Using MySQL as a Pub/Sub

If you compare MySQL or PostgreSQL with Kafka or RabbitMQ, at first, it seems they are entirely different software. And usually, that’s true, as you would use them for quite different tasks. What they have in common is processing streams of data, and they specialize in specific ways of doing it.
While Kafka and RabbitMQ are popular examples of Pub/Subs (also known as message queues or stream processing platforms), I’d like to share some patterns for using SQL databases as Pub/Subs as well. But shouldn’t we pick the right tool for the job? That’s right. However, SQL databases are readily available if you don’t have access to the dedicated messaging infrastructure. They also have some unique features that turn out useful while working with message-driven applications.
I’m going to show three examples of such cases with solutions based on the Watermill library for Go, although the patterns stay the same regardless of the language. But first, let’s ask the fundamental question.
What is a Pub/Sub?
If you generalize it enough, you can define any Pub/Sub client with just two methods (as the name suggests): one for publishing a new message to a topic, and the other for subscribing for messages from a topic.
Publish(topic, message)
Subscribe(topic) stream<message>
So how do you implement this interface for an SQL database? The simplest way is to use INSERT statements for publishing and SELECT for consuming messages. More advanced subscribing patterns can be achieved with mechanisms like MySQL’s binlog or PostgreSQL’s LISTEN and NOTIFY commands. But for most use cases, the simple approach should be good enough.
Using Watermill
The two-method pseudocode above is also the base idea behind Watermill’s Publisher and Subscriber interfaces. It turns out you can hide quite a lot of complexity behind this abstraction. To implement any Pub/Sub, all you have to do is implement these two methods. One of the supported Pub/Subs is the SQL Pub/Sub.
All examples below include a short snippet of Watermill’s handler, which is a function that receives a message and can return new messages to be published.
func(msg *message.Message) ([]*message.Message, error)
See the Getting started guide for more details.
Pattern 1: Persistent Event Log
Message queues offer various features depending on the design. That’s why no one fits all use cases.
One of such features is persistent storage. For example, Apache Kafka comes out of the box with support for storing messages on topics as long as you need it. Others, like Google Cloud Pub/Sub*,* treat messages as ephemeral and delete them after they are consumed or even after several days without being acknowledged.
You don’t always need to store messages, but it comes in useful when working with domain events. It allows processing events from the past again, sort of like “going back in time” (a similar approach to Event Sourcing, although much simplified).
If you’d like to keep your current messaging software but need persistent storage for events, an SQL database might be the right choice.
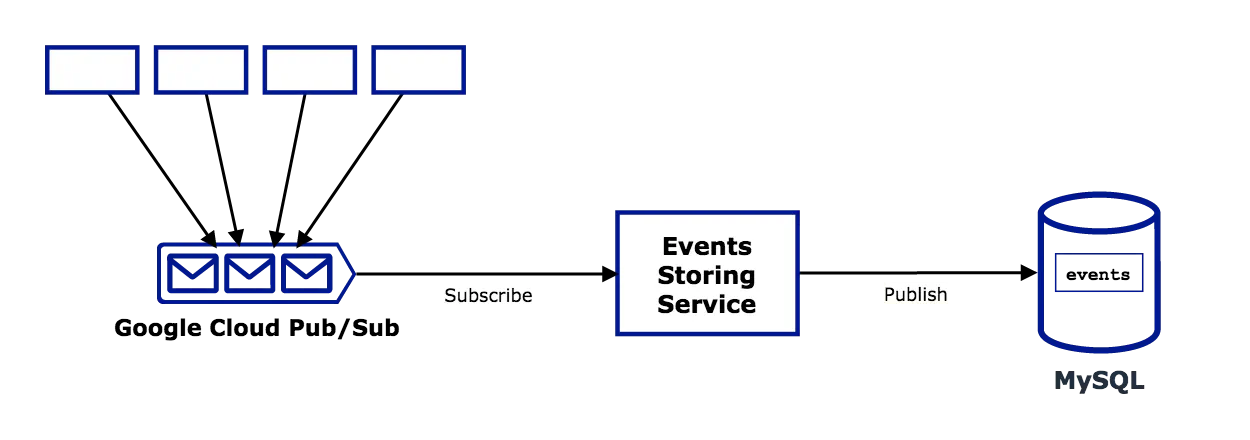
Implementation
The Watermill handler for this pattern is the simplest one. It works just like a transparent proxy, moving messages from one system to the other. The Router component does all the work in the background. All you have to do is define the subscriber, publisher, and corresponding topics.
