Database Transactions in Go with Layered Architecture

As I join a new company, I often feel like an impostor. After all the interviews, they really seem to know what they’re doing. I’m humbled and ready to learn from the best.
On one such occasion, a few days in, I dealt with a production outage and asked the most senior engineer for help. They came to the rescue and casually flipped a value in the database with a manual update. 🤯 The root cause was that a set of SQL updates were not done within a transaction. Suddenly, I regretted not asking for higher compensation right away.
Onboarding is fun. What I learned this way is that even if something seems like a fundamental concept (e.g., SQL transactions), it may often be overlooked.
SQL seems like something we all know well, and there are few surprises. (It’s 50 years old!) Perhaps it’s a good time to reconsider, as we’re past the “NoSQL is cool” hype phase and back to “just use Postgres”, or even “SQLite is good enough”.
I want to focus here on how to keep transactions in the code rather than on their technical complexity. Once you need to organize a bigger project, perhaps by using layers, splitting the logic from the database code is not always that obvious. It’s easy to end up with a mess leading to obscure bugs.
The key idea of layers is to keep the critical parts of code (the logic) out of the implementation details (like the SQL queries). One way to achieve this separation is the Repository pattern. The hard part is handling transactions in this setup. When using transactions, you usually fetch data from the database, run some logic, update the data, and commit the transaction.
How do we model this in the code so we don’t end up with a mess across the layers? I often see people asking about this, and I know the pain from my experience. We had to figure this out, and the ideas evolved over time. Here’s a list of various approaches you can consider and everything I’ve learned along the way.
SQL Transactions 101
Let’s quickly reiterate why we need transactions at all.
Consider an e-commerce web app where users receive virtual points for purchasing products. The points can later be spent on discounts.
The user decides how many points they want to spend on a discount. We have to check if the user has enough points, then decrease them and apply a proper discount for the next order.
Let’s say a user wants to use 100 points. It could look roughly like this:
SELECT points FROM users where id = 19;
-- in the code: check if points >= 100
UPDATE users SET points = points - 100 WHERE id = 19;
UPDATE user_discounts SET next_order_discount = next_order_discount + 100 WHERE user_id = 19;
We should consider what can go wrong here, even if it’s unlikely.
Our application can suddenly exit after the first UPDATE statement.
Or, a network outage could prevent the second UPDATE from being executed. In this case, we would decrease the user’s points without giving them a discount.

Or a different scenario: If the user sends two (or more) requests very quickly, they could be processed concurrently.
If the requests execute the SELECT query before any updates, the check for the points balance won’t work correctly,
and the user could end up with -100 points and a 200 discount value.
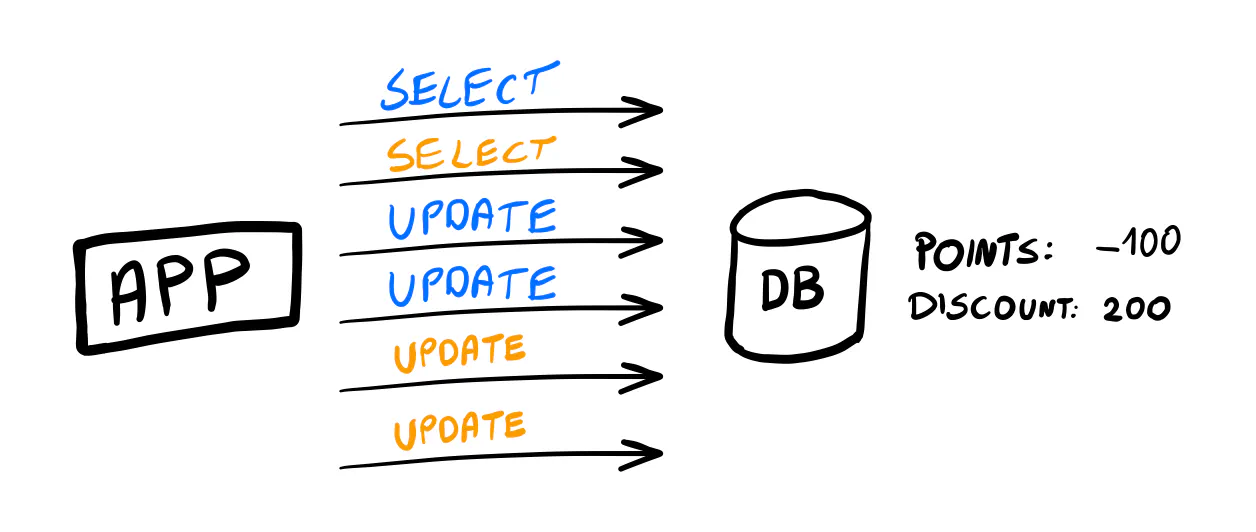
❌ Anti-pattern: Skipping transactions
Use transactions for sets of queries that rely on each other.
