How to use basic CQRS in Go

You probably know at least one service that:
- has one big, unmaintainable model that is hard to understand and change,
- limits parallel work on new features,
- or can’t scale optimally.
But bad things often come in threes. It’s not uncommon to see services with all these problems.
What idea comes to mind first for solving these issues? Let’s split it into more microservices!
Unfortunately, without proper research and planning, the situation after blindly refactoring may actually be worse than before:
- Business logic and flow may become even harder to understand: complex logic is often easier to understand if it’s in one place.
- Distributed transactions: things are sometimes together for a reason. A big transaction in one database is much faster and less complex than a distributed transaction across multiple services.
- Adding new changes may require extra coordination if one of the services is owned by another team.

To be clear: I’m not an enemy of microservices. I’m just against blindly applying microservices in a way that introduces unnecessary complexity and mess instead of making our lives easier.
Another approach is using CQRS (Command Query Responsibility Segregation) with previously described Clean Architecture and DDD Lite. It can solve the mentioned problems in a much simpler way.
Isn’t CQRS a complex technique?
Isn’t CQRS one of those C#/Java/über enterprise patterns that are hard to implement and make a big mess in the code? Many books, presentations, and articles describe CQRS as a very complicated pattern. But that’s not the case.
In practice, CQRS is a simple pattern that doesn’t require a lot of investment. It can be easily extended with more complex techniques like event-driven architecture, event-sourcing, or polyglot persistence. But these aren’t always needed. Even without any extra patterns, CQRS can offer better decoupling and code structure that is easier to understand.
When to not use CQRS in Go? How to get all benefits from CQRS? You can learn all that in today’s article. 😉
As always, I will do this by refactoring the Wild Workouts application.
Note
This is not just another article with random code snippets.
This post is part of a bigger series where we show how to build Go applications that are easy to develop, maintain, and fun to work with in the long term. We are doing it by sharing proven techniques based on many experiments we did with teams we lead and scientific research.
You can learn these patterns by building with us a fully functional example Go web application – Wild Workouts.
We did one thing differently – we included some subtle issues to the initial Wild Workouts implementation. Have we lost our minds to do that? Not yet. 😉 These issues are common for many Go projects. In the long term, these small issues become critical and stop adding new features.
It’s one of the essential skills of a senior or lead developer; you always need to keep long-term implications in mind.
We will fix them by refactoring Wild Workouts. In that way, you will quickly understand the techniques we share.
Do you know that feeling after reading an article about some technique and trying implement it only to be blocked by some issues skipped in the guide? Cutting these details makes articles shorter and increases page views, but this is not our goal. Our goal is to create content that provides enough know-how to apply presented techniques. If you did not read previous articles from the series yet, we highly recommend doing that.
We believe that in some areas, there are no shortcuts. If you want to build complex applications in a fast and efficient way, you need to spend some time learning that. If it was simple, we wouldn’t have large amounts of scary legacy code.
Here’s the full list of 14 articles released so far.
