Common Anti-Patterns in Go Web Applications

At one point in my career, I was no longer excited about the software I was building.
My favorite part of the job were low-level details and complex algorithms. After switching to user-facing applications, they were mostly gone. It seemed programming was about moving data from one place to another using existing libraries and tools. What I’ve learned so far about software wasn’t that useful anymore.
Let’s face it: most web applications don’t solve tough technical challenges. They should correctly model the product and allow improving it faster than the competition.
It seems boring at first, but then you realize supporting this goal is harder than it sounds. There’s an entirely different set of challenges. Even if they’re not as complex in the technical sense, solving them has a massive impact on the product and is deeply satisfying.
The biggest challenge web apps face is not becoming an unmaintainable Big Ball of Mud. It slows you down and can put you out of business.
Here’s why it happens in Go and how I’ve learned to avoid it.
Loose Coupling Is the Key
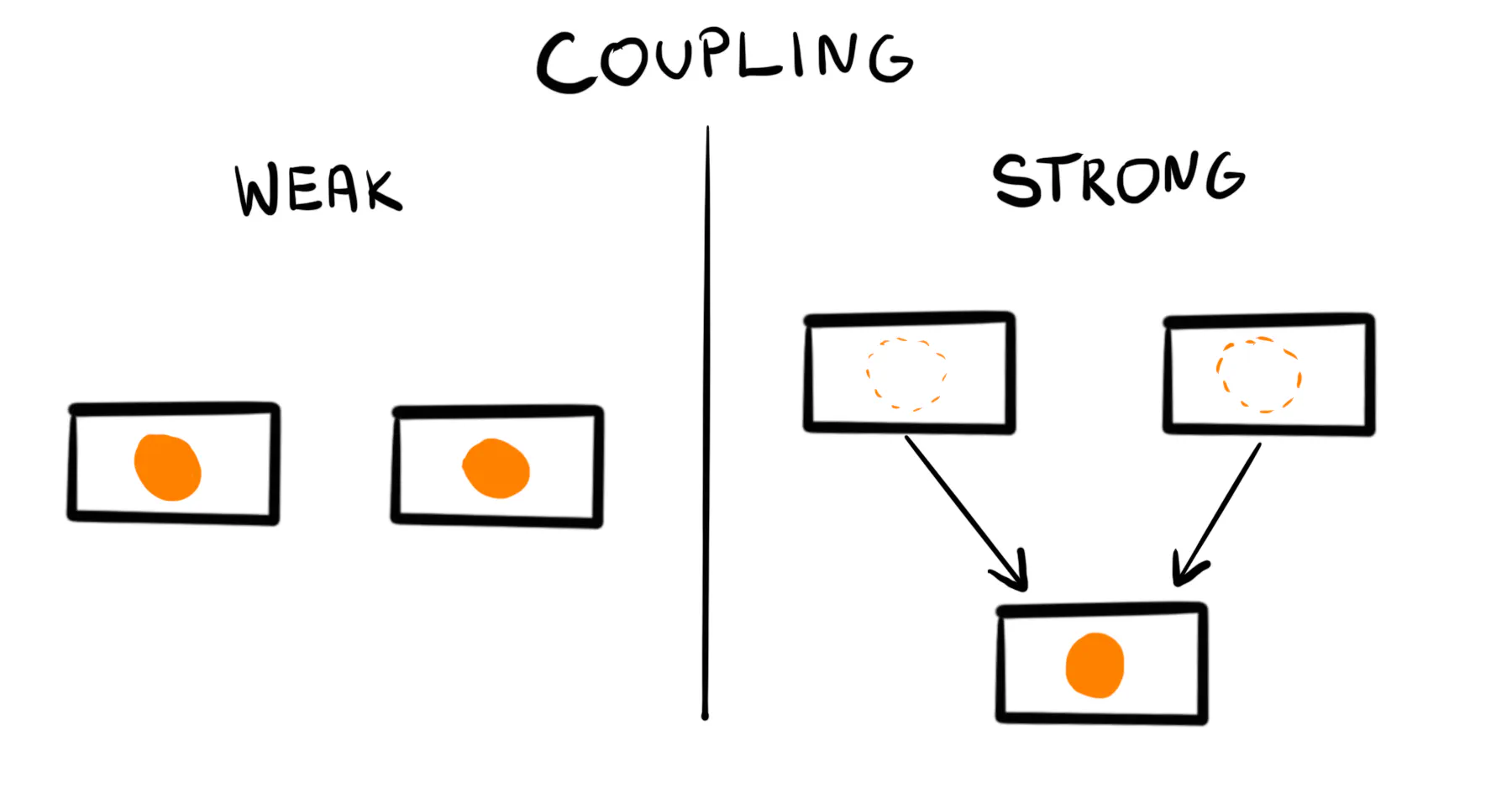
A big reason applications get hard to maintain is strong coupling.
In tightly coupled applications, anything you touch has unexpected side effects. Each refactoring attempt uncovers new issues. Eventually, you decide it’s best to rewrite the project from scratch. In a fast-growing product, you can’t afford to freeze all development to re-do what you’ve built. You have no guarantee you’ll get everything right this time.
In contrast, loosely coupled applications keep clear boundaries. They allow replacing a broken part without effect on the rest of the project. They’re easier to build and maintain. So why are they so rare?
Microservices promised us loose coupling, but we’re after their hype era, and unmaintainable applications still exist. Sometimes it’s even worse, and we fall into the trap of distributed monoliths, dealing with the same issues as before with added network overhead.
