A complete Terraform setup of a serverless application on Google Cloud Run and Firebase

We picked Google Cloud Platform (GCP) as the provider of all infrastructure parts of the project. We use Cloud Run for running Go services, Firestore as the database, Cloud Build as CI/CD, and Firebase for web hosting and authentication. The project is based on Terraform.
Infrastructure as Code
If you’re not familiar with Terraform, it’s a tool for storing infrastructure configuration as text files. This technique is also known as “Infrastructure as Code”. It’s a broad topic, so I’ll mention just a few benefits:
- Storing infrastructure configuration in a repository. This gives you all the benefits of version control: commit history, a single source of truth, and code reviews.
- Consistency over time. Ideally, there are no manual changes to infrastructure other than those described in the configuration.
- Multiple environments. When you stop treating your servers as pets, it’s much easier to create identical environments, sometimes even on demand.
Terraform 101
You can skip this part if you already know Terraform basics.
In Terraform, you define a set of resources in .tf files using HCL syntax. A resource can be a database, network configuration, compute instance, or even a set of permissions. Available resource types depend on the provider you use (e.g., AWS, GCP, Digital Ocean).
All resources are defined declaratively. You don’t write pseudocode that creates servers. Instead, you define the desired outcome. It’s up to Terraform to figure out how to configure what you specified. For example, it’s smart enough to create a resource only if it doesn’t exist.
Resources can refer to each other using the full name.
Besides resources, a project can also specify input variables to be filled by the user and output values that can be printed on the screen or stored in a file.
There are also data sources that don’t create anything but read existing remote resources.
You can find all the available resources in the specific provider documentation. Here’s an example for Google Cloud Platform.
Two basic commands that you need to know are terraform plan and terraform apply.
apply applies all resources defined in the current directory across all files with the .tf extension. The plan command is a “dry-run” mode that prints all changes that would be applied by apply.
After applying changes, you will find a terraform.tfstate file in the same directory. This file holds a local “state” of your infrastructure.
Google Cloud Project
Our Terraform configuration creates a new GCP project. It’s completely separated from your other projects and is easy to clean up.
Because some resources go beyond the free tier, you need a Billing Account. It can be an account with a linked credit card, but the $300 credit for new accounts also works.
The basic part of the project definition looks like this:
provider "google" {
project = var.project
region = var.region
}
data "google_billing_account" "account" {
display_name = var.billing_account
}
resource "google_project" "project" {
name = "Wild Workouts"
project_id = var.project
billing_account = data.google_billing_account.account.id
}
resource "google_project_iam_member" "owner" {
role = "roles/owner"
member = "user:${var.user}"
depends_on = [google_project.project]
}
Let’s consider what each block does:
- Enables the GCP provider. Sets project name and chosen region from variables. These two fields are “inherited” by all resources unless overridden.
- Finds a billing account with the display name provided by the variable.
- Creates a new google project linked with the billing account. Note the reference to the account ID.
- Adds your user as the owner of the project. Note the string interpolation.
Enabling APIs
On a fresh GCP project, you can’t use most services right away. You first have to enable the API for each of them. You can enable an API by clicking a button in the GCP Console or do the same in Terraform:
resource "google_project_service" "compute" {
service = "[compute.googleapis.com](http://compute.googleapis.com/)"
depends_on = [google_project.project]
}
We enable the following APIs:
- Cloud Source Repositories
- Cloud Build
- Container Registry
- Compute
- Cloud Run
- Firebase
- Firestore
A note on dependencies
If you’re wondering about the depends_on line, it sets an explicit dependency between the service and the project.
Terraform detects dependencies between resources if they refer to each other. In the first snippet, you can see this with the billing account that’s referenced by the project:
data "google_billing_account" "account" {
display_name = var.billing_account
}
resource "google_project" "project" {
# ...
billing_account = data.google_billing_account.account.id
}
In the google_project_service resource, we don’t use project anywhere because it’s already set in the provider block. Instead, we use depends_on to specify an explicit dependency. This line tells Terraform to wait before creating the resource until the project is correctly created.
Join over 18k subscribers of our newsletter and get a free e-book!