The full source code of Wild Workouts is available on GitHub. Don’t forget to leave a star for our project! ⭐
How to implement basic CQRS in Go
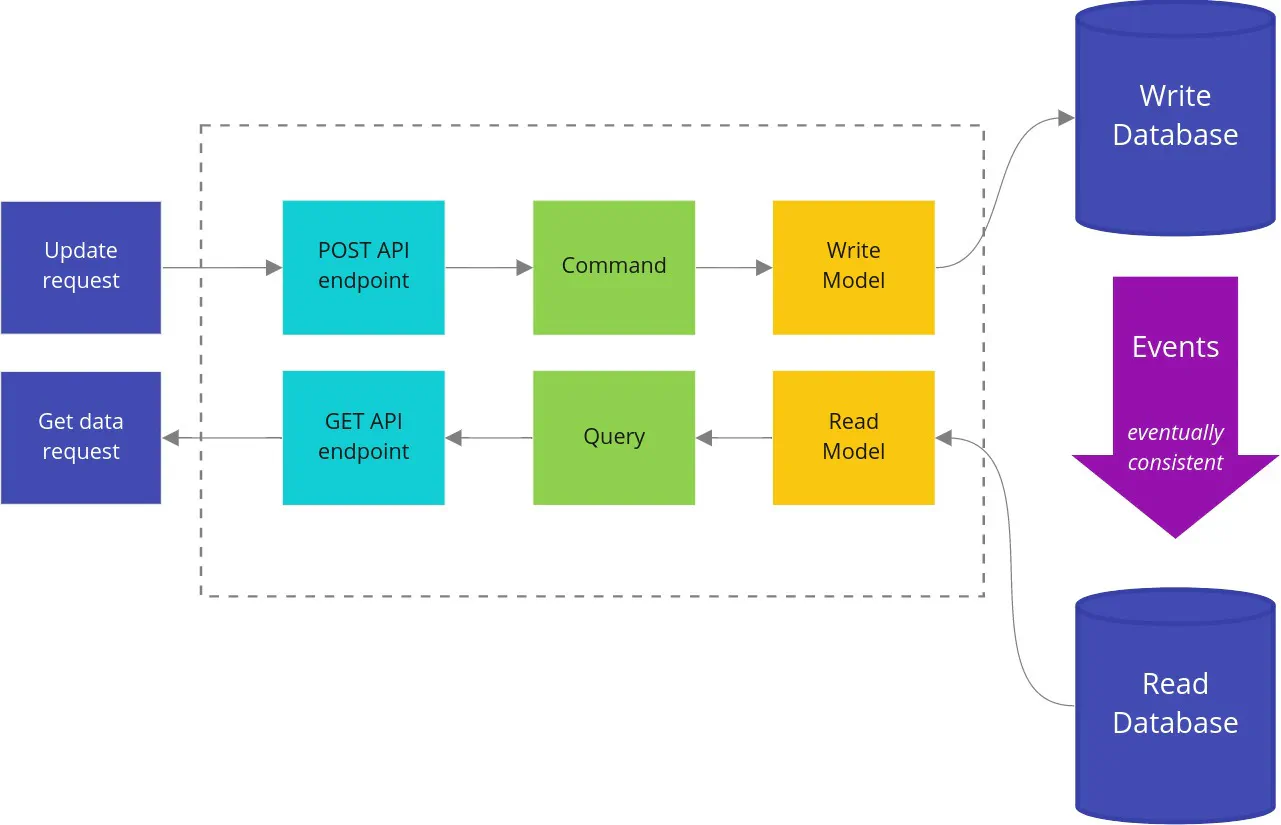
CQRS (Command Query Responsibility Segregation) was initially described by Greg Young. It has one simple assumption: instead of having one big model for reads and writes, you should have two separate models. One for writes and one for reads. It also introduces concepts of command and query, and leads to splitting application services into two separate types: command and query handlers.
