Auto-generated C4 Architecture Diagrams in Go

Note
Hello! Please give Krzysztof a warm welcome in the first guest post on our blog. 🎉 We’ve been working with Krzysztof for the past two years, and we’re excited to share his work here.
Miłosz & Robert
We all struggle with software architecture diagrams, don’t we? Have you ever wondered why? If you ask yourself that question, why maintenance of up-to-date and detailed software architecture diagrams is so painful, you will come up with a long list of valid answers.
Our software changes all the time. We update it daily, starting with a simple change of names, and ending with nuke-refactoring, reshaping the entire application. Each of those changes requires careful alignment of the software architecture diagrams. Most likely, you have also thought that drawing diagrams with even the most convenient tools is time-consuming. It requires a lot of effort. Those diagrams notoriously get out of control, storing outdated naming and already-dropped modules while missing their initial readable and well-organised structure. All of that makes this particularly frustrating.
If an ideal world ever existed…
Everyone appreciates a well-structured diagram when joining a new, unexplored project. Even better if it is an easy-to-navigate, map-like C4 model diagram.
If this concept doesn’t sound familiar to you, there is a simple idea behind it. C4 model introduces four layers of software architecture visualisation: Context, Containers, Components, and Code. Depending on the information you are looking for, you can drill down to the specific part of the implementation, the same way you look into geographical maps. When searching for a particular address, you usually use a city or even a district map, not a map of the whole country. Consequently, when you check how single service modules talk to each other, you will find it in the diagram of that service Components layer. When you look for services and runtimes interactions, you will go to the Containers one. Do you get the idea? For more information, go to C4 model site. In my opinion, this is the best approach proposed so far.
Is maintaining detailed and up-to-date diagrams of your applications’ architecture worth all that effort? And does it have to be done manually? What if we could…
Automate it!
If you work within a Go ecosystem, you are used to code generation. What if we also could generate software diagrams from the code? Moreover, what if we could do this automatically, within continuous integration pipelines?
Driven by this idea, I wrote a library that generates diagrams out of code with just a single configuration file. Let me show you how to use it.
Let’s start simple
To demonstrate the feature, I selected a repository that most readers are familiar with – wild-workouts-go-ddd-example application. There are a couple of services that we could try to generate diagrams for. Let’s start with the trainer one.
At the moment, the library provides a set of components to code your own diagram auto-generation command.
I did that in the wild-workouts-go-ddd-example repository. Within a separate tools/c4 directory I created a simple command file.
func main() {
s, err := scraper.NewScraperFromConfigFile("scraper.yml")
if err != nil { ... }
app := trainerService.NewApplication(context.Background())
structure := s.Scrape(app)
v, err := view.NewViewFromConfigFile("scraper.yml")
if err != nil { ... }
outFile, err := os.Create("out/view.plantuml")
if err != nil { ... }
defer outFile.Close()
err = v.RenderStructureTo(structure, outFile)
if err != nil { ... }
}
In this command, I use a couple of components provided by the library.
The first one, the scraper, crawls down any Go structure and collects visited components following provided configuration and scraping rules. I started with a minimal configuration file:
configuration:
pkgs:
- "github.com"
rules:
- name_regexp: ".*"
pkg_regexps:
- ".*"
In the configuration, I instruct the scraper to crawl all components from any package starting with a github.com prefix and then to collect the ones that match the rule with the provided name and package regular expressions. The expression .* would match any string, so basically, I want to capture everything.
For those of you who are YAML haters, the very same configuration may be done programmatically.
Moving next, I need to instantiate the service application context as the “content” to scrape. Robert and Miłosz had implemented a convenient constructor, which I invoke here. Then I can pass it to the scraper and get the returned Structure model containing all the collected data.
I instantiate another library component to render the acquired structure into the output file – the view. It consumes the same configuration file as the scraper, enhanced with just a single line of the view definition.
view:
title: Trainer service components
…and I render it.
The output file is of type *.plantuml. I need to render it into a *.png image file with the plantuml CLI tool.