Go With The Domain Three Dots Labs
Cloud Run
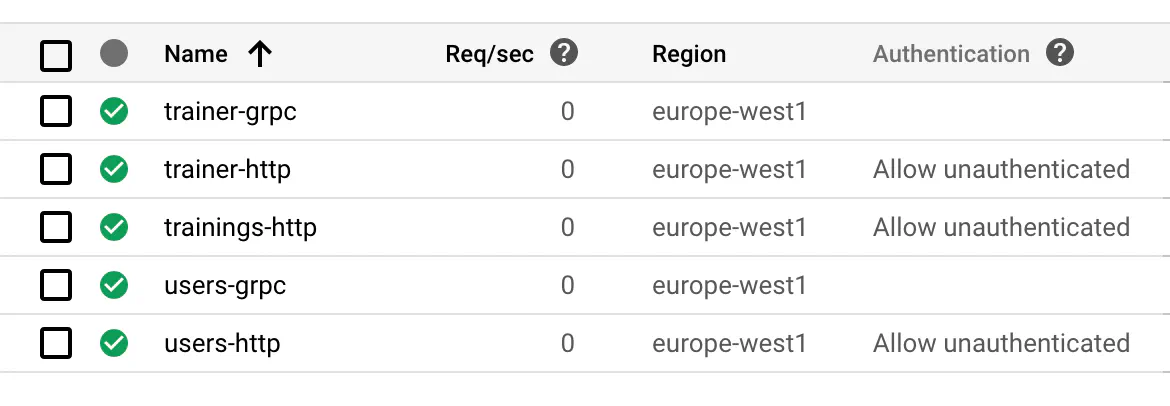
In Cloud Run, a service is a set of Docker containers with a common endpoint, exposing a single port (HTTP or gRPC). Each service is automatically scaled, depending on the incoming traffic. You can choose the maximum number of containers and how many requests each container can handle.
It’s also possible to connect services with Google Cloud Pub/Sub. Our project doesn’t use it yet, but we will introduce it in future versions.
You are charged only for the computing resources you use, so when a request is being processed or when the container starts.
Wild Workouts consists of 3 services: trainer, trainings, and users. We decided to serve public API with HTTP and internal API with gRPC.
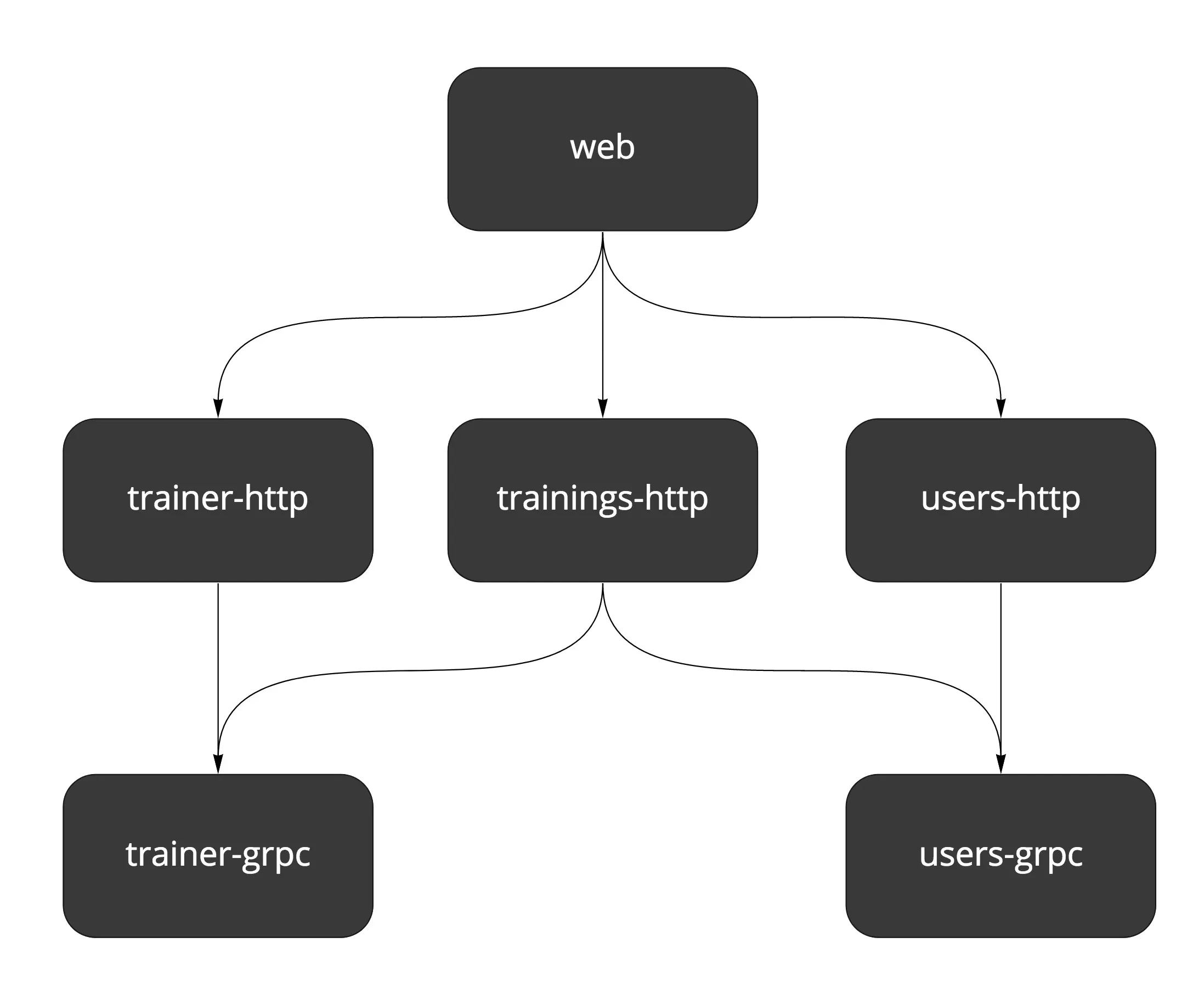
Because you can’t expose two separate ports from a single service, we have to expose two containers per service (except trainings, which doesn’t have an internal API at the moment).
We deploy 5 services in total, each with a similar configuration. Following the DRY principle, the common Terraform configuration is encapsulated in the service module.
Note
A Module in Terraform is a separate set of files in a subdirectory. Think of it as a container for a group of resources. It can have its own input variables and output values.
Any module can call other modules by using the module block and passing a path to the directory in the source field. A single module can be called multiple times.
Resources defined in the main working directory are considered to be in a root module.