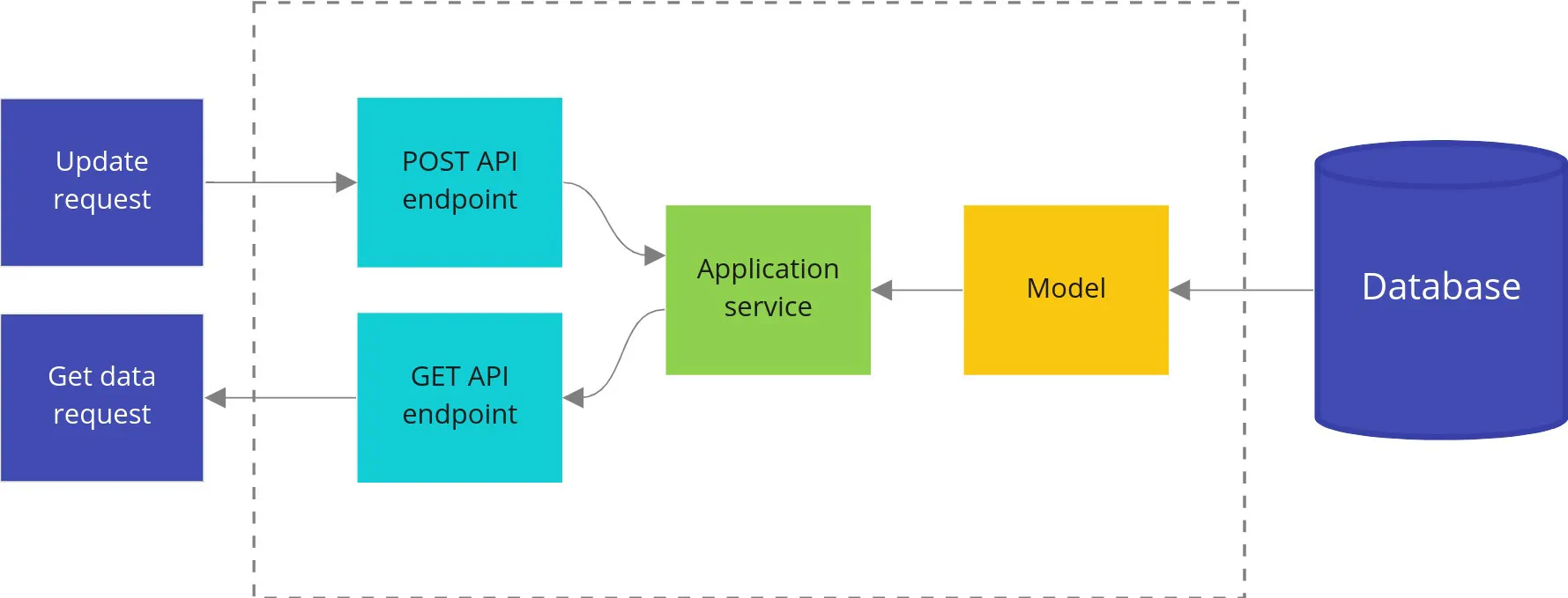
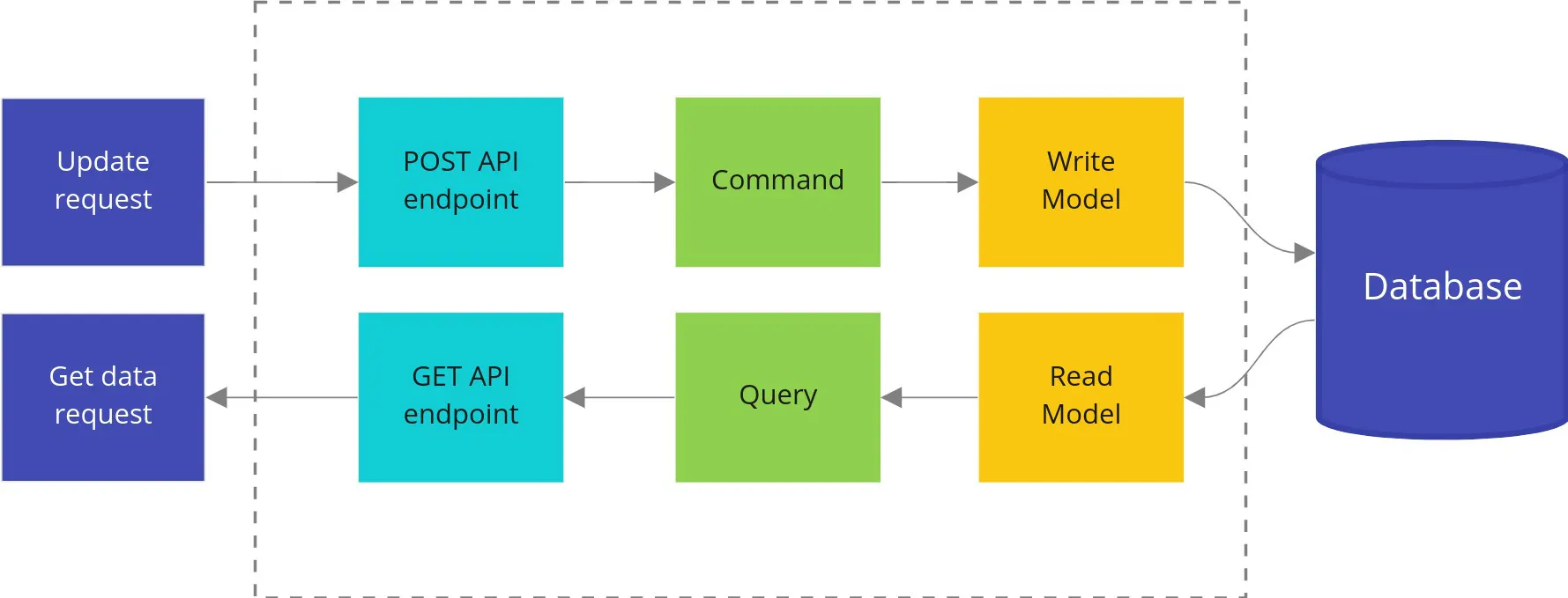
Command vs Query
In the simplest terms: a Query should not modify anything, just return data. A command is the opposite: it should make changes in the system but not return any data. This lets us cache queries more efficiently and reduces the complexity of commands.
This may sound like a serious constraint, but in practice, it’s not. Most operations are either reads or writes. Very rarely both.
Of course, for a query, we don’t consider side effects like logs or metrics as modifying anything. For commands, returning an error is perfectly normal.
Note
As with most rules, it’s okay to break them… as long as you understand why they were introduced and what tradeoffs you’re making. In practice, you rarely need to break these rules. I’ll share examples at the end of the article.
What does the most basic implementation look like in practice? In the previous article, Miłosz introduced an application service that executes application use cases. Let’s start by cutting this service into separate command and query handlers.
ApproveTrainingReschedule command
Previously, the training reschedule was approved from the application service TrainingService.
- func (c TrainingService) ApproveTrainingReschedule(ctx context.Context, user auth.User, trainingUUID string) error {
- return c.repo.ApproveTrainingReschedule(ctx, trainingUUID, func(training Training) (Training, error) {
