The Over-Engineering Pendulum

I used to picture my dream job as this: I work for an early-stage startup that recently raised a round. The business idea is promising, there’s much to build, everything seems possible, and we have time to prove the product-market fit. I join as the first engineer, lay the foundations, and pick the tech stack.
Can you imagine a better gig? Finally, you get to do things your way. No more arguing and no old code dragging you down. This time, the project will have a high-quality codebase and no technical debt. Starting from scratch feels great — I’m excited just thinking about it.
In the end, I joined early-stage startups after someone else had laid the groundwork. The upside was that I could see the mistakes from a safe distance instead of making them myself. I ended up rethinking and refactoring existing codebases more than bootstrapping them.
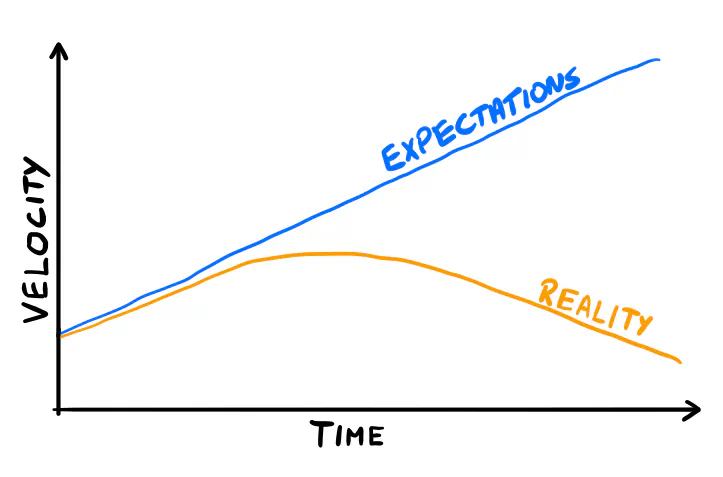
After a few rounds of this and hearing startup stories from friends, I was shocked at how similar startups are. (I love the irony — they try to become unicorns, after all.) One common issue stood out: Product teams often struggle due to the mess caused by over-engineering in the early days.
Once the team grows, it suddenly takes ages to deliver what was trivial before. Eventually, someone asks: “Why does it take so long?” The engineers are surprised and frustrated. It can’t be the codebase — it follows the best industry standards.
It’s extremely difficult for founders to notice this before it’s too late. Often, it’s a surprise even to the technical leaders.
How Over-Engineering Starts
You’ve probably seen over-engineering before. It’s a two-person team using ten microservices and obsessing over tiny performance tweaks where they don’t matter. Or adopting the popular but unstable technology and going big on infrastructure when a single VM would be good enough. Or reinventing solved problems and implementing them from scratch.
It’s fun to build complex systems and imagine that technology gives you the edge. But it’s rarely true — most software is boring. Only small parts of what you create are unique.
Still, there are reasons to think big. The founders have a grand vision for the technology, and they make it clear: We need to build for scale. We’re creating an operating system to disrupt our industry. We have to write the core software now to simply add features later.
Perhaps this leads to overthinking what has already been solved for years. If you’re building the next unicorn, why use one database running on one server? It doesn’t make you unique among other wannabes. If you aim for the stars, better design something that supports this imaginary future.
But you also need to deliver and validate quickly at this stage. You must keep the momentum as you build the product over time, so you fear getting lost in a messy codebase. You feel pressure to keep the standards high.
It’s tempting to over-engineer in the hope of avoiding this mess, but it only makes it worse. It takes the time that you could spend on actually helpful essentials. Who cares if you implemented a service mesh if your CI pipeline isn’t green? Do you need that custom framework if the local environment is awful to work with? How will horizontal scaling save you from unmaintainable code?
High Quality
Your challenge is finding the balance between over-engineering and building a messy prototype. It’s somewhere between moving fast and doing things right.
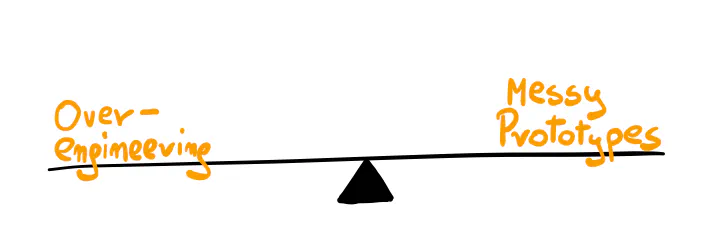
We tend to see speed and high quality as opposites. You need to be fast to stay alive. But what does quality even mean?
Engineers have strong opinions and vague ideas about quality. Some understand it as “I don’t like this code. It should use another design pattern.” They are religious about formatting. They moan, “Give us time to refactor.” It’s a naive take, far from product engineering. It uses quality as an excuse to boost the ego. Code shouldn’t be the end goal.
Another take is thinking of quality as flexibility. Building systems that are easy to extend and configure feels rewarding. It’s cool if you want to solve code puzzles for fun. But if you want to deliver working software, you need some constraints. Focus on what’s in front of you. Use a proven, boring tech stack. Stay away from creative or dynamic solutions. If you’re getting excited about building something universal to solve issues in the future, check if you could simplify it into something you can use now.
You likely won’t need to scale anytime soon. But if you invest in the basics, they will serve you well once you need to do it.