Even if unlikely, things can go wrong mid-request. You’ll be left with inconsistencies in the system that need manual effort to be understood and fixed.
If something can theoretically happen, it will likely happen in production at some point. Don’t accept solutions that almost always work. The 1% chance can turn into a nightmare investigation scenario in which you can’t understand what happened in your application and how to fix it.
We can easily improve this by introducing a transaction.
BEGIN;
SELECT points FROM users where id = 19 FOR UPDATE;
-- in the code: check if points >= 100
UPDATE users SET points = points - 100 WHERE id = 19;
UPDATE user_discounts SET next_order_discount = next_order_discount + 100 WHERE user_id = 19;
COMMIT;
Now, either all of the updates get saved or none.
Besides the BEGIN and COMMIT statements that manage the transaction, note the FOR UPDATE clause added to the SELECT.
It locks the row so that further SELECTS have to wait until this transaction is done. This lets us correctly process parallel requests.
Warning
FOR UPDATE works well for simple uses cases, but it may cause performance issues.
It locks the entire row, so if many concurrent updates are competing for it, they will all have to wait.
On a bigger scale, this can lead to a bottleneck.
An alternative is to use another isolation level, like REPEATABLE READ.
This is out of the scope of this post but you can check out this article for details.
Whatever you choose, consider running stress tests to see how your code behaves under load. It will help you avoid surprises in production when a traffic spike hits.
Layers
Splitting code into layers is pretty common, no matter how many you use or what you call the approach (clean, hexagonal, ports & adapters, onion, etc.). It makes sense for many reasons, like separation of concerns, enabling parallel work, and easier testing. We wrote about these concepts in our other articles.
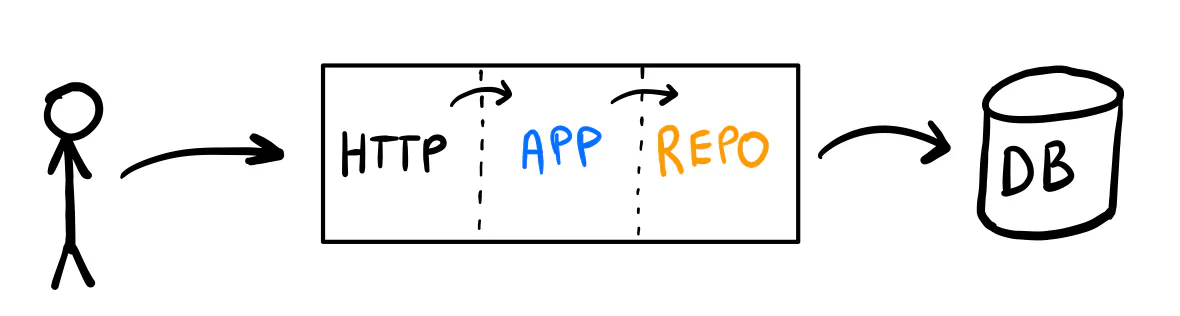
For the rest of this post, I assume you keep your SQL code in a place (struct, file, package, whatever) separate from your application logic and inject one into the other. In the example snippets, I keep the “layers” in different files but in the same package for simplicity.
http.go— the HTTP handler (we don’t care about this one much).app.go— the application logic.repository.go— the repository (the database storage).
In the application logic, I define the UsePointsAsDiscount command and a handler for it (see Robert’s CQRS article for more details on this).
You may prefer using something slightly different, like a service struct with methods or use cases.
That’s all fine. The key is that this part of the code knows nothing about the database used.
The repository is injected inside the command handler using an interface defined close to the handler’s definition.