The module holds a definition of a single generic Cloud Run service and is used multiple times in cloud-run.tf. It exposes several variables, e.g., name and type of the server (HTTP or gRPC).
A service exposing gRPC is the simpler one:
module cloud_run_trainer_grpc {
source = "./service"
project = var.project
location = var.region
dependency = null_resource.init_docker_images
name = "trainer"
protocol = "grpc"
}
The protocol is passed to the SERVER_TO_RUN environment variable, which decides what server is run by the service.
Compare this with an HTTP service definition. We use the same module, but with additional environment variables. We need to add them because public services contact internal services via the gRPC API and need to know their addresses.
module cloud_run_trainings_http {
source = "./service"
project = var.project
location = var.region
dependency = null_resource.init_docker_images
name = "trainings"
protocol = "http"
auth = false
envs = [
{
name = "TRAINER_GRPC_ADDR"
value = module.cloud_run_trainer_grpc.endpoint
},
{
name = "USERS_GRPC_ADDR"
value = module.cloud_run_users_grpc.endpoint
}
]
}
The reference: module.cloud_run_trainer_grpc.endpoint points to endpoint output defined in the service module:
output endpoint {
value = "${trimprefix(google_cloud_run_service.service.status[0].url, "https://")}:443"
}
Using environment variables is an easy way to make services aware of each other. With more complex connections and more services, it would probably be best to implement some kind of service discovery. We may cover this in a future post.
If you’re curious about the dependency variable, see In-depth below for details.
