When using Microservices or Modular Monolith in Go can be just a detail?

Nowadays we can often hear that monolithic architecture is obsolete and responsible for all evil in IT. We often hear that microservices architecture is a silver bullet which helps to kill all this monolithic evil. But you probably know that there are almost no silver bullets in IT and every decision entails trade-offs.
One of the most favored advantages of microservices architecture is good modules separation. You can deploy every service independently and services are easier to scale. Also, every team can have their own repository and use the technology of their choice. We can easily rewrite the entire service very fast. In return, we get possible network problems, latency, limited bandwidth. You must deal with potential bugs in the communication layer. It is much harder to debug and maintain from the developer and ops perspective. We must keep services API’s contracts up to date and fight with compatibility issues. We also can’t forget about potential performance drawbacks. The overall complexity is greater in many areas, starting with developing and ending in administration.
In summary, regardless of all advantages, it is hard to build good microservices architecture. If you don’t trust my opinion, you can trust this guy:
Almost all the cases where I’ve heard of a system that was built as a microservice system from scratch, it has ended up in serious trouble.
Almost all the successful microservice stories have started with a monolith that got too big and was broken up.
Let’s assume a crazy idea, which will not follow actual trends - we are developing the new application and we want to start with a monolith. Does it mean that we must live with all monolith disadvantages?
Not at all. The truth is that a lot of these problems are usually not because of the monolith architecture, but because of lack of good programming practices and good design.
Let’s look how an example good designed monolith application will look, compared to the microservices architecture version. In this article, we will name it Clean Monolith. Both are built with Clean Architecture rules.