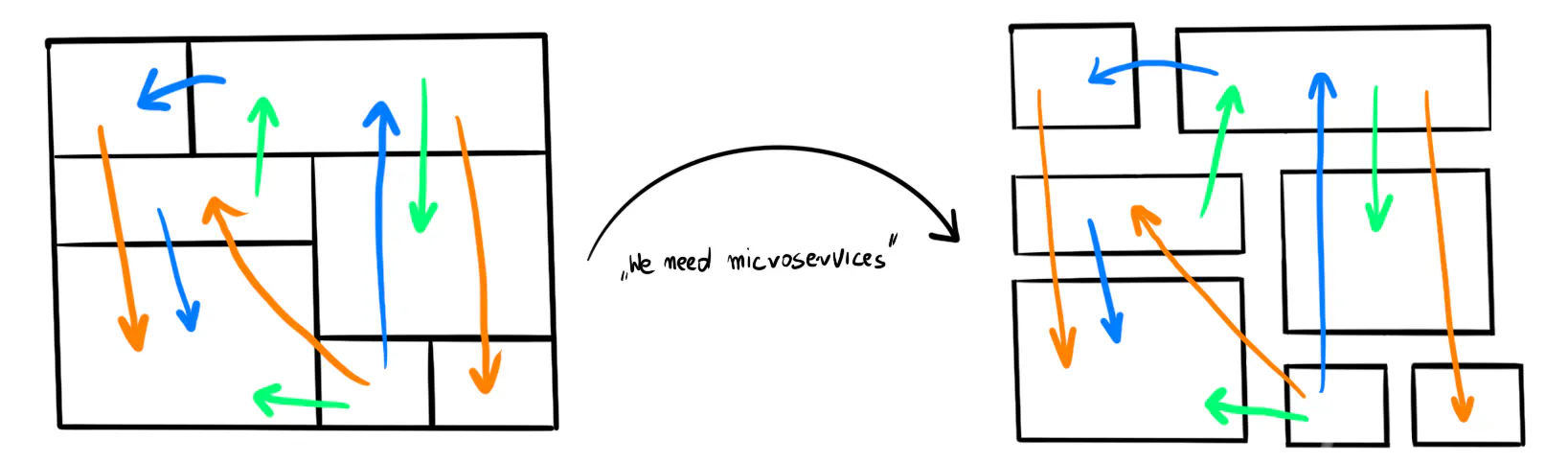
❌ Anti-pattern: The Distributed Monolith
Don’t split your application into microservices before you know the boundaries.
Microservices don’t lower coupling because it’s not important how many times you split the application. What matters is how you connect the pieces.
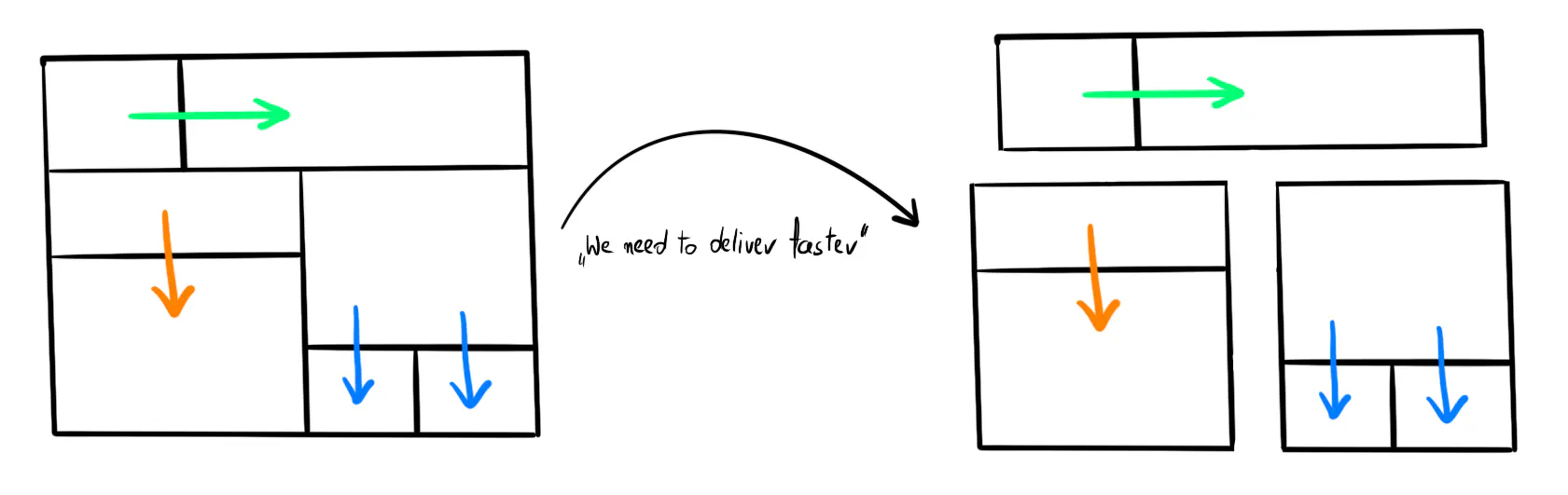
✅ Tactic: Loose Coupling
Aim for loosely coupled modules. How you deploy them (as a modular monolith or microservices) is an implementation detail.
DRY introduces coupling
Strong coupling is common because we’re taught early about the “Don’t Repeat Yourself” (DRY) rule.
Short rules are easy to remember, but it’s hard to capture all the details in three words. The Pragmatic Programmer offers a longer version:
Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.
“Every piece of knowledge” is quite extreme. The answer to most programming dilemmas is “it depends”, and DRY is no different.
