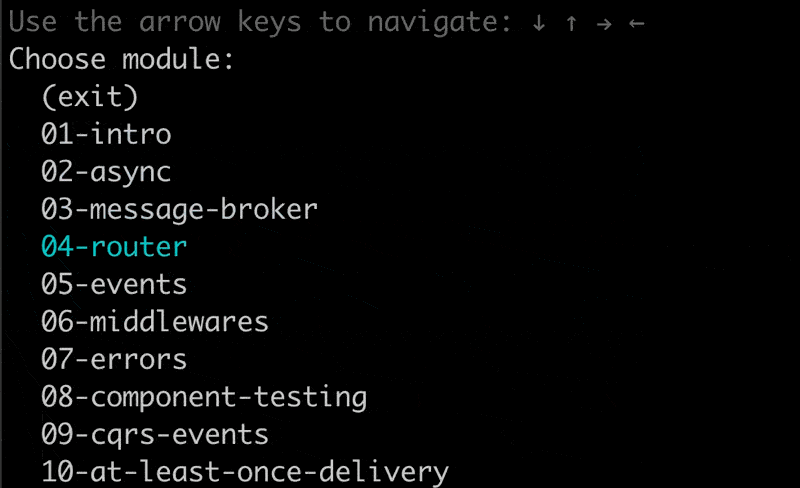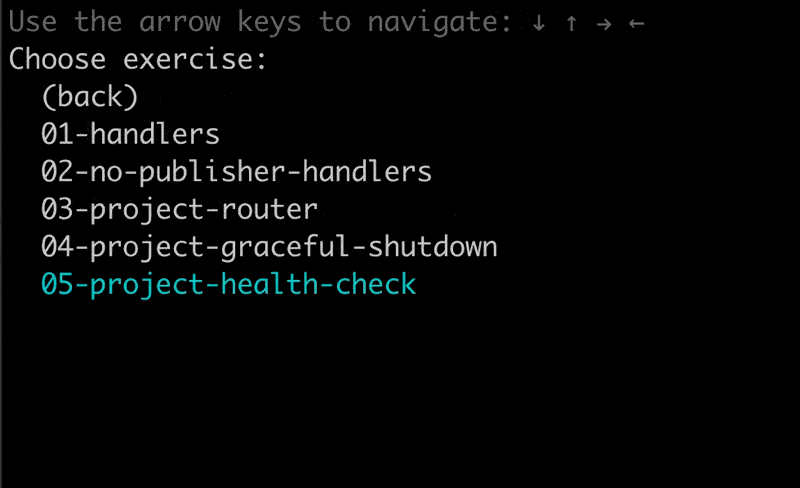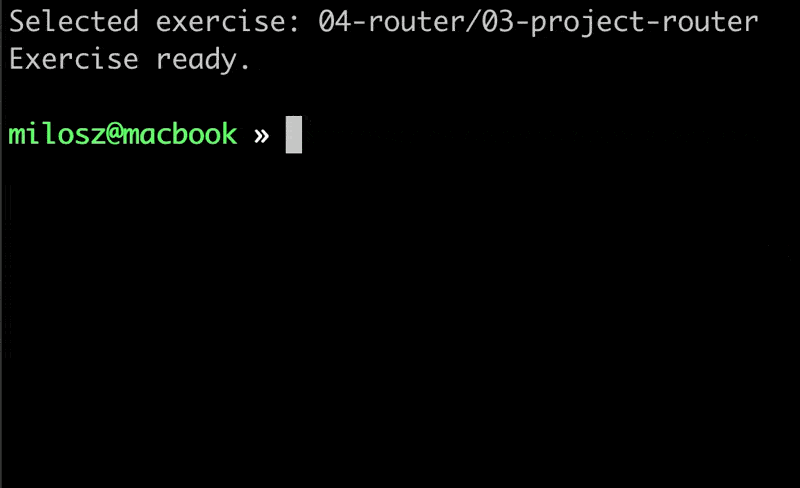
Jumping around the exercises in the CLI
We added a minor but often requested feature to our tdl CLI tool.
You can now jump to another exercise you completed before.
Watermill
Watermill is our open-source Go library for building event-driven applications. We released Watermill 1.4 last autumn but didn’t wrap up everything we wanted to.
A few PRs needed our attention, like #25 in watermill-kafka. Often, a PR looks like a trivial change, but then it turns out to be a rabbit hole. In this case, we had to adjust the tests to make the changes work, which was a solid day of Robert’s work.
Another example of tough dilemmas is the issue #402. We often don’t foresee all use cases when adding a new feature. Then, we must decide whether to keep the current behavior, even if it’s incorrect, or change it and potentially break someone’s code. Together with the fix, Robert updated the CQRS examples to show the best way to use the component.
We deprecated the gogo/proto marshaler and introduced a new one, cqrs.ProtoMarshaler.
It was long overdue, as gogo/proto has been deprecated for a long time.
Finally, watermill-sql v4 is still a release candidate. New issues are coming in, and I’ve been struggling to stabilize the tests with the recent changes.
Maintaining an open-source project often feels like a full-time job, and we can’t spend all our time like this. At the same time, we want Watermill to stay independent of external sponsors so no one tries to monetize it, which would probably push it towards a vendor lock-in approach.
On the other hand, it has a nice synergy with our Go Event-Driven training, so we have a good reason and motivation to keep improving it. We’ll try to find a reasonable balance here. As always, big shoutout to all contributors who help us push the project forward.
Content
On our blog, it was a relatively quiet end of the year. I released The Over-Engineering Pendulum, a less technical post about my experience with over-engineering in startups. We want to share more on similar topics in the future.
Last year, we ran a couple of Watermill release parties and live Q&A sessions for Go Event-Driven trainees. We liked the format, and we wanted to experiment with it more. During this iteration, we started preparing to launch our live podcast, No Silver Bullet. You can read more on it in Robert’s post.
We have a long list of topics for the blog and the podcast. After long sessions of sorting them, we ended up with close to 150 items.
Changing the Newsletter Platform
Our newsletter is the primary way to communicate with our readers and also how we sell our trainings. We’ve been using ConvertKit to send emails, and it worked quite well, but the automation workflows were a huge pain to work with. We had to do some nasty workarounds to make sure the ebooks were delivered reliably to newsletter subscribers. The product wasn’t improving, so we moved out to avoid spending more time on it.
This wasn’t the first migration we made. A few years ago, we moved off MailChimp for similar reasons. This time, we moved to MailerLite, which seems to be a better fit for us. It took about two weeks on Robert’s end, but hopefully, it will save us headaches in the future.
Plans for the next iteration
Looking forward, I hope we’re done with migrations for now. 😅
We have a few goals for 2025, but we try to not plan too far ahead. Often, we get a new random idea and want to pursue it right away (that’s how the Academy started).
We want to experiment with the live podcast episodes and see where they lead. Another experiment is adding new features to the Academy backed by LLMs. We have some ideas that should turn out more interesting than the usual “we now use AI chatbot as customer support” stories. Our main goal is to help people move through the training more smoothly.
We definitely want to release another training in the coming months. We don’t fully know the scope yet — we’ll ask our newsletter subscribers for feedback soon.
Another goal is finishing Go with the Domain, and releasing a revised edition. It’s probably what we get asked for the most, but we’re not sure about any dates yet.
Thanks for reading! I hope to see you live during one of the No Silver Bullet episodes and on the Iteration #2 summary.