Cloud Run Permissions
Cloud Run services have authentication enabled by default. Setting the auth = false variable in the service module adds additional IAM policy for the service, making it accessible for the public. We do this just for the HTTP APIs.
data "google_iam_policy" "noauth" {
binding {
role = "roles/run.invoker"
members = [
"allUsers",
]
}
}
resource "google_cloud_run_service_iam_policy" "noauth_policy" {
count = var.auth ? 0 : 1
location = google_cloud_run_service.service.location
service = google_cloud_run_service.service.name
policy_data = data.google_iam_policy.noauth.policy_data
}
Note the following line:
count = var.auth ? 0 : 1
This line is Terraform’s way of making an if statement. count defines how many copies of a resource Terraform should create.
It skips resources with a count of 0.
Firestore
We picked Firestore as the database for Wild Workouts. See our first post for reasons behind this.
Note
Since writing this article, our recommendation has changed: just use PostgreSQL. It’s easier to operate and simpler to migrate between cloud providers if needed. See the State of this article in 2026 note in our first post for more context.
Firestore works in two modes: Native or Datastore. You have to decide early on, as the choice is permanent after your first write to the database.
You can pick the mode in the GCP Console GUI, but we wanted to make the setup fully automated. In Terraform, there’s a google_project_service resource available, but it enables Datastore mode. Sadly, we can’t use it since we want to use Native mode.
A workaround is to use the gcloud command to enable it (note the alpha version).
gcloud alpha firestore databases create
To run this command, we use the null resource. It’s a special kind of resource that lets you run custom provisioners locally or on remote servers. A provisioner is a command or other software that makes changes to the system.
We use local-exec provisioner, which is simply executing a bash command on the local system. In our case, it’s one of the targets defined in Makefile.
resource "null_resource" "enable_firestore" {
provisioner "local-exec" {
command = "make firestore"
}
depends_on = [google_firebase_project_location.default]
}
Firestore requires creating all composite indexes upfront. It’s also available as a Terraform resource.
resource "google_firestore_index" "trainings_user_time" {
collection = "trainings"
fields {
field_path = "UserUuid"
order = "ASCENDING"
}
fields {
field_path = "Time"
order = "ASCENDING"
}
fields {
field_path = "__name__"
order = "ASCENDING"
}
depends_on = [null_resource.enable_firestore]
}
Note the explicit depends_on that points to the null_resource creating database.
Firebase
Firebase provides us with frontend application hosting and authentication.
Currently, Terraform supports only part of Firebase API, and some of it is still in beta. That’s why we need to enable the google-beta provider:
provider "google-beta" {
project = var.project
region = var.region
credentials = base64decode(google_service_account_key.firebase_key.private_key)
}
Then we define the project, project’s location and the web application.
resource "google_firebase_project" "default" {
provider = google-beta
depends_on = [
google_project_service.firebase,
google_project_iam_member.service_account_firebase_admin,
]
}
resource "google_firebase_project_location" "default" {
provider = google-beta
location_id = var.firebase_location
depends_on = [
google_firebase_project.default,
]
}
resource "google_firebase_web_app" "wild_workouts" {
provider = google-beta
display_name = "Wild Workouts"
depends_on = [google_firebase_project.default]
}
Authentication management still lacks a Terraform API, so you have to enable it manually in the Firebase Console. Firebase authentication is the only thing we found no way to automate.
Firebase Routing
Firebase also handles public routing to services. Thanks to this the frontend application can call API with /api/trainer instead of https://trainer-http-smned2eqeq-ew.a.run.app. These routes are defined in web/firebase.json.
"rewrites": [
{
"source": "/api/trainer{,/**}",
"run": {
"serviceId": "trainer-http",
"region": "europe-west1"
}
},
// ...