- if training.ProposedTime == nil {
- return Training{}, errors.New("training has no proposed time")
- }
- if training.MoveProposedBy == nil {
- return Training{}, errors.New("training has no MoveProposedBy")
- }
- if *training.MoveProposedBy == "trainer" && training.UserUUID != user.UUID {
- return Training{}, errors.Errorf("user '%s' cannot approve reschedule of user '%s'", user.UUID, training.UserUUID)
- }
- if *training.MoveProposedBy == user.Role {
- return Training{}, errors.New("reschedule cannot be accepted by requesting person")
- }
-
- training.Time = *training.ProposedTime
- training.ProposedTime = nil
-
- return training, nil
- })
- }
There were some magic validations there.
These are now done in the domain layer.
I also found that we forgot to call the external trainer service to move the training. Oops. 😉
Let’s refactor it to the CQRS approach.
Note
Because CQRS works best with applications following Domain-Driven Design, I also refactored existing models to DDD Lite during the CQRS refactoring. DDD Lite is described in more detail in the previous article.
We start implementing a command with the command structure definition. This structure provides all data needed to execute the command. If a command has only one field, you can skip the structure and just pass it as a parameter.
It’s a good idea to use domain-defined types in the command, like training.User in this case.
We don’t need to do any casting later, and we have type safety assured.