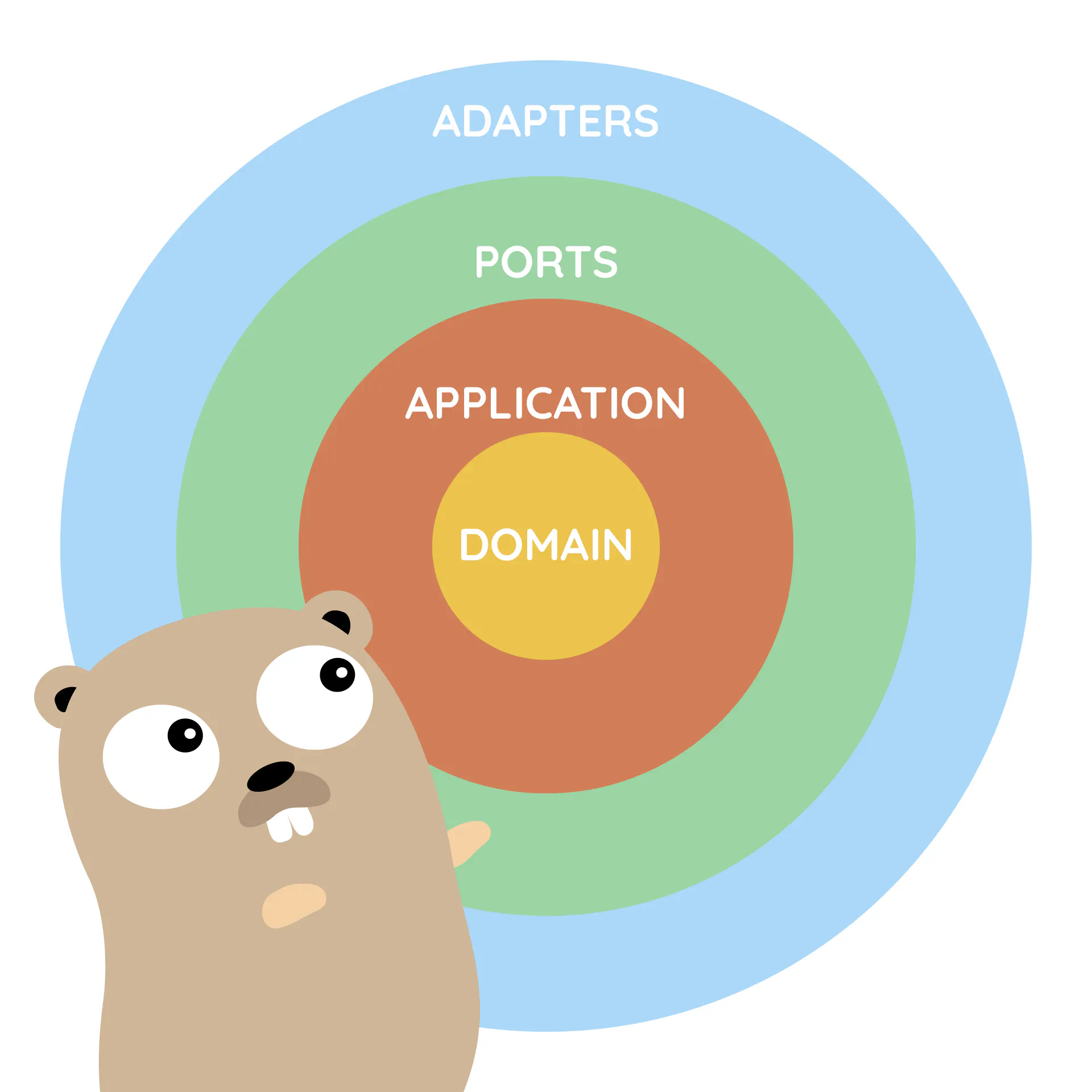
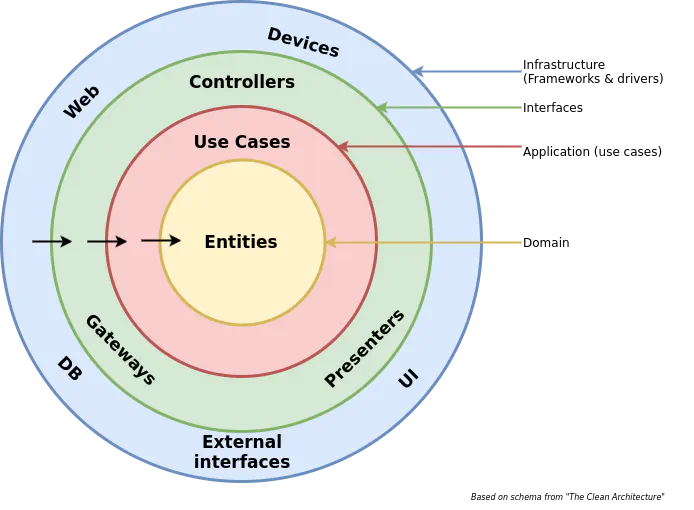
Clean architecture
In a nutshell, Clean architecture assumes that your service should be separated into 4 layers:
- Domain - our domain logic and entities
- Application - some kind of glue for domain layer. For example, get the entity from the repository, call some method on this entity, save the entity in the repository. Also, it should take responsibility for all cross-cutting concerns like logging, transactions, instrumentation etc. It is also responsible for providing views (read models).
- Interfaces - thin layer which allows us to use the application, for example REST API, CLI Interface, Queue, etc.
- Infrastructure - database adapters, rest clients, in general implementation of interfaces from Domain/Application layer.
Note
Clean Architecture is a very similar concept to Hexagonal/Ports and adapters architecture/Onion Architecture of which you could already hear about.
The key concept of clean architecture is that any layer cannot know anything about outside layer. For example, the domain should not be aware of application or infrastructure layer (so it doesn’t know that domain entities are persisted in MySQL for example). Also, the application layer should not be aware of how it is called (REST API, CLI, Queue listener, whatever).
But how to achieve it? The answer is Inversion of Control. In short: hide implementation behind interfaces.
Uncle Bob has already described it pretty good. At the bottom of the article I will provide a link with a full explanation of Clean Architecture.
Monolith vs Microservices
For the purposes of the article let’s use an example of a simple shop. This shop will allow us to: list products, place order, initialize payment in remote payments provider, receive notifications about payments and mark order as paid. Let’s take a look at the architecture diagram.
I’ve created diagrams for both microservices and monolith example. Both are made in the spirit of Clean Architecture.