Here’s how the code can look like with no transactions.
type UsePointsAsDiscount struct {
UserID int
Points int
}
type UsePointsAsDiscountHandler struct {
userRepository UserRepository
discountRepository DiscountRepository
}
type UserRepository interface {
GetPoints(ctx context.Context, userID int) (int, error)
TakePoints(ctx context.Context, userID int, points int) error
}
type DiscountRepository interface {
AddDiscount(ctx context.Context, userID int, discount int) error
}
func NewUsePointsAsDiscountHandler(
userRepository UserRepository,
discountRepository DiscountRepository,
) UsePointsAsDiscountHandler {
return UsePointsAsDiscountHandler{
userRepository: userRepository,
discountRepository: discountRepository,
}
}
func (h UsePointsAsDiscountHandler) Handle(ctx context.Context, cmd UsePointsAsDiscount) error {
if cmd.Points <= 0 {
return errors.New("points must be greater than 0")
}
currentPoints, err := h.userRepository.GetPoints(ctx, cmd.UserID)
if err != nil {
return fmt.Errorf("could not get points: %w", err)
}
if currentPoints < cmd.Points {
return errors.New("not enough points")
}
err = h.userRepository.TakePoints(ctx, cmd.UserID, cmd.Points)
if err != nil {
return fmt.Errorf("could not take points: %w", err)
}
err = h.discountRepository.AddDiscount(ctx, cmd.UserID, cmd.Points)
if err != nil {
return fmt.Errorf("could not add discount: %w", err)
}
return nil
}
There are two repositories: one for the user and one for the discounts. The handler’s logic is rather easy to grasp: we validate the command (points must be positive), check if the user has enough points, and subtract them from their account while adding a discount.
The repositories are trivial:
type PostgresDiscountRepository struct {
db *sql.DB
}
func NewPostgresDiscountRepository(db *sql.DB) *PostgresDiscountRepository {
return &PostgresDiscountRepository{
db: db,
}
}
func (r *PostgresDiscountRepository) AddDiscount(ctx context.Context, userID int, discount int) error {
_, err := r.db.ExecContext(ctx, "UPDATE user_discounts SET next_order_discount = next_order_discount + $1 WHERE user_id = $2", discount, userID)
return err
}
Note
In your project, you may call the repository a storage or something else. It’s a similar concept, although the Repository pattern is not only about database access. See Robert’s post for more details.