]
Cloud Build
Cloud Build is our Continuous Delivery pipeline. It has to be enabled for a repository, so we define a trigger in Terraform and the repository itself.
resource "google_sourcerepo_repository" "wild_workouts" {
name = var.repository_name
depends_on = [
google_project_service.source_repo,
]
}
resource "google_cloudbuild_trigger" "trigger" {
trigger_template {
branch_name = "master"
repo_name = google_sourcerepo_repository.wild-workouts.name
}
filename = "cloudbuild.yaml"
}
The build configuration has to be defined in the cloudbuild.yaml file committed to the repository. We defined a couple of steps in the pipeline:
- Linting (go vet): this step could be extended in the future with running tests and all kinds of static checks and linters
- Building docker images
- Deploying docker images to Cloud Run
- Deploying web app to Firebase hosting
We keep several services in one repository, and their building and deployment are almost the same. To reduce repetition, there are a few helper bash scripts in the scripts directory.
Note
Should I use a monorepo?
We decided to keep all services in one repository. We did this mainly because Wild Workouts is an example project, and it’s much easier to set up everything this way. We can also easily share common code (e.g., setting up gRPC and HTTP servers).
From our experience, using a single repository is a great starting point for most projects. It’s essential, though, that all services are entirely isolated from each other. If needed, we could easily split them into separate repositories. We might show this in future articles in this series.
The biggest disadvantage of the current setup is that all services and the frontend application are deployed at the same time. That’s usually not what you want when working with microservices with a bigger team. But it’s probably acceptable when you’re just starting out and creating an MVP.
As usual in CI/CD tools, the Build configuration is defined in YAML. Let’s see the whole configuration for just one service, to reduce some noise.
steps:
- id: trainer-lint
name: golang
entrypoint: ./scripts/lint.sh
args: [trainer]
- id: trainer-docker
name: gcr.io/cloud-builders/docker
entrypoint: ./scripts/build-docker.sh
args: ["trainer", "$PROJECT_ID"]
waitFor: [trainer-lint]
- id: trainer-http-deploy
name: gcr.io/cloud-builders/gcloud
entrypoint: ./scripts/deploy.sh
args: [trainer, http, "$PROJECT_ID"]
waitFor: [trainer-docker]
- id: trainer-grpc-deploy
name: gcr.io/cloud-builders/gcloud
entrypoint: ./scripts/deploy.sh
args: [trainer, grpc, "$PROJECT_ID"]
waitFor: [trainer-docker]
options:
env:
- 'GO111MODULE=on'
machineType: 'N1_HIGHCPU_8'
images:
- 'gcr.io/$PROJECT_ID/trainer'
A single step definition is pretty short:
idis a unique identifier of a step. It can be used inwaitForarray to specify dependencies between steps (steps are running in parallel by default).nameis the name of a docker image that will be run for this step.entrypointworks like in Docker images, so it’s a command that executes when the container starts. We use bash scripts to keep the YAML definition short, but this can be any bash command.argswill be passed toentrypointas arguments.
In options, we override the machine type to make our builds run faster. There’s also an environment variable to force the use of Go modules.
The images list defines Docker images that should be pushed to Container Registry. In the example above, the Docker image is built in the trainer-docker step.
Deploys
Deploys to Cloud Run use the gcloud run deploy command. Cloud Build builds the Docker image in the previous step, so we can use the latest image from the registry.
- id: trainer-http-deploy
name: gcr.io/cloud-builders/gcloud
entrypoint: ./scripts/deploy.sh
args: [trainer, http, "$PROJECT_ID"]
waitFor: [trainer-docker]
gcloud run deploy "$service-$server_to_run" \
--image "gcr.io/$project_id/$service" \
--region europe-west1 \
--platform managed
The frontend is deployed with the firebase command. There’s no need to use a helper script here, as there’s just one frontend application.
- name: gcr.io/$PROJECT_ID/firebase
args: ['deploy', '--project=$PROJECT_ID']
dir: web
waitFor: [web-build]
This step uses the gcr.io/$PROJECT_ID/firebase Docker image. It doesn’t exist by default, so we use another null_resource to build it from cloud-builders-community:
resource "null_resource" "firebase_builder" {
provisioner "local-exec" {
command = "make firebase_builder"
}
depends_on = [google_project_service.container_registry]
}
Cloud Build Permissions
All required permissions are defined in iam.tf. Cloud Build needs permissions for Cloud Run (to deploy backend services) and Firebase (to deploy frontend application).