When you make two things use a common abstraction, you introduce coupling. If you follow DRY too strictly, you add abstractions before they’re needed.
Being DRY in Go
Compared to other modern languages, Go is explicit and stripped from features. There’s not much syntactic sugar to hide complexity.
We’re used to shortcuts, so at first, it’s hard to accept Go’s verbosity. It’s like we’ve developed an instinct to find “smarter” ways of writing code.
The best example is error handling. If you have any experience writing Go, this snippet feels natural:
if err != nil {
return err
}
For newcomers, repeating these three lines over and over seems like breaking the DRY rule. They often look for a way to avoid this boilerplate, but it never ends well.
Eventually, everyone accepts that’s how Go works. It makes you repeat yourself, but it’s not the duplication DRY tells you to avoid.
A Single Model Couples Your Application
There’s one feature in Go that introduces strong coupling and makes you think you’re following DRY. It’s using multiple tags in a single struct. It seems like a good idea because we often use similar models for different things.
Here’s a popular way of keeping a single User model.
type User struct {
ID int `json:"id" gorm:"autoIncrement primaryKey"`
FirstName string `json:"first_name" validate:"required_without=LastName"`
LastName string `json:"last_name" validate:"required_without=FirstName"`
DisplayName string `json:"display_name"`
Email string `json:"email,omitempty" gorm:"-"`
Emails []Email `json:"emails" validate:"required,dive" gorm:"constraint:OnDelete:CASCADE"`
PasswordHash string `json:"-"`
LastIP string `json:"-"`
CreatedAt *time.Time `json:"-"`
UpdatedAt *time.Time `json:"-"`
}
type Email struct {
ID int `json:"-" gorm:"primaryKey"`
Address string `json:"address" validate:"required,email" gorm:"size:256;uniqueIndex"`
Primary bool `json:"primary"`
UserID int `json:"-"`
}
This approach takes a few lines of code and makes you maintain just a single structure.
However, fitting everything in a single model requires many tricks.
The API shouldn’t expose some fields, so they’re hidden using json:"-".
Only one API endpoint uses the Email field, so the ORM skips it, and the omitempty tag
hides it from regular JSON responses.
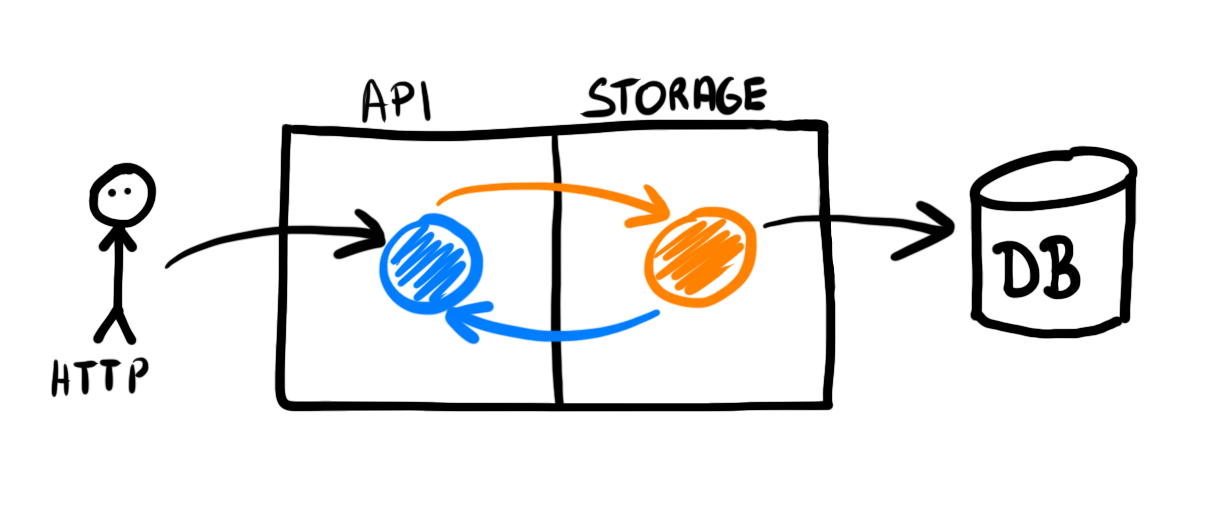
Most importantly, this solution gives you one of the worst issues: strong coupling between the API, storage, and logic.
When you want to update anything in the struct, you have no idea what else can change. You can break the API contract by changing the database schema or corrupt the stored data when updating validation rules.
The more complex the model, the more issues you face.
For example, the json tag means JSON, not HTTP.
What happens when you introduce events that also marshal to JSON but with a bit
different format than the API response? You will keep adding hacks to make it work.
Eventually, your team avoids any changes to the structure because they don’t know what can break after you touch it.
❌ Anti-pattern: The Single Model
Don’t give a single model more than one responsibility.
Don’t use more than one tag per structure field.
Duplication removes coupling
The easiest way to reduce coupling is using separate models.