(click to see in full resolution)
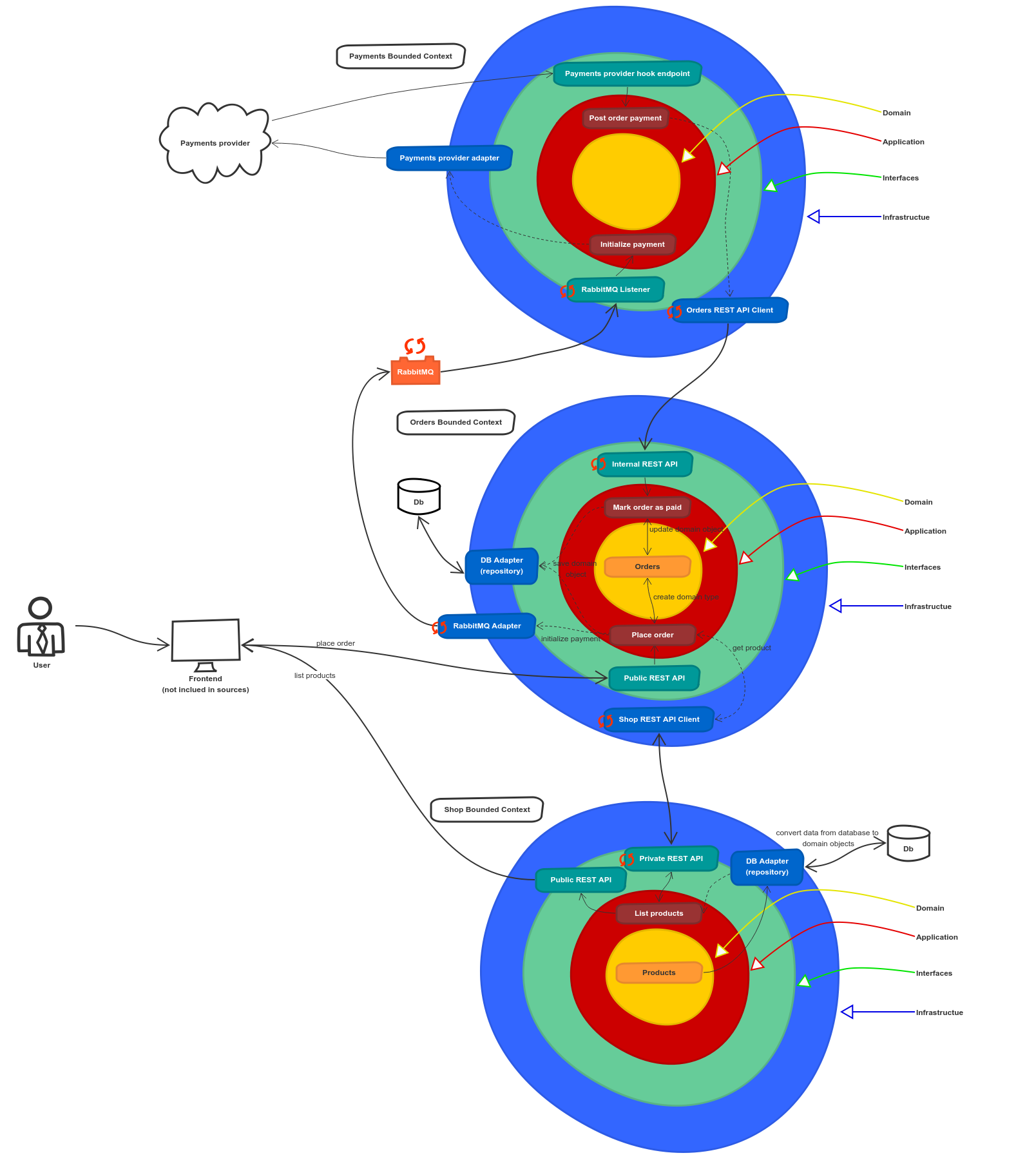
Big picture microservices architecture diagram.
Typically monolith architecture will look like Big Ball of Mud:
Big Ball of Mud.