It can save us a lot of issues with string parameters passed in wrong order.
package command
// ...
type ApproveTrainingReschedule struct {
TrainingUUID string
User training.User
}
The second part is a command handler that executes the command.
package command
// ...
type ApproveTrainingRescheduleHandler struct {
repo training.Repository
userService UserService
trainerService TrainerService
}
// ...
func (h ApproveTrainingRescheduleHandler) Handle(ctx context.Context, cmd ApproveTrainingReschedule) (err error) {
defer func() {
logs.LogCommandExecution("ApproveTrainingReschedule", cmd, err)
}()
return h.repo.UpdateTraining(
ctx,
cmd.TrainingUUID,
cmd.User,
func(ctx context.Context, tr *training.Training) (*training.Training, error) {
originalTrainingTime := tr.Time()
if err := tr.ApproveReschedule(cmd.User.Type()); err != nil {
return nil, err
}
err := h.trainerService.MoveTraining(ctx, tr.Time(), originalTrainingTime)
if err != nil {
return nil, err
}
return tr, nil
},
)
}
The flow is now much easier to understand.
You can clearly see that we approve a reschedule of a persisted *training.Training, and if it succeeds, we call the external trainer service.
Thanks to techniques described in the DDD Lite article, the command handler doesn’t need to know when it can perform this operation.
The domain layer handles all of that.
This clear flow is even more visible in complex commands. Fortunately, the current implementation is straightforward. That’s good. Our goal is to create simple software, not complicated software.
If CQRS is the standard way of building applications in your team, it also speeds up onboarding teammates unfamiliar with a service. You just need a list of available commands and queries and a quick look at how their execution works. No more jumping through random places in code.
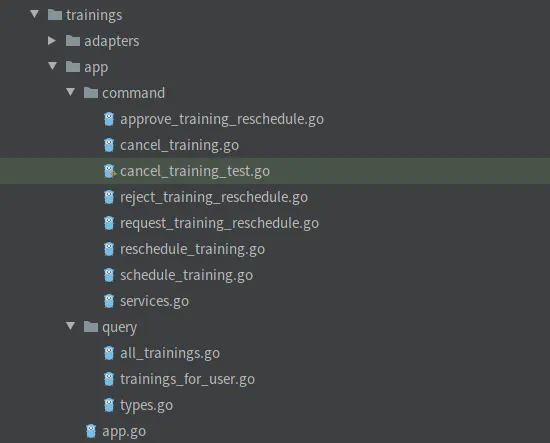
This is how it looks in one of my team’s most complex services:
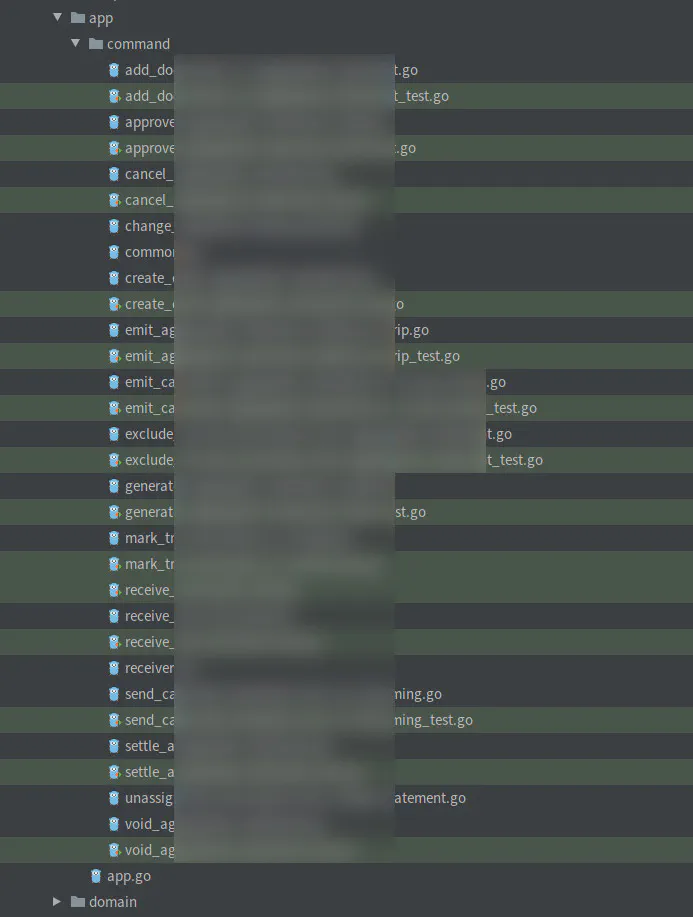
You may ask: shouldn’t it be split into multiple services? In practice, that would be a terrible idea. Many operations here need to be transactionally consistent. Splitting into separate services would involve several distributed transactions (Sagas). This would make the flow much more complex, harder to maintain, and harder to debug. It’s not a good tradeoff.