We extract the API-specific part as HTTP models:
type CreateUserRequest struct {
FirstName string `json:"first_name" validate:"required_without=LastName"`
LastName string `json:"last_name" validate:"required_without=FirstName"`
Email string `json:"email" validate:"required,email"`
}
type UpdateUserRequest struct {
FirstName *string `json:"first_name" validate:"required_without=LastName"`
LastName *string `json:"last_name" validate:"required_without=FirstName"`
}
type UserResponse struct {
ID int `json:"id"`
FirstName string `json:"first_name"`
LastName string `json:"last_name"`
DisplayName string `json:"display_name"`
Emails []EmailResponse `json:"emails"`
}
type EmailResponse struct {
Address string `json:"address"`
Primary bool `json:"primary"`
}
And the database-related part as storage models:
type UserDBModel struct {
ID int `gorm:"column:id;primaryKey"`
FirstName string `gorm:"column:first_name"`
LastName string `gorm:"column:last_name"`
Emails []EmailDBModel `gorm:"foreignKey:UserID;constraint:OnDelete:CASCADE"`
PasswordHash string `gorm:"column:password_hash"`
LastIP string `gorm:"column:last_ip"`
CreatedAt *time.Time `gorm:"column:created_at"`
UpdatedAt *time.Time `gorm:"column:updated_at"`
}
type EmailDBModel struct {
ID int `gorm:"column:id;primaryKey"`
Address string `gorm:"column:address;size:256;uniqueIndex"`
Primary bool `gorm:"column:primary"`
UserID int `gorm:"column:user_id"`
}
At first, it seemed we would use the same “user” model everywhere. Now, it’s clear we’ve avoided duplication too early. The API and storage structures are similar but different enough to use separate models.
In web applications, the views your API returns (read models) are not the same thing you store in the database (write models).
The storage code should know nothing about the HTTP models, so we need to convert the structs.
func userResponseFromDBModel(u UserDBModel) UserResponse {
var emails []EmailResponse
for _, e := range u.Emails {
emails = append(emails, emailResponseFromDBModel(e))
}
return UserResponse{
ID: u.ID,
FirstName: u.FirstName,
LastName: u.LastName,
DisplayName: displayName(u.FirstName, u.LastName),
Emails: emails,
}
}
func emailResponseFromDBModel(e EmailDBModel) EmailResponse {
return EmailResponse{
Address: e.Address,
Primary: e.Primary,
}
}
func userDBModelFromCreateRequest(r CreateUserRequest) UserDBModel {
return UserDBModel{
FirstName: r.FirstName,
LastName: r.LastName,
Emails: []EmailDBModel{
{
Address: r.Email,
},
},
}
}
That’s all the code you need: functions mapping one type to another. Writing such banal code may seem boring, but it’s essential for decoupling.
It’s tempting to create a generic solution to map the structs, like marshaling or using reflect.
Resist it. Writing the boilerplate takes less time and effort than debugging mapping edge cases.
Plain functions are easy to understand for everyone in your team. Arcane converters will be hard to grasp, even for you, after some time.
✅ Tactic: One Model, One Responsibility.
Aim for loose coupling by using separate models. Write plain and obvious functions to convert between them.
If you’re afraid of too much duplication, consider the worst-case scenario. If you end up with a few more structures that stay the same as the application grows, you can merge them back into one. In contrast to tightly-coupled code, fixing duplicated code is trivial.
Generate the Boilerplate
If you worry about writing all this code by hand, there’s an idiomatic way to avoid it. Use libraries that generate the boilerplate for you.
You can generate things like:
- HTTP models and routes out of the OpenAPI definition (oapi-codegen and other libraries).
- Database models and related code out of the SQL schema (sqlboiler and other ORMs).
- gRPC models out of ProtoBuf files.
Generated code gives you strong types, so you no longer pass interface{} to generic functions.
You keep compile-time checks and don’t need to write the code manually.
Here’s how the generated models look.
// PostUserRequest defines model for PostUserRequest.
type PostUserRequest struct {
// E-mail
Email string `json:"email"`
// First name
FirstName string `json:"first_name"`
// Last name
LastName string `json:"last_name"`
}
// UserResponse defines model for UserResponse.
type UserResponse struct {
DisplayName string `json:"display_name"`
Emails []EmailResponse `json:"emails"`
FirstName string `json:"first_name"`
Id int `json:"id"`
LastName string `json:"last_name"`
}
type User struct {
ID int64 `boil:"id" json:"id" toml:"id" yaml:"id"`
FirstName string `boil:"first_name" json:"first_name" toml:"first_name" yaml:"first_name"`
LastName string `boil:"last_name" json:"last_name" toml:"last_name" yaml:"last_name"`
PasswordHash null.String `boil:"password_hash" json:"password_hash,omitempty" toml:"password_hash" yaml:"password_hash,omitempty"`
LastIP null.String `boil:"last_ip" json:"last_ip,omitempty" toml:"last_ip" yaml:"last_ip,omitempty"`
CreatedAt null.Time `boil:"created_at" json:"created_at,omitempty" toml:"created_at" yaml:"created_at,omitempty"`
UpdatedAt null.Time `boil:"updated_at" json:"updated_at,omitempty" toml:"updated_at" yaml:"updated_at,omitempty"`
R *userR `boil:"-" json:"-" toml:"-" yaml:"-"`
L userL `boil:"-" json:"-" toml:"-" yaml:"-"`
}
Sometimes, you may even want to write a code-generating tool.
It’s not that hard, and the result is regular Go code that everyone can read and understand.
The common alternative is reflect, which is terrible to grasp and debug.
Of course, first, consider if the effort is worth it. In most cases, writing the code by hand will be quick enough.
✅ Tactic: Generate the Repetitive Parts
Generated code gives you strong types and compile-time safety.
Choose it over reflect.
Join over 18k subscribers of our newsletter and get a free e-book!

Go With The Domain Three Dots Labs
Don’t overuse libraries
Use the generated code only for what it’s supposed to do. You want to avoid writing the boilerplate by hand, but you should still keep a few dedicated models. Don’t end up with the single model anti-pattern.
It’s easy to fall into this trap when you want to follow DRY.