router.AddHandler(
"googlecloud-to-mysql", // unique handler name
googleCloudTopic, // subscriber's topic
googleCloudSubscriber, // subscriber
mysqlTable, // publisher's topic
mysqlPublisher, // publisher
func(msg *message.Message) ([]*message.Message, error) {
return []*message.Message{msg}, nil
},
)
See full source: persistent-event-log example.
Pattern 2: Transactional Events
Consider user signup, a classic use case in every web application. The requirements are straightforward. You need to store user details in an SQL table and publish UserSignedUp event, so other services in your system consume it and take some action (e.g., send a newsletter, update statistics report, fill personal details in a CRM).
The issue is, you can’t execute SQL statements and publish events both at the same time. You have two options:
- Save the user first, then publish the event — if publishing fails, the SQL table is up to date, but the rest of the system is inconsistent. The user can log in, but doesn’t receive a newsletter, the monthly statistics report is incorrect, and your sales team doesn’t know whom to call. Other teams that depend on the event will never receive it.
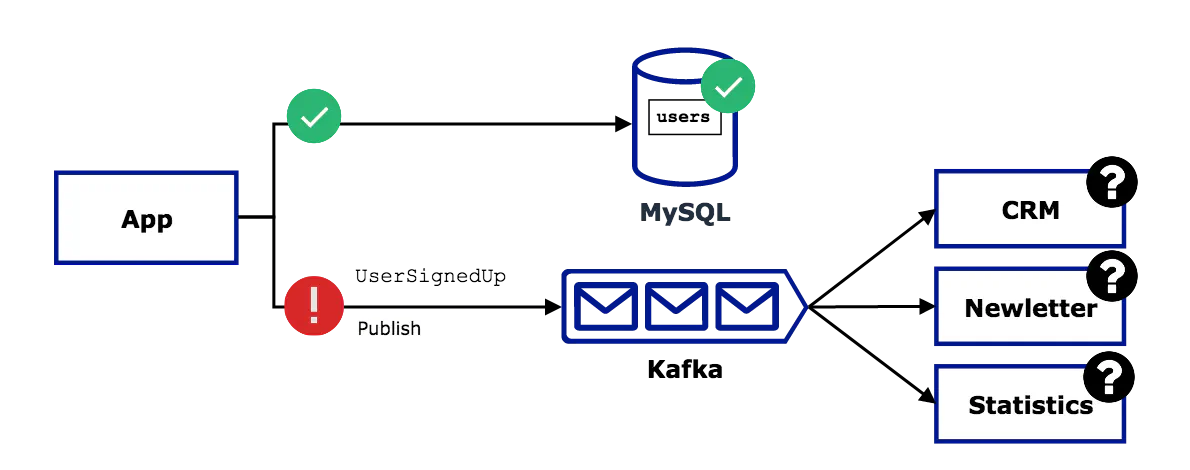
- Publish the event first, then save the user — if saving the user fails, the system is consistent, but the SQL table is outdated. The user can’t log in but receives a newsletter. Your reports show more users than there are using your product, and your sales team nags the frustrated user with calls. Let’s hope your “unsubscribe” button still works.