It’s also worth mentioning that none of these operations are very complex. Complexity scales horizontally here. We will cover the important topic of splitting microservices in-depth soon. Did I mention that we messed it up in Wild Workouts on purpose? 😉
Join over 18k subscribers of our newsletter and get a free e-book!

Go With The Domain Three Dots Labs
But let’s go back to our command. It’s time to use it in our HTTP port.
It’s available in HttpServer via the injected Application structure, which contains all of our command and query handlers.
package app
import (
"github.com/ThreeDotsLabs/wild-workouts-go-ddd-example/internal/trainings/app/command"
"github.com/ThreeDotsLabs/wild-workouts-go-ddd-example/internal/trainings/app/query"
)
type Application struct {
Commands Commands
Queries Queries
}
type Commands struct {
ApproveTrainingReschedule command.ApproveTrainingRescheduleHandler
CancelTraining command.CancelTrainingHandler
// ...
type HttpServer struct {
app app.Application
}
// ...
func (h HttpServer) ApproveRescheduleTraining(w http.ResponseWriter, r *http.Request) {
trainingUUID := chi.URLParam(r, "trainingUUID")
user, err := newDomainUserFromAuthUser(r.Context())
if err != nil {
httperr.RespondWithSlugError(err, w, r)
return
}
err = h.app.Commands.ApproveTrainingReschedule.Handle(r.Context(), command.ApproveTrainingReschedule{
User: user,
TrainingUUID: trainingUUID,
})
if err != nil {
httperr.RespondWithSlugError(err, w, r)
return
}
}
The command handler can be called this way from any port: HTTP, gRPC, or CLI. It’s also useful for executing migrations and loading fixtures (we already do this in Wild Workouts).
RequestTrainingReschedule command
Some command handlers can be very simple.
func (h RequestTrainingRescheduleHandler) Handle(ctx context.Context, cmd RequestTrainingReschedule) (err error) {
defer func() {
logs.LogCommandExecution("RequestTrainingReschedule", cmd, err)
}()
return h.repo.UpdateTraining(
ctx,
cmd.TrainingUUID,
cmd.User,
func(ctx context.Context, tr *training.Training) (*training.Training, error) {
if err := tr.UpdateNotes(cmd.NewNotes); err != nil {
return nil, err
}
tr.ProposeReschedule(cmd.NewTime, cmd.User.Type())
return tr, nil
},
)
}
It may be tempting to skip this layer for such simple cases to save some boilerplate. That’s true, but remember that writing code is always much cheaper than maintenance. Adding this simple type takes 3 minutes. People who read and extend this code later will appreciate that effort.
AvailableHoursHandler query
Queries in the application layer are usually boring.
In the most common case, we need to write a read model interface (AvailableHoursReadModel) that defines how we query the data.