First, we define account names as local variables to make the file more readable. If you’re wondering where these names come from, you can find them in the Cloud Build documentation.
locals {
cloud_build_member = "serviceAccount:${google_project.project.number}@cloudbuild.gserviceaccount.com"
compute_account = "projects/${var.project}/serviceAccounts/${google_project.project.number}-compute@developer.gserviceaccount.com"
}
We then define all permissions, as described in the documentation. For example, here’s Cloud Build member with Cloud Run Admin role:
resource "google_project_iam_member" "cloud_run_admin" {
role = "roles/run.admin"
member = local.cloud_build_member
depends_on = [google_project_service.cloud_build]
}
Dockerfiles
We have several Dockerfiles defined in the project in the docker directory.
app- Go service image for local development. It uses reflex for hot code recompilation. See our post about local Go environment to learn how it works.app-prod- production image for Go services. It builds the Go binary for a given service and runs it.web- frontend application image for local development.
Setup
Usually, you would execute a Terraform project with terraform apply. This command applies all resources in the current directory.
Our example is a bit more complex because it sets up the whole GCP project along with dependencies. The Makefile orchestrates the setup.
Requirements:
git,gcloud, andterraforminstalled on your system.- Docker
- A GCP account with a Billing Account.
Authentication
There are two credentials that you need for the setup.
Start with logging in with gcloud:
gcloud auth login
Then you need to obtain Application Default Credentials:
gcloud auth application-default login
This stores your credentials in a well-known place, so Terraform can use it.
Note
Security warning!
Authenticating this way is the easiest approach and fine for local development, but you probably don’t want to use it in a production setup.
Instead, consider creating a service account with only the necessary permissions (depending on what your Terraform configuration does). You can then download the JSON key and store its path in the GOOGLE_CLOUD_KEYFILE_JSON environment variable.
Picking a Region
During the setup, you need to pick Cloud Run region and Firebase location. These two are not the same thing (see the lists on linked documentation).
We picked europe-west1 as the default region for Cloud Run. It’s hardcoded on the repository in two files:
scripts/deploy.sh- for deploying the Cloud Run servicesweb/firebase.json- for routing Cloud Run public APIs
If you’re fine with the defaults, you don’t need to change anything. Just pick Firebase location that’s close, i.e., europe-west.
If you’d like to use a different region, you need to update the files mentioned above. It’s important to commit your changes on master before you run the setup. It’s not enough to change them locally!
Run it!
Clone the project repository and enter the terraform directory from the command line. A single make command should be enough to start. See the included README for more details.
Note
Billing warning!
This project goes beyond the Google Cloud Platform free tier. You need to have a billing account to use it. You can use the $300 free credit given to new accounts or create a new account in the Billing section.
For pricing, see Cloud Run Pricing. The best way to estimate your project cost is to use the official calculator.
Wild Workouts should cost you up to $1 per month if you use it just occasionally. We recommend deleting the project after you’re done playing with it.
If you want to run it continuously, you should know that most of the cost comes from Cloud Build and depends on the number of builds (triggered by new commits on master). You can downgrade the machineType in cloudbuild.yaml to reduce some costs at the expense of longer build times.
It’s also a good idea to set up a Budget Alert in the Billing Account settings. You will then receive a notification if something triggers unexpected charges.
At the end of the setup, a new Git remote called google will be added to your local repository. The master branch will be pushed to this remote, triggering your first Cloud Build.
If you’d like to make any changes to the project, you need to push to the correct origin, i.e., git push google. You can also update the origin remote with git remote set-url.
Note
If you keep your code on GitHub, GitLab, or another platform, you can set up a mirror instead of hosting the repository on Cloud Source Repositories.
In-depth
Env variables
All available variables are defined in the vars.tf file. If a variable has no default value and you don’t provide it, Terraform won’t let you apply anything.
There are several ways to supply variables for terraform apply. You can pass them individually with -var flag or all at once with -var-file flag. Terraform also looks for them in TF_VAR_name environment variables.
We’ve picked the last option for this project. We need to use the environment variables anyway in the Makefile and bash scripts. This way, there’s just one source of truth.