For example, both sqlc and sqlboiler projects generate code out of SQL queries.
sqlc allows adding JSON tags to the generated models and even lets you choose between camelCase and snake_case.
sqlboiler adds json, toml, and yaml tags to all models by default.
It’s clear people use these models not only for storage.
Looking through sqlc’s issues, I’ve found developers asking for even more flexibility, like renaming the generated fields or skipping some JSON fields entirely. Someone even mentions they Need some way to hide sensitive fields in REST API.
All this encourages keeping a single model for many responsibilities. It lets you write less code, but always consider if the coupling is worth it.
Similarly, watch out for magic hidden in struct tags. For example, consider the permissions model that gorm supports:
type User struct {
Name string `gorm:"<-:create"` // allow read and create
Name string `gorm:"<-:update"` // allow read and update
Name string `gorm:"<-"` // allow read and write (create and update)
Name string `gorm:"<-:false"` // allow read, disable write permission
Name string `gorm:"->"` // readonly (disable write permission unless it configured )
Name string `gorm:"->;<-:create"` // allow read and create
Name string `gorm:"->:false;<-:create"` // createonly (disabled read from db)
Name string `gorm:"-"` // ignore this field when write and read with struct
}
You can also use quite complex comparisons using the validator library, like referencing other fields:
type User {
FirstName string `validate:"required_without=LastName"`
LastName string `validate:"required_without=FirstName"`
}
It saves you a bit of time writing the code, but you give up the compile-time checks. It’s easy to make a typo in a struct tag, and it’s a risk using it for sensitive areas like validation and permissions. It’s also confusing to anyone not familiar with the library’s arcane syntax.
I don’t mean to pick on the mentioned libraries. They all have their uses, but these examples show how we tend to take DRY to the extremes, so we don’t have to write more code.
❌ Anti-pattern: Choosing magic to save time writing code
Don’t overuse the libraries to avoid verbosity.
Avoid implicit tag names
Most libraries don’t require the tags to be present and use field names by default.
While refactoring the project, someone can rename a field, unaware they edit an API response or a database model. If there are no tags, this can break your API contract or even corrupt your storage.
Always fill all the tags. Even if you have to type the same name twice, it’s not against DRY.
❌ Anti-pattern: Omitting Structure Tags
Don’t skip struct tags if a library uses them.
type Email struct {
ID int `gorm:"primaryKey"`
Address string `gorm:"size:256;uniqueIndex"`
Primary bool
UserID int
}
✅ Tactic: Explicit Structure Tags
Always fill the struct tags, even if the field names are the same.
type Email struct {
ID int `gorm:"column:id;primaryKey"`
Address string `gorm:"column:address;size:256;uniqueIndex"`
Primary bool `gorm:"column:primary"`
UserID int `gorm:"column:user_id"`
}
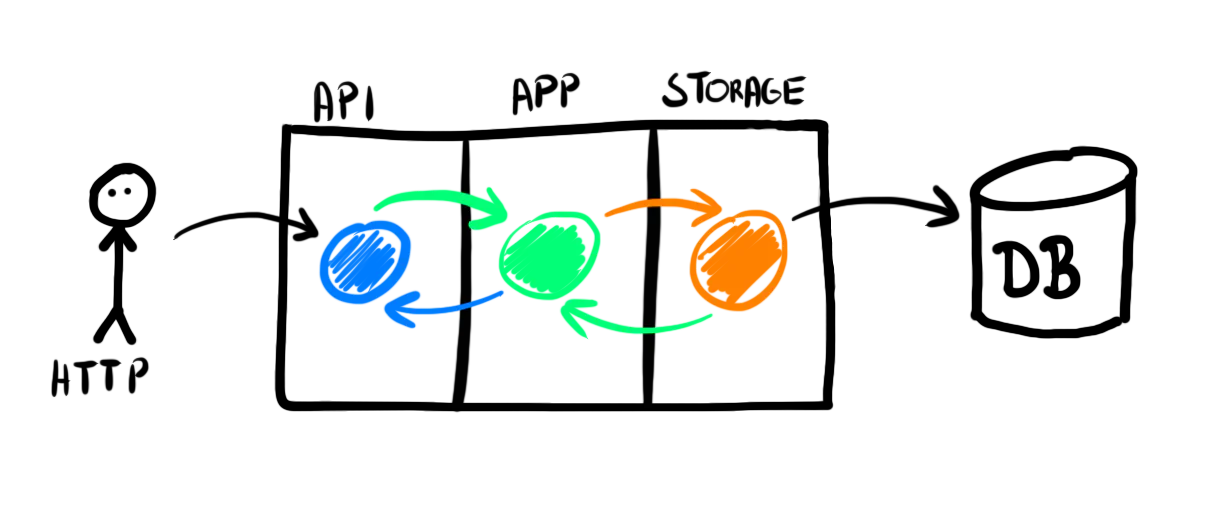
Separate Logic from Implementation Details
Decoupling the API from the storage and using generated models is a good start. But we still keep validation in the HTTP handlers.
type createRequest struct {
Email string `validate:"required,email"`
FirstName string `validate:"required_without=LastName"`
LastName string `validate:"required_without=FirstName"`
}
validate := validator.New()
err = validate.Struct(createRequest(postUserRequest))
if err != nil {
log.Println(err)
w.WriteHeader(http.StatusBadRequest)
return
}
Validation is just one part of the business logic you find in most web applications. Often, there will be more of it, like:
- showing fields only in particular cases,
- checking permissions,
- hiding fields depending on the role,
- calculating the price,
- taking action depending on a few factors.
Mixing logic with implementation details (like keeping it in the HTTP handlers) is a quick way to deliver an MVP. But it also introduces the worst kind of technical debt. It’s why you get vendor lock-in and why you keep adding hacks to support new features.