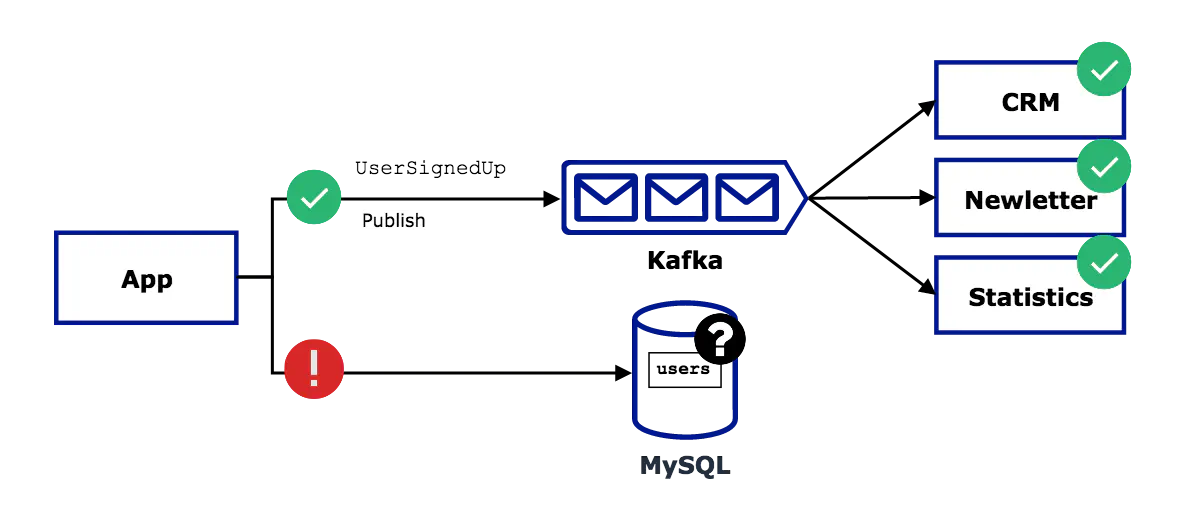
You can come up with complicated solutions for this problem, like two-phase commits or periodically synchronizing all systems. There’s also a more straightforward pattern using the SQL database.
The idea is to insert the event into a separate table instead of publishing it directly. The critical part is doing it within the same transaction as saving the user. It guarantees both or none are stored. In the background, a separate process is subscribed to the table with events and publishes all incoming rows on some message queue.

Note
One thing to keep in mind is that eventual consistency must be acceptable in your system. It’s possible that the background process stops working for some reason and publishes events sometime in the future. But if you’re already working with events, I hope you did consider that.
Implementation
When using Watermill, the handler function is very similar to the previous example. After all, it’s the same kind of event proxy, but this time the database is the entry point.
router.AddHandler(
"mysql-to-kafka",
mysqlTable,
mysqlSubscriber,
kafkaTopic,
kafkaPublisher,
func(msg *message.Message) ([]*message.Message, error) {
return []*message.Message{msg}, nil
},
)
See full source: transactional-events example.
Pattern 3: Synchronizing Databases
Synchronizing two databases isn’t a new problem. That’s how replication already worked for decades. It operates on low-level mechanisms (like the binary log), but the idea is very close to a Pub/Sub: one database is publishing changes, and the other subscribes to them.
A bit harder task is moving data between two different database engines, each with distinct table schema. If replication is using an interface similar to a Pub/Sub, can we use the same principles for migration as well?
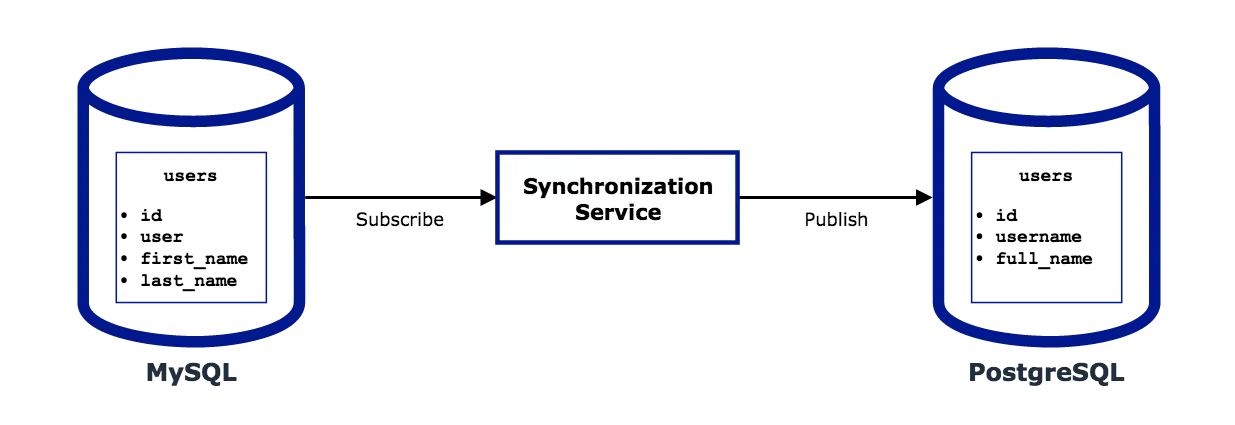
Let’s consider migrating a MySQL table to PostgreSQL. It would look roughly like this:
- The application inserts a new row into the MySQL table.