But when we design architecture with the spirit of Clean Architecture it will look like this:
(click to see in full resolution)
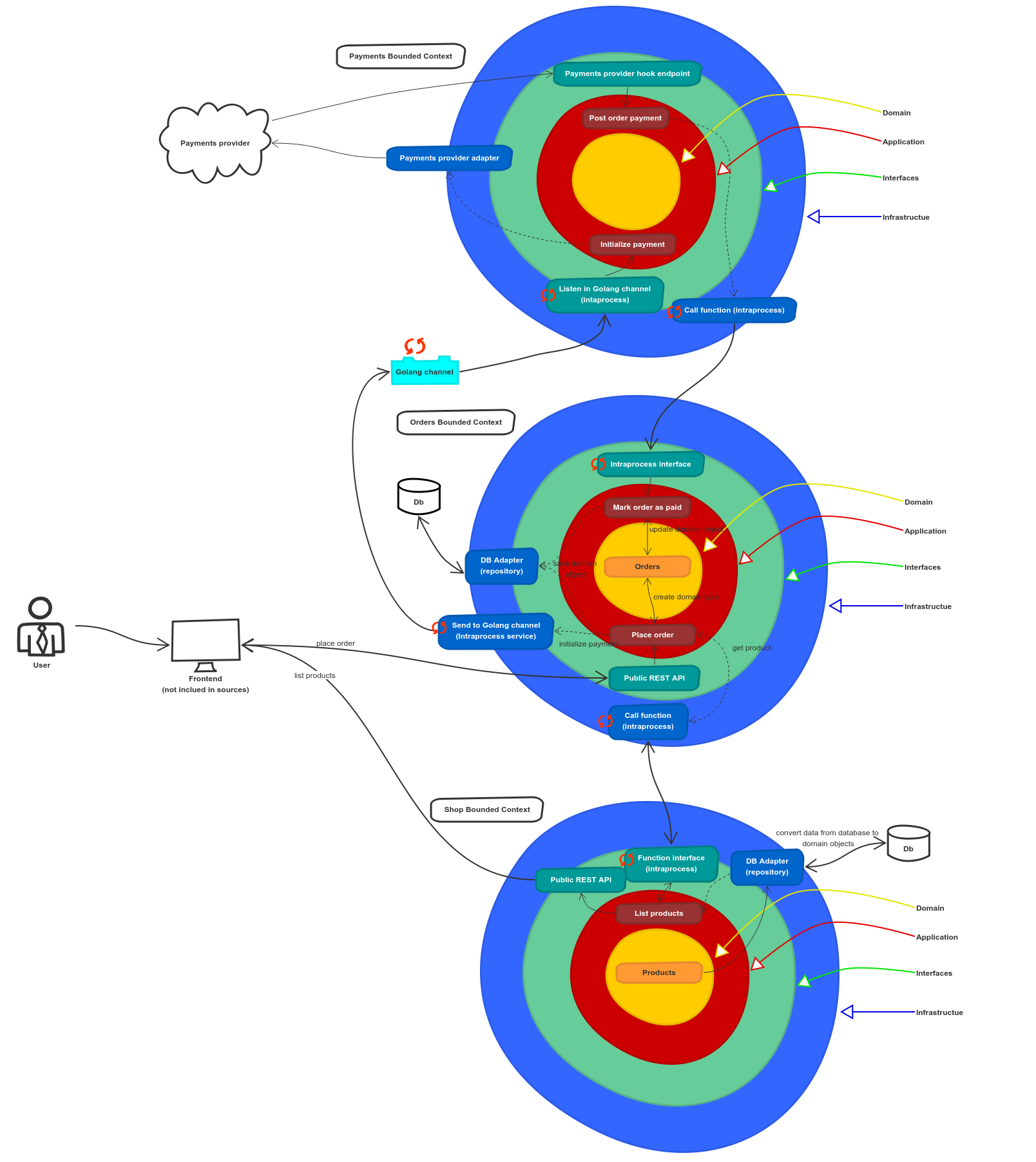
Big picture monolithic architecture diagram.
Do you see differences in this example? If you look closely, you can see that there are only in interfaces/infrastructure layers. The domain and application layers are basically the same (which is expected when we use DDD). I marked differences with orange arrows to make it more visible ;)
Microservices can avoid it because we have a natural barrier between services (for example because of separated repositories), so we have enforced modules separation by design. But we can achieve some separation with monolith application and Clean Architecture helps here a lot, because we are limited to communicate only between infrastructure and interfaces layer. For example, we are not allowed to use anything from other bounded context’s domain/application/infrastructure in our bounded context.
It is extremely important to not void this rule. The best way to enforce it is to have a tool which can validate it and plug it into the CI.
Note
I’ve developed a tool, which can do it for Golang: go-cleanarch.