❌ Anti-pattern: Mixing logic and details
Don’t mix your application logic with implementation details.
Business logic deserves its own layer. Changing the implementation (database engine, HTTP library, infrastructure, Pub/Sub, etc.) should be possible without any changes to the logic parts.
You’re not doing this separation because you expect to change the database. It rarely happens. But the separation of concerns makes your code easy to understand and modify. You know what you’re changing, and there are no side effects. It’s harder to introduce bugs in the most crucial parts.
To separate the application layer, we need to add additional models and mappings.
type User struct {
id int
firstName string
lastName string
emails []Email
}
func NewUser(firstName string, lastName string, emailAddress string) (User, error) {
if firstName == "" && lastName == "" {
return User{}, ErrNameRequired
}
email, err := NewEmail(emailAddress, true)
if err != nil {
return User{}, err
}
return User{
firstName: firstName,
lastName: lastName,
emails: []Email{email},
}, nil
}
type Email struct {
address string
primary bool
}
func NewEmail(address string, primary bool) (Email, error) {
if address == "" {
return Email{}, ErrEmailRequired
}
// A naive validation to make the example short, but you get the idea
if !strings.Contains(address, "@") {
return Email{}, ErrInvalidEmail
}
return Email{
address: address,
primary: primary,
}, nil
}
It’s the code I’d like to work with when I need to update the business logic. It’s boring, obvious, and I know exactly what’s going to change.
We do the same thing when adding another API, like gRPC, or an external system, like a Pub/Sub. Each part uses separate models, and we use those from the application layer to map them.
Because the application models hold all validations and other business rules, it makes no difference whether we use them from an HTTP or gRPC API. The API is just an entry point to the application.
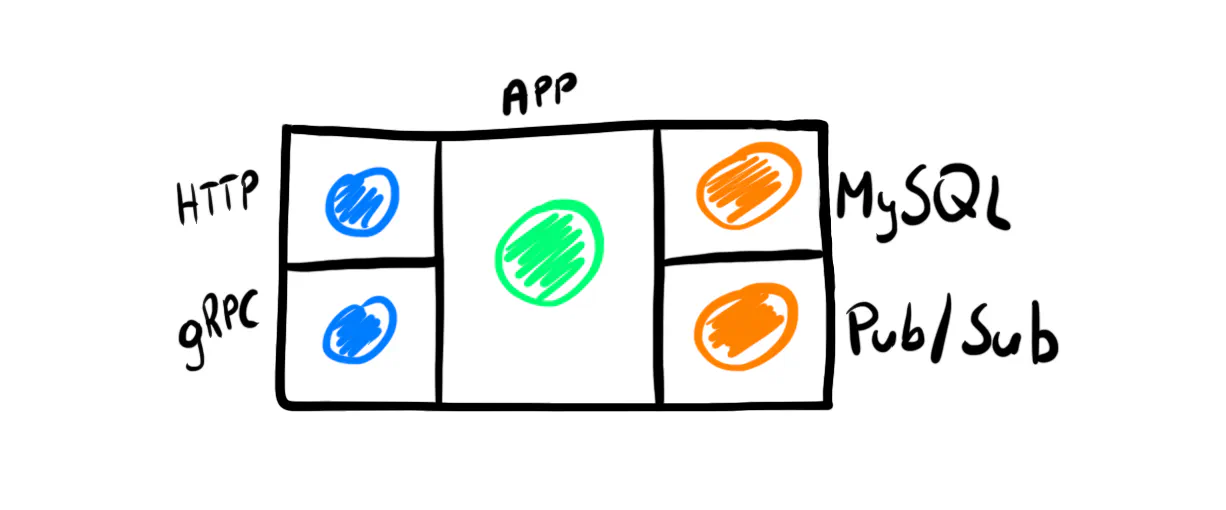
✅ Tactic: Application Layer
Dedicate a separate layer to your product’s most important code.
The code snippets above come from the same repository and implement a classic “users” domain. All examples expose the same API and pass the same test suite.
Here’s how they compare:
| Tightly Coupled | Loosely Coupled | Loosely Coupled Generated | Loosely Coupled App Layer | |
|---|---|---|---|---|
| Coupling | Strong | Medium | Medium | Weak |
| Boilerplate | Manual | Manual | Generated | Generated |
| Lines of code | 292 | 345 | 298 | 408 |
| Generated code | 0 | 0 | 2154 | 2154 |
The Standard Go Project Structure
If you’ve seen the repository, you may be surprised there’s just a single package in each example.
There’s no official directory structure in Go. You can find many “example microservice” or “REST boilerplate” repositories that propose how to split the packages. They usually have a well-designed directory structure. Some even mention they follow “Clean Architecture” or “Hexagonal Architecture”.
The first thing I check is how the example keeps models. Most often, it uses structures with JSON and database tags combined.
It’s an illusion: the packages look nicely separated on the outside, but in reality, the single model couples them. It’s common even for popular examples that newcomers use to learn.
Ironically, the “Standard Go Project Structure” discussion continues in the community, while the single model anti-pattern is widespread. If types couple your application, no directory structure will change it.
While you look at the example structures, keep in mind they could be designed for a different kind of application. No approach works equally well for an open-source infrastructure tool, a web application’s backend, and the standard library.
The problem with package hierarchy is similar to splitting microservices. The important part is not how you split them but how they’re connected.
When you focus on loose coupling, the structure becomes obvious. You separate the implementation details from the business logic. You group things that refer to each other and keep separate things that don’t.