Commands and queries are also a great place for cross-cutting concerns, like logging and instrumentation. By putting them here, we ensure that performance is measured consistently whether called from the HTTP or gRPC port.
package query
// ...
type AvailableHoursHandler struct {
readModel AvailableHoursReadModel
}
type AvailableHoursReadModel interface {
AvailableHours(ctx context.Context, from time.Time, to time.Time) ([]Date, error)
}
// ...
type AvailableHours struct {
From time.Time
To time.Time
}
func (h AvailableHoursHandler) Handle(ctx context.Context, query AvailableHours) (d []Date, err error) {
start := time.Now()
defer func() {
logrus.
WithError(err).
WithField("duration", time.Since(start)).
Debug("AvailableHoursHandler executed")
}()
if query.From.After(query.To) {
return nil, errors.NewIncorrectInputError("date-from-after-date-to", "Date from after date to")
}
return h.readModel.AvailableHours(ctx, query.From, query.To)
}
We also need to define data types returned by the query. In our case, it’s query.Date.
Note
To understand why we don’t use structures generated from OpenAPI, you should check our articles on DRY and Clean Architecture.
package query
import (
"time"
)
type Date struct {
Date time.Time
HasFreeHours bool
Hours []Hour
}
type Hour struct {
Available bool
HasTrainingScheduled bool
Hour time.Time
}
Our query model is more complex than the domain hour.Hour type.
This is a common scenario. Often, it’s driven by the website’s UI, and it’s more efficient to generate optimal responses on the backend side.
As the application grows, differences between domain and query models may increase. Thanks to this separation and decoupling, we can make changes to each independently. This is critical for maintaining fast development in the long term.
package hour
type Hour struct {
hour time.Time
availability Availability
}
But where does AvailableHoursReadModel get the data?
For the application layer, this is fully transparent and not relevant.
This allows us to add performance optimizations in the future while touching just one part of the application.
Note
If you are not familiar with the concept of _ports and adapters_, I highly recommend reading our article about Clean Architecture in Go.
In practice, the current implementation gets data from our write models database.
You can find the AllTrainings read model implementation and tests for DatesFirestoreRepository in the adapters layer.
If you’ve read about CQRS before, you may have seen recommendations to use a separate database built from events for queries. This can be a good idea, but only in very specific cases. I’ll describe this in the Future optimizations section. In our case, getting data from the write models database is sufficient.
HourAvailabilityHandler query
We don’t need to add a read model interface for every query. It’s also fine to use the domain repository and pick the data we need.
import (
"context"
"time"
"github.com/ThreeDotsLabs/wild-workouts-go-ddd-example/internal/trainer/domain/hour"
)
type HourAvailabilityHandler struct {
hourRepo hour.Repository
}
func (h HourAvailabilityHandler) Handle(ctx context.Context, time time.Time) (bool, error) {
hour, err := h.hourRepo.GetHour(ctx, time)
if err != nil {
return false, err
}
return hour.IsAvailable(), nil
}
Naming
Naming is one of the most challenging and essential parts of software development. In Introduction to DDD Lite article, I described a rule that says you should stick to language that is as close as possible to how non-technical people (often called “business”) talk. This also applies to command and query names.
You should avoid names like “Create training” or “Delete training”. This is not how business and users understand your domain. You should instead use “Schedule training” and “Cancel training”.
We will cover this topic more deeply in an article about Ubiquitous Language. Until then, talk to your business people and listen to how they describe operations. Think twice about whether any of your command names really need to start with “Create/Delete/Update”.
Future optimizations
Basic CQRS gives advantages like better code organization, decoupling, and simpler models. There is also one even more important advantage: the ability to extend CQRS with more powerful and complex patterns.
Async commands
Some commands are slow by nature. They may be making external calls or doing heavy computation. In these cases, we can introduce an Asynchronous Command Bus, which executes the command in the background.
Using asynchronous commands has additional infrastructure requirements, like having a queue or pub/sub. Fortunately, the Watermill library can help you handle this in Go. You can find more details in the Watermill CQRS documentation. (By the way, we are the authors of Watermill as well. 😉 Feel free to contact us if something’s not clear there!)