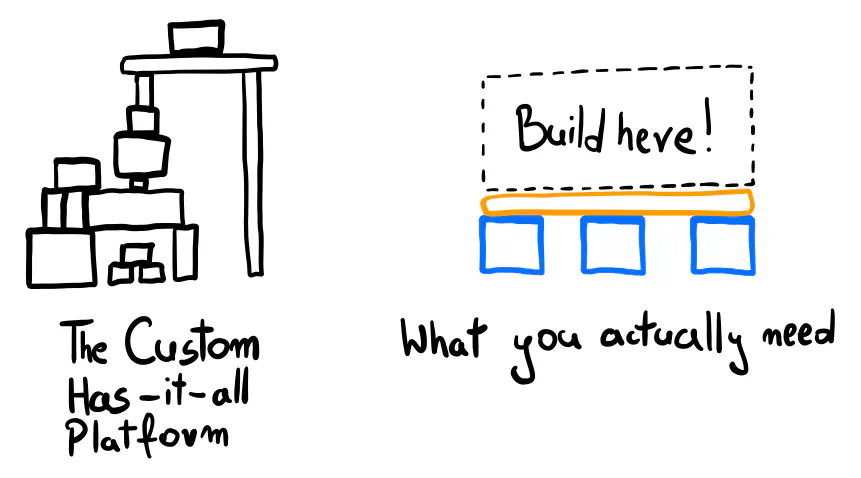
The Essentials
In the early days, I like to focus on the developer experience. Instead of creating a framework or platform that supports all possible use cases, I prefer to prepare a great environment for engineers to work in.
There’s much to build when starting from scratch, and new work quickly piles up. Good foundations limit time wasted on non-product things. They help you iterate quickly, which has real value compared to refactoring for code prettiness.
Above all else, frustration is the worst productivity killer. It can radically change an engineer’s mindset from “it doesn’t feel like work” to “it’s the last thing I want to do.”
My first essential pick is an automated build system (a CI/CD pipeline) that runs tests and static analysis, builds the project and deploys it to production — ideally, a modern one that is easy to configure. The same steps run on feature branches, so the main branch is never broken.
It doesn’t have to be complex.
Make it run git pull if that’s what you need.
It’s easy to set up, and the benefits will be there every day for all engineers.
You can’t afford to have deploys blocked by broken changes or
spend time discussing trivial issues a linter could catch.
Next, prepare a great local development environment. It should be easy to set up, work everywhere, and run fast. You should be able to run the CI tools locally with the same versions and results. Use live code reloading so it’s pleasant to work with.
Finally, create guidelines on how to do common things. Think of the building blocks from which you build the application. Assembling elements is easier than creating a universal framework. It lets you keep some standards without trying to predict all future use cases.
It’s more about healthy constraints than doing things right. You don’t want to discuss every week how to write an HTTP handler, call an external API, use database transactions, or run a function periodically. Decide on something and cut the discussions early so you can focus on writing the code that matters.
In any case, watch out for decisions that are hard to reverse. Opinionated frameworks make starting easy, but getting out of them can take long months.
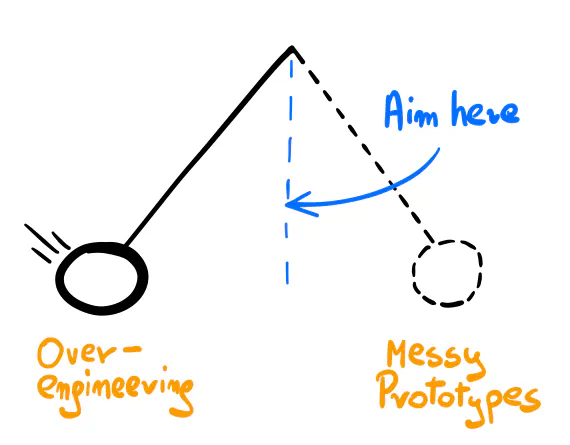
Aim for the Middle
I like the pendulum metaphor: once we go to one extreme and get bitten by the results, we tend to avoid it at all costs and swing the other way. It applies to many things in life, including technology hype cycles.
For example, consider delivering software. A service is a way of deploying code, not an isolation unit. So, use modules for isolation. But be ready to spin up a separate service if needed. Sticking with a massive monolith forever is as extreme as starting with a distributed system. But somehow, we tend to swing from one extreme to the other.
Similarly, once we work with a messy codebase, we start paying extra attention to quality. Then, it’s easy to go too far in the other direction and over-engineer your next project.
I still find it challenging to find this balance. It’s a topic that leads to never-ending discussions with no clear answers. There’s one thing I’m sure helps: If you have seen the extremes, at least you know to aim somewhere in the middle.
Before It’s Too Late
When I hear of teams struggling with messy systems, it strikes me how a simple decision in the past could have prevented it. Once you’re there, migrating out is incredibly difficult. In contrast, building from scratch feels much easier.
I wish we had metrics to track this, but I’m skeptical if that’s possible. For example, achieving high test coverage is easy, but it doesn’t mean your tests do anything meaningful.
One thing I’ve seen work well is regularly shipping small features. The key skill is splitting the work into chunks that make sense by themselves. The naive approach is splitting by artificial boundaries, such as one feature per microservice or separate backend and frontend parts. Instead, aim for changes that are end-to-end complete but small enough to ship quickly.
Watch out for making it a target metric, though. It’ll encourage shortcuts in the code, pulling you towards the messy codebase.