In the examples I’ve prepared, I could easily move HTTP-related and database-related code to separate packages. It would make the namespace less polluted. There’s already no coupling between the models, so it’s just a detail.
❌ Anti-pattern: Overthinking the directory structure
Don’t start the project by separating directories. However you do it, it’s a convention.
You’re unlikely to do it right before you’ve written any code.
✅ Tactic: Loosely Coupled Code
The important part isn’t the directory structure but how packages and structures reference each other.
Keeping it simple
Let’s say you want to create a user with an ID field. The simplest approach can look like this:
type User struct {
ID string `validate:"required,len=32"`
}
func (u User) Validate() error {
return validate.Struct(u)
}
This code works. However, you can’t tell if the struct is correct at any point. You rely on something to call the validation and handle the error correctly.
Another approach follows the good old encapsulation.
type User struct {
id UserID
}
type UserID struct {
id string
}
func NewUserID(id string) (UserID, error) {
if id == "" {
return UserID{}, ErrEmptyID
}
if len(id) != 32 {
return UserID{}, ErrInvalidLength
}
return UserID{
id: id,
}, nil
}
func (u UserID) String() string {
return u.id
}
This snippet is more explicit and verbose. If you create a new UserID and receive no error, you’re sure it’s valid.
Otherwise, you can easily map the error to a proper response specific to your API.
Whatever approach you choose, you need to model the essential complexity of the user’s ID. From the pure implementation point of view, keeping the ID in a string is the simplest solution.
Go is supposed to be simple, but it doesn’t mean you should use only primitive types. For complex behaviors, use code that reflects how the product works. Otherwise, you’ll end up with a simplified model of it.
❌ Anti-pattern: Over-simplification
Don’t model complex behavior with trivial code.
✅ Tactic: Write obvious code
Be explicit, even if it’s verbose.
Use encapsulation to ensure your structs are always in a valid state.
Note
It’s possible to create an empty structure outside the package, even if all fields are unexported.
It’s the only thing you have to check when accepting UserID as a parameter.
You can either use if id == UserID{} or write a dedicated IsZero() method that does it.
Starting with the database schema
Let’s consider adding teams that users create and join.
Following the relational approach, we would add a teams table and another one that joins it with users. Let’s call it membership.
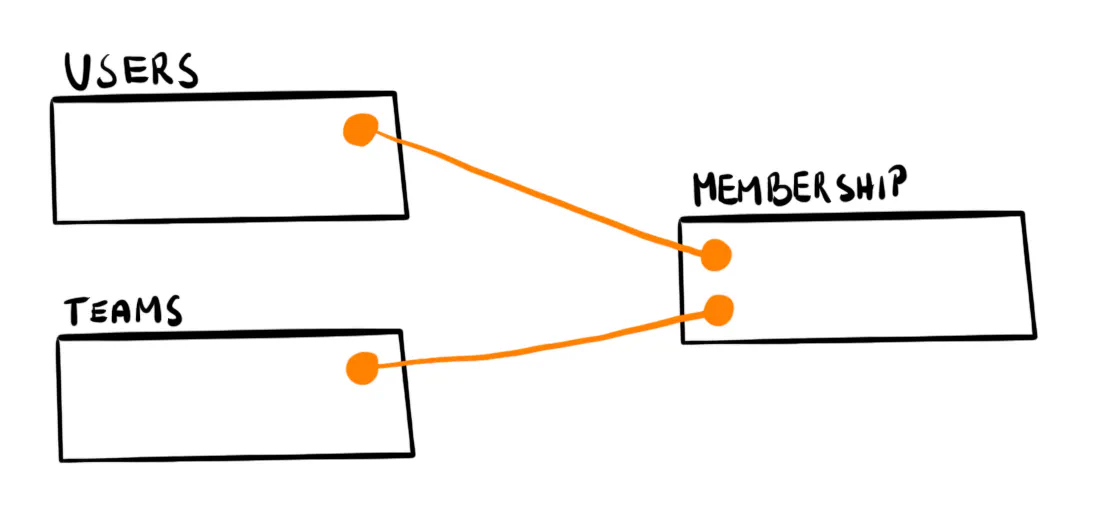
We already keep UserStorage, so it’s natural to add two more structs: TeamStorage and MembershipStorage.
They expose CRUD methods for each table.
A snippet adding a new team could look like this:
func CreateTeam(teamName string, ownerID int) error {
teamID, err := teamStorage.Create(teamName)
if err != nil {
return err
}
return membershipStorage.Create(teamID, ownerID, MemberRoleOwner)
}
This approach has one issue: we don’t create the team and the membership entry within a transaction. We might end up with a team without an owner assigned if things go wrong.
The first solution that comes to mind is passing a transaction object between methods.
func CreateTeam(teamName string, ownerID int) error {
tx, err := db.Begin()
if err != nil {
return err
}
defer func() {
if err == nil {
err = tx.Commit()
} else {
rollbackErr := tx.Rollback()
if rollbackErr != nil {
log.Error("Rollback failed:", err)
}
}
}()
teamID, err := teamStorage.Create(tx, teamName)
if err != nil {
return err
}
return membershipStorage.Create(tx, teamID, ownerID, MemberRoleOwner)
}
However, this approach leaks the implementation details (transaction handling) to the logic layer.
It pollutes a readable function with defer-based error handling.
Here’s an exercise: consider how we would model this in a document database. For example, we could keep all Members inside the Team document.