plantuml out/view.plantuml
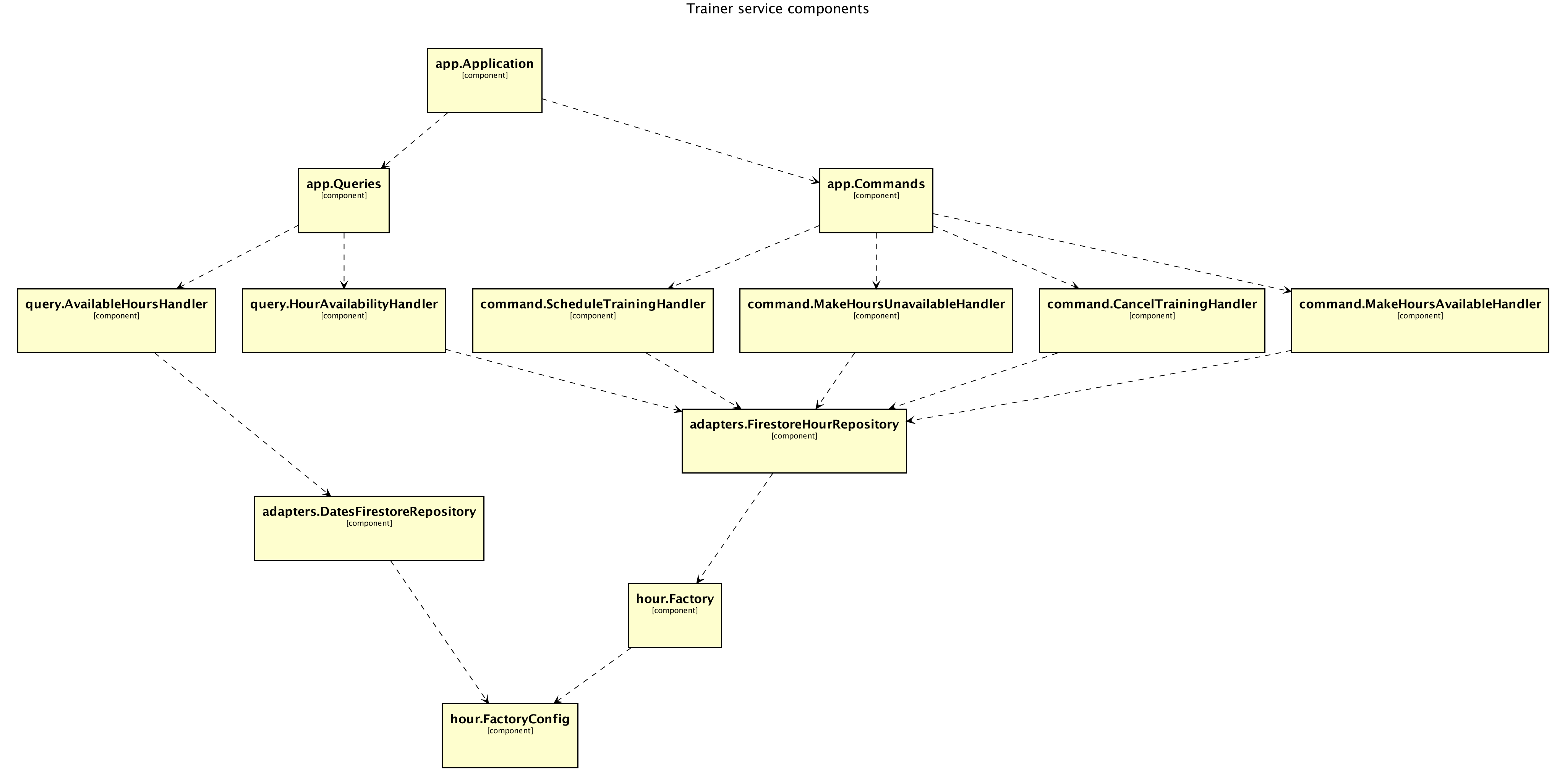
Here is what I got:
Getting fancier
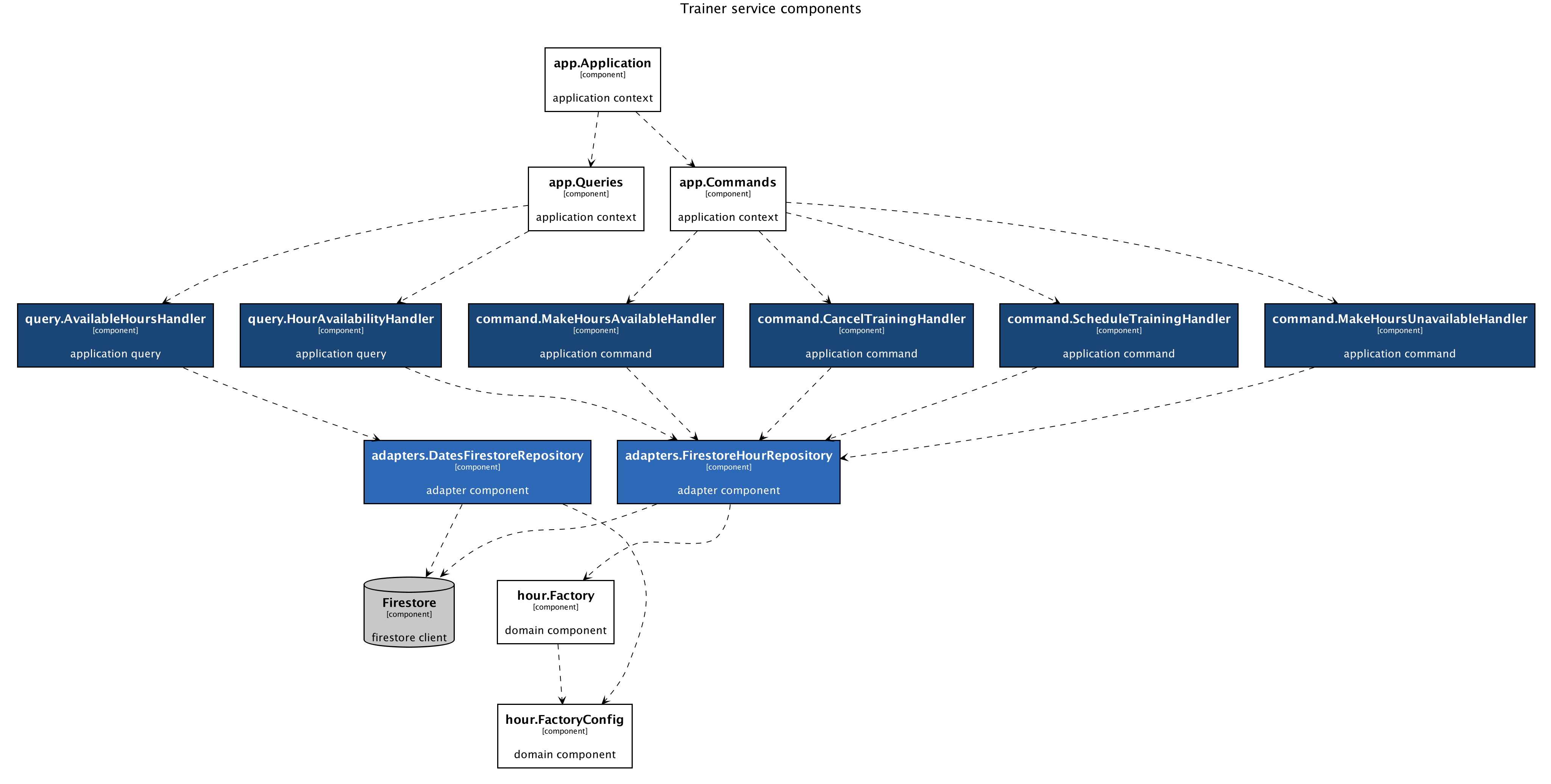
So far, so good. But there is at least a couple of issues here. It works, but it is all flat! All I can see in the diagram is a map of components without any details, description, or color-coding. Which of the components belong to the application or domain layer? Also, we do not know much about the infrastructure around. Is there any database being used? If yes, which of the components are using it? Let’s iterate.
I need to extend the scraping range by adding the package with the firestore client. The application uses the firestore database, so I included its client in the diagram.
configuration:
pkgs:
- "github.com"
- "cloud.google.com/go/firestore"
Then, I create several rules that would instruct the scraper on interpreting the components from specified packages. With rules, I could tag components, add descriptions, define name functions, and much more.
Here are a few examples of rules where I define application, domain, and database components.
rules:
- name_regexp: ".*"
pkg_regexps:
- ".*/app/command.*"
component:
description: "application command"
tags:
- APP
- name_regexp: ".*"
pkg_regexps:
- ".*/domain/.*"
component:
description: "domain component"
tags:
- DOMAIN
- name_regexp: ".*Client$"
pkg_regexps:
- "cloud.google.com/go/firestore$"
component:
name: "Firestore"
description: "firestore client"
tags:
- DB
Finally, I can add some view styles and assign those to the tags defined above.
view:
title: Trainer service components
line_color: 000000ff
styles:
- id: APP
background_color: 1a4577ff
font_color: ffffffff
border_color: 000000ff
- id: DOMAIN
background_color: ffffffff
font_color: 000000ff
border_color: 000000ff
- id: DB
background_color: c8c8c8ff
font_color: 000000ff
border_color: 000000ff
shape: database
When I reran the scraper, I got the following result. Doesn’t it look much better now?
Want more?
If you want to have a deeper look into this example, go to wild-workouts-go-ddd-example application repo and check the implementation where I generate complete diagrams for all of the microservices.
You can also learn more about the library itself. Visit go-structurizr repo and dive deep into the documentation and provided examples.
Having a pretty powerful way to auto-generate diagrams out of the golang code, every time you change your code, you can just regenerate diagrams reusing the very same configuration! Finally, it may sound tempting to fully automate it as part of our regular CI pipelines. If you want to know how I do that, let me know in the comments.