I’ve found a similar tool for PHP some time ago, but I cannot find it. There is a chance that tools like it exist for other languages. If you know any tool like this, please send it to me on Twitter: @roblaszczak and I’ll put it here :)
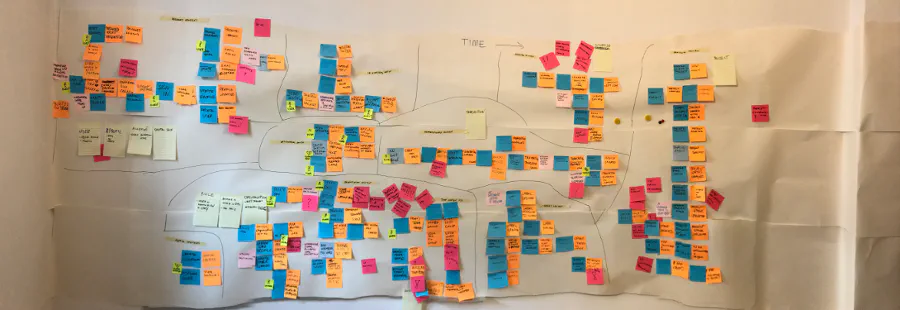
Unfortunately, the fact that we have modules doesn’t mean that our architecture is good. Good modules separation is critical for proper working monolith and microservices. To make it good we should check the concept of Bounded Contexts (at the bottom of the article). Another great tool which will show (physically!) where your Bounded Contexts are and show you how your domain is working is Event Storming.
There are a lot of people who say that persistence is just an implementation detail (Frameworks and Drivers part). They also say that persistence layer should be implemented so as to replace driver without any impact on any other layer than infrastructure.
Let’s look at the big picture diagram and go one step further: let’s say that whether the application is a microservice or a monolith is an implementation detail.
If it is true, we can start developing our application as Clean Monolith and when good moment comes, migrate it to microservices without much work and without touching other layers than interfaces/infrastructure. It is a similar approach to starting implementation of database driver in filesystem or memory, to defer the decision about choice of the database as long as we can.
Of course, it may still require some optimizations while migrating to microservices (or in the opposite direction, because why not?) it will be pretty easy operation, compared to classical monolith refactoring (or even worse, reimplementing).
I want not to be groundless. Here are some snippets from the source code of the application presented on the schema.
Show me the code
In this example we will follow simple shop flow which includes: placing the order, initializing payment and simulated asynchronous payment receiving.
Placing the order should be made synchronous, initializing and receiving payments is async.
Placing the order
In interfaces it’s nothing special. Just parsing HTTP request and executing a command in the application layer.
Note
In the top of every snippet you can check where it is located in the repository.
You can also read bounded context and layer from it. For example pkg/orders/interfaces/public/http/something.go is interfaces layer of orders bounded context.
// pkg/orders/interfaces/public/http/orders.go
func (o ordersResource) Post(w http.ResponseWriter, r *http.Request) {
req := PostOrderRequest{}
if err := render.Decode(r, &req); err != nil {
_ = render.Render(w, r, common_http.ErrBadRequest(err))
return
}
cmd := application.PlaceOrderCommand{
OrderID: orders.ID(uuid.NewV1().String()),
ProductID: req.ProductID,
Address: application.PlaceOrderCommandAddress(req.Address),
}
if err := o.service.PlaceOrder(cmd); err != nil {
_ = render.Render(w, r, common_http.ErrInternal(err))
return
}
w.WriteHeader(http.StatusOK)
render.JSON(w, r, PostOrdersResponse{
OrderID: string(cmd.OrderID),
})
}
Note
For people not familiar with Golang: in Go you don’t need to explicitly say that you are implementing an interface. You just need to implement interface’s methods.
A good example is io.Reader interface.
type Reader interface {
Read(p []byte) (n int, err error)
}
for example:
// no Foo implements io.Reader needed
type Foo struct {}
func (f Foo) Read(b []byte) (int, error) {
// ...
}
func SomeFunc(r io.Reader) {
buf := make([]byte, 10)
// ...
r.Read(buf)
// ...
}
// ...