A separate database for queries
Our current implementation uses the same database for reads (queries) and writes (commands). If we needed to provide more complex queries or have really fast reads, we could use the polyglot persistence technique. The idea is to duplicate queried data in a more optimal format in another database. For example, we could use Elasticsearch to index data that can be searched and filtered more easily.
In this case, data synchronization can be done via events. One of the most important implications of this approach is eventual consistency. You should ask yourself if it’s an acceptable tradeoff in your system. If you’re not sure, you can start without polyglot persistence and migrate later. It’s good to defer key decisions like this one.
An example implementation is described in the Watermill CQRS documentation as well. Maybe with time, we will introduce it also in Wild Workouts, who knows?
Event-Sourcing
If you work in a domain with strict audit requirements, you should definitely check out the event sourcing technique. For example, I’m currently working in the financial domain, and event sourcing is our default persistence choice. It provides out-of-the-box auditing and helps with reverting the effects of bugs.
CQRS is often described together with event sourcing. The reason is that by design, event-sourced systems don’t store the model in a format ready for reads (queries), but just a list of events used by writes (commands). In other words, it’s harder to provide API responses.
Thanks to the separation of command and query models, this isn’t a big problem. Our read models for queries live independently by design.
There are many more advantages of event sourcing that are visible in financial systems. But let’s leave that for another article. 😉 Until then, you can check out the ebook by Greg Young: Versioning in an Event Sourced System. The same Greg Young who described CQRS.
When to not use CQRS?
CQRS is not a silver bullet that fits everywhere. A good example is authentication. You provide a login and password, and in return, you get confirmation of success and maybe a token.
If your application is a simple CRUD that receives and returns the same data, it’s also not the best fit for CQRS.
That’s why the users microservice in Wild Workouts doesn’t use Clean Architecture and CQRS.
In simple, data-oriented services, these patterns usually don’t make sense.
On the other hand, you should keep an eye on such services.
If you notice the logic growing and development becoming painful, maybe it’s time for some refactoring?
Returning created entity via API with CQRS
I know some people struggle with using CQRS for REST APIs that return the created entity as the response to a POST request. Isn’t that against CQRS? Not really! You can solve it in two ways:
- Call the command in the HTTP port and, after it succeeds, call the query to get the data to return.
- Instead of returning the created entity, return a
204HTTP code with thecontent-locationheader set to the created resource URL.
The second approach is better in my opinion because it doesn’t require always querying for the created entity (even if the client doesn’t need the data). With the second approach, the client only follows the link if needed. That call can also be cached.
The only question is: how do you get the created entity’s ID? A common practice is to provide the UUID of the entity to be created in the command.
This approach has the advantage of still working as expected if the command handler is asynchronous. If you don’t want to work with UUIDs, as a last resort you can return the ID from the handler. It won’t be the end of the world. 😉
cmd := command.ScheduleTraining{
TrainingUUID: uuid.New().String(),
UserUUID: user.UUID,
UserName: user.DisplayName,
TrainingTime: postTraining.Time,
Notes: postTraining.Notes,
}
err = h.app.Commands.ScheduleTraining.Handle(r.Context(), cmd)
if err != nil {
httperr.RespondWithSlugError(err, w, r)
return
}
w.Header().Set("content-location", "/trainings/" + cmd.TrainingUUID)
w.WriteHeader(http.StatusNoContent)
You can now put CQRS in your resume!
We did it: we have a basic CQRS implementation in Wild Workouts. You should also have an idea of how to extend the application in the future.
While preparing the code for this article, I also refactored the trainer service towards DDD.
I will cover this in the next article.
The entire diff of that refactoring is already available on our GitHub repository.
Having every command handler as a separate type also helps with testing because it’s easier to build dependencies for them. This part is covered by Miłosz in Microservices Test Architecture.
Are you using CQRS with any extensions? Do you have any project where you don’t know how to apply these patterns? Feel free to share and ask in the comments!