- Synchronization service receives this as an update (because it subscribed to that table).
- The service translates the row into the destination format (only if schemas differ, so this step is optional).
- The service inserts a new row into the PostgreSQL table (publish).
Note
The hard part about implementing this handler is making sure we keep proper order of events, don’t miss any rows, and don’t duplicate them. The first two are solved for you by Watermill out of the box, but you need to take care of de-duplicating the events yourself. A simple approach is to make sure your event handlers are idempotent.
Implementation
If table schemas in both databases are the same, the handler can be as short, as in the first two patterns. In this example, we deal with distinct tables, so we need to implement the translation part as well.
First of all, we need to rename the user column to username. Second, merge first_name and last_name columns into full_name.
You can see that the gob library is used for encoding and decoding the payloads, but you can use anything you like, as long as it serializes to a slice of bytes.
Note
By default, the SQL subscriber consumes all existing records in the table and listens for any new incoming rows. So you can start with migrating the current data and then keep the service running to keep both databases up to date. The synchronization will work as long as your tables are append-only - see Limitations below for details.
type mysqlUser struct {
ID int
User string
FirstName string
LastName string
CreatedAt time.Time
}
type postgresUser struct {
ID int
Username string
FullName string
CreatedAt time.Time
}
router.AddHandler(
"mysql-to-postgres",
mysqlTable,
mysqlSubscriber,
postgresTable,
postgresPublisher,
func(msg *message.Message) ([]*message.Message, error) {
// Decode the row coming from the MySQL table
decoder := gob.NewDecoder(bytes.NewBuffer(msg.Payload))
originUser := mysqlUser{}
err := decoder.Decode(&originUser)
if err != nil {
return nil, err
}
// Translate from the MySQL schema to the PostgreSQL schema
newUser := postgresUser{
ID: originUser.ID,
Username: originUser.User,
FullName: fmt.Sprintf("%s %s", originUser.FirstName, originUser.LastName),
CreatedAt: originUser.CreatedAt,
}
// Encode the row to be saved in the PstgreSQL table
var payload bytes.Buffer
encoder := gob.NewEncoder(&payload)
err = encoder.Encode(newUser)
if err != nil {
return nil, err
}
newMessage := message.NewMessage(watermill.NewULID(), payload.Bytes())
return []*message.Message{newMessage}, nil
},
)
This example is complex enough to introduce a new Schema Adapter. Refer to the full source to see the implementation: synchronizing-databases example.
Limitations
While you can implement all patterns above using Watermill’s SQL Pub/Sub, it has some limitations.
Currently, only the INSERT statement triggers new messages sent to the subscriber. The good news is there’s planned support for MySQL binlog and PostgreSQL LISTEN/NOTIFY subscribers, and they allow listening for updates and deletes as well.
The SQL Pub/Sub is also a low performer compared to other Pub/Subs. The current MySQL subscriber can process about 150 messages per second. That’s almost 13 million messages daily, so there’s a chance that’s more than enough for your needs.
Update: There’s an interesting discussion on Hacker News on using databases as Pub/Subs and related topics.