SomeFunc(Foo{})
It’s more interesting in application service in pkg/orders/application/orders.go:
First of all, interfaces of Products Service (to get product data from Shop bounded context) and Payments Service (to initialize payment in Payments bounded context):
// pkg/orders/application/orders.go
type productsService interface {
ProductByID(id orders.ProductID) (orders.Product, error)
}
type paymentsService interface {
InitializeOrderPayment(id orders.ID, price price.Price) error
}
And finally the Application service. This is exactly the same for monolith and microservices. We just inject different productsService and paymentsService implementations.
We also use domain objects here and repository to persist Order in the database (in our case we use memory implementation, but it’s also a detail and can be changed to any storage).
// pkg/orders/application/orders.go
type OrdersService struct {
productsService productsService
paymentsService paymentsService
ordersRepository orders.Repository
}
// ...
func (s OrdersService) PlaceOrder(cmd PlaceOrderCommand) error {
address, err := orders.NewAddress(
cmd.Address.Name,
cmd.Address.Street,
cmd.Address.City,
cmd.Address.PostCode,
cmd.Address.Country,
)
if err != nil {
return errors.Wrap(err, "invalid address")
}
product, err := s.productsService.ProductByID(cmd.ProductID)
if err != nil {
return errors.Wrap(err, "cannot get product")
}
newOrder, err := orders.NewOrder(cmd.OrderID, product, address)
if err != nil {
return errors.Wrap(err, "cannot create order")
}
if err := s.ordersRepository.Save(newOrder); err != nil {
return errors.Wrap(err, "cannot save order")
}
if err := s.paymentsService.InitializeOrderPayment(newOrder.ID(), newOrder.Product().Price()); err != nil {
return errors.Wrap(err, "cannot initialize payment")
}
log.Printf("order %s placed", cmd.OrderID)
return nil
}
productsService implementation
Microservice
In microservices version we use HTTP (REST) interface to get product info. I’ve separated REST API’s to private (internal) and public (accessed by frontend, for example).
// pkg/orders/infrastructure/shop/http.go
import (
// ...
http_interface "github.com/ThreeDotsLabs/monolith-shop/pkg/shop/interfaces/private/http"
// ...
)
func (h HTTPClient) ProductByID(id orders.ProductID) (orders.Product, error) {
resp, err := http.Get(fmt.Sprintf("%s/products/%s", h.address, id))
if err != nil {
return orders.Product{}, errors.Wrap(err, "request to shop failed")
}
// ...
productView := http_interface.ProductView{}
if err := json.Unmarshal(b, &productView); err != nil {
return orders.Product{}, errors.Wrapf(err, "cannot decode response: %s", b)
}
return OrderProductFromHTTP(productView)
}
The REST endpoint in Shop bounded context looks like this:
// pkg/shop/interfaces/private/http/products.go
type productsResource struct {
repo products_domain.Repository
}
// ...
func (p productsResource) Get(w http.ResponseWriter, r *http.Request) {
product, err := p.repo.ByID(products_domain.ID(chi.URLParam(r, "id")))
if err != nil {
_ = render.Render(w, r, common_http.ErrInternal(err))
return
}
render.Respond(w, r, ProductView{
string(product.ID()),
product.Name(),
product.Description(),
priceViewFromPrice(product.Price()),
})
}
We also have a simple type which is used in HTTP response. In theory we can make Domain type serializable to JSON, but if we will do it every domain change will change our API contract, and every request for API contract change will change the domain. Doesn’t sound good and doesn’t have much in common with DDD and Clean Architecture.
// pkg/shop/interfaces/private/http/products.go
type ProductView struct {
ID string `json:"id"`
Name string `json:"name"`
Description string `json:"description"`
Price PriceView `json:"price"`
}
type PriceView struct {
Cents uint `json:"cents"`
Currency string `json:"currency"`
}
You can notice that ProductView is imported in pkg/orders/infrastructure/shop/http.go (example above), because, as I said before, imports from interfaces to infrastructure between bounded contexts are totally fine.
Monolith
In monolith version it’s pretty simple: in Orders bounded context we just call the function from Shop bounded context (intraprocess.ProductInterface:ProductByID) instead of calling REST API.