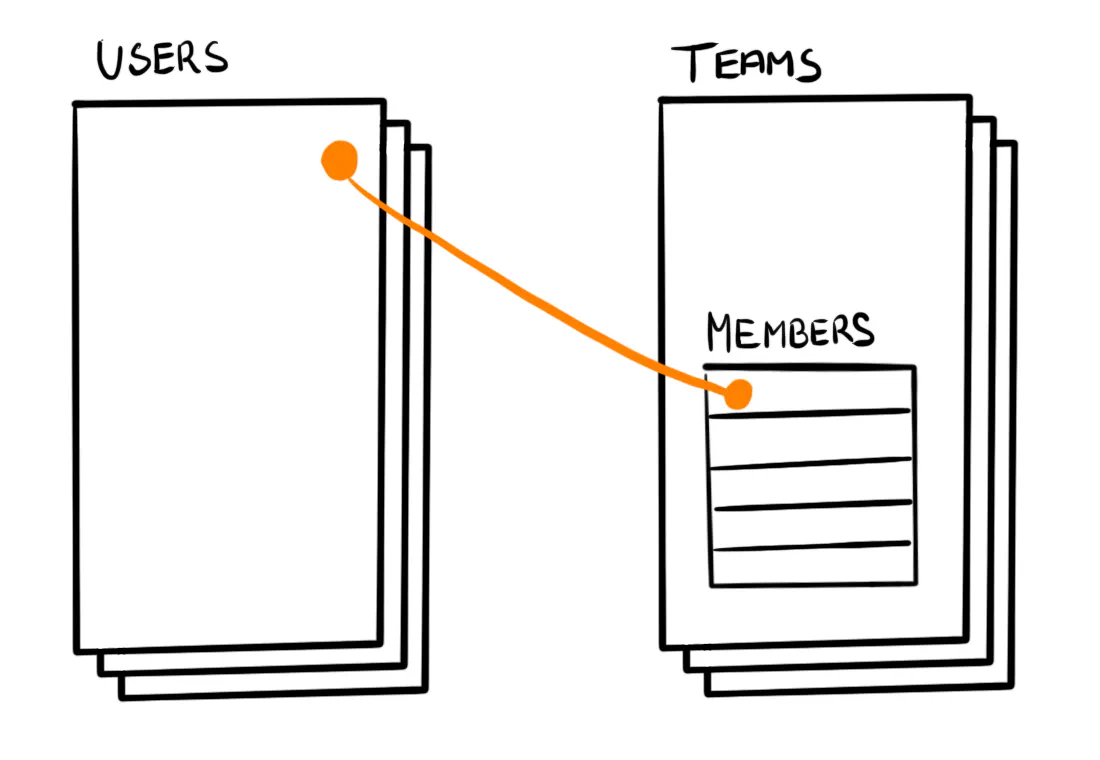
In this scenario, adding members would be done in TeamStorage. We wouldn’t need a separate MembershipStorage.
Isn’t it weird that switching the database changes our assumption about the models?
It’s now clear we’ve leaked the implementation details by introducing the “membership” concept. By saying “create a new membership,” we would only confuse our sales or customer service colleagues. It’s a major red flag when you start speaking a different language than the rest of the company.
❌ Anti-pattern: Starting with the database schema
Don’t base your models on the database schema. You will end up exposing implementation details.
TeamStorage stores teams, but it’s not about the teams SQL table. It’s about our product’s team concept.
When you start modeling from the domain, you see actual behaviors instead of CRUD methods. You also notice the transaction boundaries.
Everyone understands creating a team requires an owner, and we can expose a method for it. The method executes all queries within a transaction.
teamStorage.Create(teamName, ownerID, MemberRoleOwner)
Similarly, we could keep a method for joining a team.
teamStorage.JoinTeam(teamID, memberID, MemberRoleGuest)
The membership table is still there, but it’s an implementation detail hidden in the TeamStorage.
✅ Tactic: Start with the domain
Your storage methods should follow the product’s behavior. Don’t leak transactions out of them.
Your Web Application is not a CRUD
Tutorials often feature “simple CRUDs”, so they seem to be the building block of any web application. It’s a myth. If all your product needs is a CRUD, you waste time and money writing it from scratch.
Frameworks and no-code tools make it easy to bootstrap CRUDs, but we still pay developers to build custom software. Even GitHub’s Copilot won’t know how your product works besides the boilerplate.
It’s the special rules and weird details that make your application different. It’s not some logic you sprinkle on top of the four CRUD operations. It’s the core of the product you sell.
In the MVP stage, it’s tempting to start with a CRUD to build a working version quickly. But it’s like using a spreadsheet instead of dedicated software. You get similar results at first, but each new feature requires more hacks.
❌ Anti-pattern: Starting with a CRUD
Don’t design your application around the idea of four CRUD operations.
✅ Tactic: Understand your domain
Spend time to understand how your product works and model it in the code.
Many of the tactics I’ve described are ideas behind well-known patterns:
- Single Responsibility Principle from SOLID (a single model responsible for one thing).
- Clean Architecture (loosely coupled packages, separating logic from details).
- CQRS (using different read models and write models).
Some are even close to Domain-Driven Design:
- Value Objects (keeping structures always in a valid state).
- Aggregate and Repository (saving domain objects transactionally regardless of the number of database tables).
- Ubiquitous Language (using a language everyone understands).
These patterns seem linked mostly to enterprise applications. But most of them are about straightforward core ideas, like the tactics from this article. They apply just as well in web applications, which often deal with complex business behaviors.
You don’t need to read heavy books or copy how things work in other languages to follow these patterns. It’s possible to write idiomatic Go code together with battle-proven techniques. If you want to learn more about them, check out our free e-book.
Note
Let us know in the comments if you’d like to see more examples added to the anti-patterns repository and on what topics.