Make runs set-envs.sh at the beginning of the setup. It’s a helper script that asks the user for all the required variables. These are then saved to the .env file. You can edit this file manually as well.
Note Terraform does not automatically read it. It’s sourced just before running apply:
load_envs:=source ./.env
# ...
apply:
${load_envs} && terraform apply
Building docker images
Because we’re setting up the project from scratch, we run into a dilemma: we need Docker images in the project’s Container Registry to create Cloud Run instances, but we can’t create the images without a project.
You could set the image name in Terraform definition to an example image and then let Cloud Build overwrite it. But then each terraform apply would try to change them back to the original value.
Our solution is to build the images based on the “hello” image first and then deploy Cloud Run instances. Then Cloud Build builds and deploys proper images, but the name stays the same.
resource "null_resource" "init_docker_images" {
provisioner "local-exec" {
command = "make docker_images"
}
depends_on = [google_project_service.container_registry]
}
Note the depends_on that points at Container Registry API. It ensures Terraform won’t start building images until there’s a registry where it can push them.
Destroying
You can delete the entire project with make destroy. If you take a look in the Makefile, there’s something unusual before terraform destroy:
terraform state rm "google_project_iam_member.owner"
terraform state rm "google_project_service.container_registry"
terraform state rm "google_project_service.cloud_run"
These commands are a workaround for Terraform’s lack of a “skip destroy” feature. They remove some resources from Terraform’s local state file. Terraform won’t destroy these resources because, as far as it’s concerned, they don’t exist at this point.
We don’t want to destroy the owner IAM policy, because if something goes wrong during the destroy, you will lock yourself out of the project and won’t be able to access it.
The other two lines relate to enabled APIs: there’s a possible race condition where some resources would still use these APIs during destroy. By removing them from the state, we avoid this issue.
A note on magic
Our goal was to make it as easy as possible to set up the whole project. Because of that, we had to cut some corners where Terraform is missing features or an API is not yet available. There’s also some Makefile and bash magic involved that’s not always easy to understand.
I want to make this clear because you will likely encounter similar dilemmas in your projects. You will need to choose between fully automated solutions glued together with alpha APIs or plain Terraform with some manual steps documented in the project.
Both approaches have their place. For example, this project is straightforward to set up multiple times with the same configuration. If you’d like to create an exact copy of the production environment, you can have a completely separate project working within minutes.
If you keep just one or two environments, you won’t need to recreate them every week. It’s then probably fine to stick to the available APIs and document the rest.
Is serverless the way to go?
This project is our first approach to “serverless” deployment, and at first, we had some concerns. Is this all just hype, or is serverless the future?
Wild Workouts is a fairly small project that might not show everything Cloud Run has to offer. Overall, we found it quite simple to set up, and it nicely hides all complexities. It’s also more natural to work with than Cloud Functions.
After the initial setup, there shouldn’t be much infrastructure maintenance needed. You don’t have to worry about keeping up a Docker registry or a Kubernetes cluster and can instead focus on creating the application.
On the other hand, it’s also quite limited in features, as only a few protocols are supported. It looks like a great fit for services with a REST API. The pricing model also seems reasonable, as you pay only for the resources you use.
What about vendor lock-in?
The entire Terraform configuration is now tied to GCP, and there’s no way around it. If we wanted to migrate the project to AWS, a new configuration would be needed.
However, there are some universal concepts. Services running in Docker images can be deployed on any platform, whether it’s a Kubernetes cluster or docker-compose. Most platforms also offer some kind of registry for images.
Is writing a new Terraform configuration all that’s required to migrate out of Google? Not really, as the application itself is coupled to Firebase and Authentication offered by GCP. We will show a better approach to this problem in future posts in this series.
What’s next?
This post just scratches the surface of Terraform. There are many advanced topics you should take a look at if you consider using it. For example, the remote state is necessary when working in a team.
I hope this was a solid introduction. If you have any questions, please let us know in the comments below. We might even follow up with full posts to some of them, as the topic is broad enough.
Next week, we’re going to cover gRPC communication. 👋