// pkg/orders/infrastructure/shop/intraprocess.go
import (
"github.com/ThreeDotsLabs/monolith-shop/pkg/orders/domain/orders"
"github.com/ThreeDotsLabs/monolith-shop/pkg/shop/interfaces/private/intraprocess"
)
type IntraprocessService struct {
intraprocessInterface intraprocess.ProductInterface
}
func NewIntraprocessService(intraprocessInterface intraprocess.ProductInterface) IntraprocessService {
return IntraprocessService{intraprocessInterface}
}
func (i IntraprocessService) ProductByID(id orders.ProductID) (orders.Product, error) {
shopProduct, err := i.intraprocessInterface.ProductByID(string(id))
if err != nil {
return orders.Product{}, err
}
return OrderProductFromIntraprocess(shopProduct)
}
And in Shop bounded context:
// pkg/shop/interfaces/private/intraprocess/products.go
type ProductInterface struct {
repo products.Repository
}
// ...
func (i ProductInterface) ProductByID(id string) (Product, error) {
domainProduct, err := i.repo.ByID(products.ID(id))
if err != nil {
return Product{}, errors.Wrap(err, "cannot get product")
}
return ProductFromDomainProduct(*domainProduct), nil
}
You can notice that in Orders bounded context we don’t import anything outside of Shops bounded context (as Clean Architecture assumes). So, we need some kind of transport type which can be imported in Shops BC.
type Product struct {
ID string
Name string
Description string
Price price.Price
}
It can look redundant and duplicated, but in practice it helps with keeping constant contract between bounded contexts. For example we can totally replace application and domain layer and don’t touch this type. You need to keep in mind that cost of avoiding duplication increases with scale. Also, duplication of data is not the same as duplication of behaviour.
Do you see some analogy to ProductView in microservices version?
Note
Looking back, “ipc” wasn’t the best name for this pattern. It’s too easy to confuse with Unix IPC (pipes, shared memory, message queues).
Today we’d call this pattern “module contracts.” The intraprocess package would become something like shop/api/module/client, where the shop module defines its contract.
If you want to practice this pattern hands-on, check out our Go Backend Masterclass. You build a real Go backend from scratch, including module contracts, HTTP/gRPC APIs, repositories, and testing.
Initializing payment
In the previous example we replaced HTTP Call with a Function call, which was synchronous. But how to deal with asynchronous operations? It depends. In Go it’s easy because of concurrency primitives. If it’s hard to achieve in your language you can just use Rabbit in the monolith.
Like in the previous example, both versions look the same in application and domain layer.
// pkg/orders/application/orders.go
type paymentsService interface {
InitializeOrderPayment(id orders.ID, price price.Price) error
}
func (s OrdersService) PlaceOrder(cmd PlaceOrderCommand) error {
// ..
if err := s.paymentsService.InitializeOrderPayment(newOrder.ID(), newOrder.Product().Price()); err != nil {
return errors.Wrap(err, "cannot initialize payment")
}
// ..
}
Microservices
In microservices we are using RabbitMQ to send message:
// pkg/orders/infrastructure/payments/amqp.go
// ...
func (i AMQPService) InitializeOrderPayment(id orders.ID, price price.Price) error {
order := payments_amqp_interface.OrderToProcessView{
ID: string(id),
Price: payments_amqp_interface.PriceView{
Cents: price.Cents(),
Currency: price.Currency(),
},
}
b, err := json.Marshal(order)
if err != nil {
return errors.Wrap(err, "cannot marshal order for amqp")
}
err = i.channel.Publish(
"",
i.queue.Name,
false,
false,
amqp.Publishing{
ContentType: "application/json",
Body: b,
})
if err != nil {
return errors.Wrap(err, "cannot send order to amqp")
}
log.Printf("sent order %s to amqp", id)
return nil
}
and to receive messages
// pkg/orders/interfaces/public/http/orders.go
// ...
type PaymentsInterface struct {
conn *amqp.Connection
queue amqp.Queue
channel *amqp.Channel
service application.PaymentsService
}
// ...
func (o PaymentsInterface) Run(ctx context.Context) error {
// ...
for {
select {
case msg := <-msgs:
err := o.processMsg(msg)
if err != nil {
log.Printf("cannot process msg: %s, err: %s", msg.Body, err)
}
case <-done:
return nil
}
}
}
func (o PaymentsInterface) processMsg(msg amqp.Delivery) error {
orderView := OrderToProcessView{}
err := json.Unmarshal(msg.Body, &orderView)
if err != nil {
log.Printf("cannot decode msg: %s, error: %s", string(msg.Body), err)
}
orderPrice, err := price.NewPrice(orderView.Price.Cents, orderView.Price.Currency)
if err != nil {
log.Printf("cannot decode price for msg %s: %s", string(msg.Body), err)
}
return o.service.InitializeOrderPayment(orderView.ID, orderPrice)
}
Monolith
In monolith version sending to channel is stupid easy
// pkg/orders/infrastructure/payments/intraprocess.go
type IntraprocessService struct {
orders chan <- intraprocess.OrderToProcess
}
func NewIntraprocessService(ordersChannel chan <- intraprocess.OrderToProcess) IntraprocessService {
return IntraprocessService{ordersChannel}
}
func (i IntraprocessService) InitializeOrderPayment(id orders.ID, price price.Price) error {
i.orders <- intraprocess.OrderToProcess{string(id), price}
return nil
}
and receiving (I only removed shutdown (close) support, to not complicate the code):
// pkg/payments/interfaces/intraprocess/orders.go
// ...
type PaymentsInterface struct {
orders <-chan OrderToProcess
service application.PaymentsService
orderProcessingWg *sync.WaitGroup
runEnded chan struct{}
}
// ..
func (o PaymentsInterface) Run() {
// ...
for order := range o.orders {
go func(orderToPay OrderToProcess) {
// ...
if err := o.service.InitializeOrderPayment(orderToPay.ID, orderToPay.Price); err != nil {
log.Print("Cannot initialize payment:", err)
}
}(order)
}
}
And more…
Marking order as paid works almost the same as placing the order (REST API/Function call). If you’re curious how it works, please check the full source code.
Full source can be found here: https://github.com/ThreeDotsLabs/monolith-microservice-shop
I’ve implemented some acceptance tests which will check that all flow works exactly the same for both monolith and microservices. Tests can be found in tests/acceptance_test.go.
You can find more info on how to run the project and tests in README.md.
There is still some code, which is not covered here. If you want to get a deeper understanding of this code, please follow me on the Twitter (@roblaszczak) or subscribe to our newsletter - you will be notified when the article is ready. You will learn some basic concepts of the Golang, if you don’t know it already. I will also make this code more production grade.
We are also planning to write some DevOps articles (Packer, Terraform, Ansible).
Summary
What about another microservices advantage? It will be less flexible, but you can still deploy monolith independently, although you must use different flow. For example, you can use feature branches where the master branch will be production and commits for not released changes should be merged into this feature branches. These branches should be used in the staging environment. This is true that monolith is harder to scale because you must scale entire application, not a single module. But in many cases, it is good enough. In this case we cannot assign one team per repository, but fortunately there won’t be many conflicts if modules are separated well. The only conflicts will occur in layers responsible for cross modules communication, but the same conflicts will occur in REST/Queue API’s. In monolith though it will have compile check unlike in microservices, where you must validate contracts, what requires extra work. Also, with monolith you will receive compile-check of shared types. The fast rewrite of the module (microservice in microservices architecture) is a matter of good modules separation - if the module is properly separated and designed you can replace it without touching anything outside.
Note
And I will repeat it again: there is no silver bullet. It always depends. But probably in most cases Clean Monolith will be enough for the beginning. If it will be well designed, the decision to move to microservices architecture will be not a problem.
In some cases (for example a small projects) it can be an overkill to write this all extra code for interfaces/infrastructure layer. But what is a small project? Well, it depends…
Plan before you start implementing. There is no “lack of design”, it is only good design and bad design. Event storming is a good idea to kick-off the project.
If you want to receive notification about the next article, you can subscribe to our newsletter or follow me on Twitter: @roblaszczak
I’m aware that I’ve introduced a lot of techniques, of which a major part might be new for you. The good news is that to have good architecture you don’t need to learn all of these techniques at the same time. It’s also hard to properly understand these techniques simultaneously. I would recommend starting with Clean Architecture, then check some basics of CQRS and then you can drive into DDD. At the end of the article, I will provide some useful resources, which I had used when I was learning these techniques.
If you have any questions, please write to me on Twitter.
Thanks for the inspiration for this article: @unclebobmartin, @vaughnvernon, @martinfowler and @mariuszgil.