We’d like all of this to run within a single transaction, but we have a bunch of logic mixed with two repositories. Let’s see how to approach this.
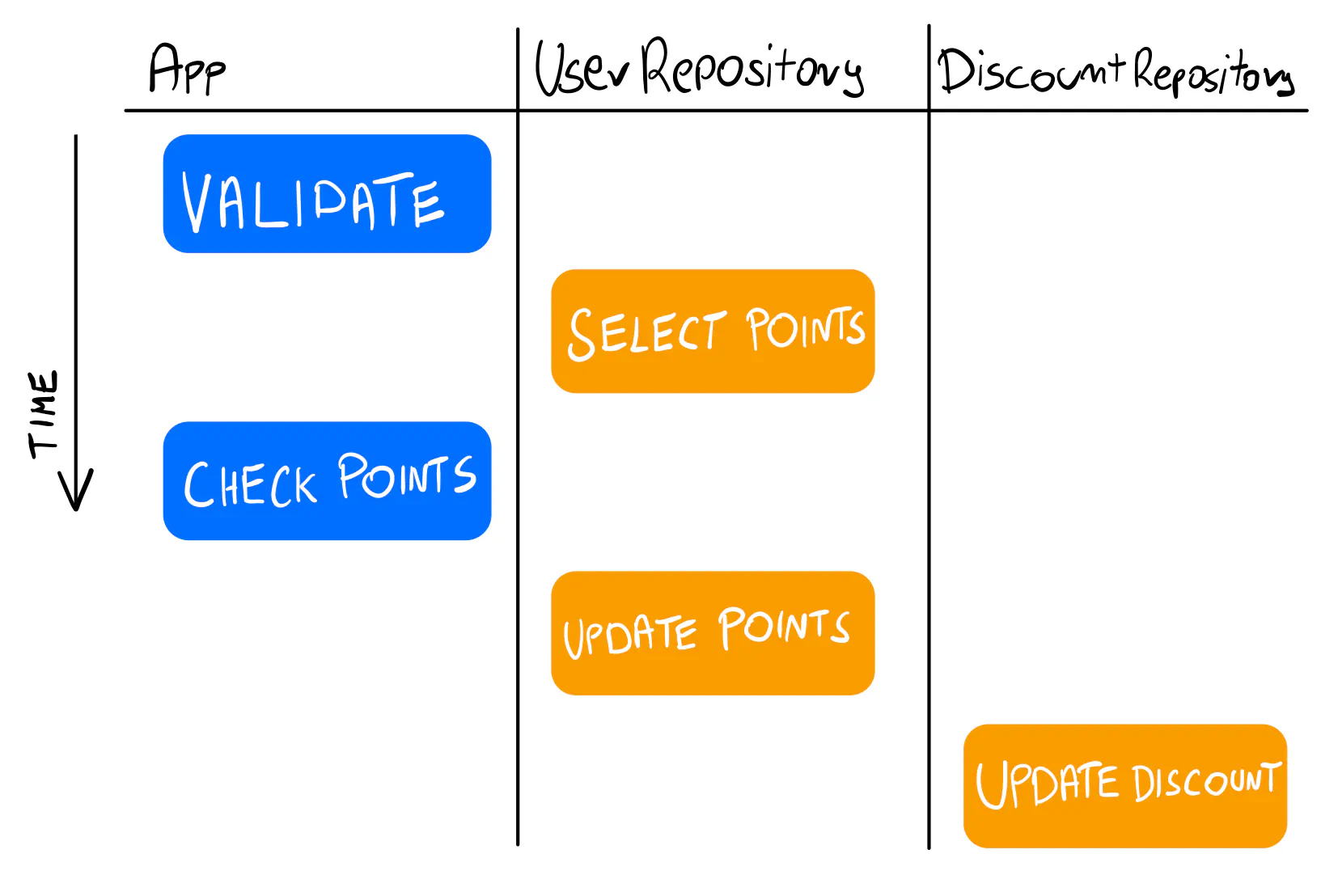
Note
All examples are available in the go-web-app-antipatterns repository. There’s a Docker Compose definition that lets you run all of them locally. They use Postgres as the database.
Transactions in the logic layer (avoid if you can)
The first idea for dealing with transactions across repositories is passing a transaction object around.
For running code in a transaction, we can use a helper function like the runInTx below.
func runInTx(db *sql.DB, fn func(tx *sql.Tx) error) error {
tx, err := db.Begin()
if err != nil {
return err
}
err = fn(tx)
if err == nil {
return tx.Commit()
}
rollbackErr := tx.Rollback()
if rollbackErr != nil {
return errors.Join(err, rollbackErr)
}
return err
}
It takes a function (you’ll see many anonymous functions in this post) that receives the transaction object.
Whatever happens within the fn function doesn’t know or care how the transaction is started, committed, or rolled back.
Here’s how it works when used inside the command handler.
func (h UsePointsAsDiscountHandler) Handle(ctx context.Context, cmd UsePointsAsDiscount) error {
return runInTx(h.db, func(tx *sql.Tx) error {
if cmd.Points <= 0 {
return errors.New("points must be greater than 0")
}
currentPoints, err := h.userRepository.GetPoints(ctx, tx, cmd.UserID)
if err != nil {
return fmt.Errorf("could not get points: %w", err)
}
if currentPoints < cmd.Points {
return errors.New("not enough points")
}
err = h.userRepository.TakePoints(ctx, tx, cmd.UserID, cmd.Points)
if err != nil {
return fmt.Errorf("could not take points: %w", err)
}
err = h.discountRepository.AddDiscount(ctx, tx, cmd.UserID, cmd.Points)
if err != nil {
return fmt.Errorf("could not add discount: %w", err)
}
return nil
})
}
The good part is that this approach works. But we can’t ignore the fact that it mixes the application logic with implementation details (the SQL transaction). It may not seem like a big deal: we will likely not change the database, so why be concerned about it?
For one, handling the transaction with the commit/rollback sequence complicates the flow. Instead of working with plain application logic, you now have to consider this additional behavior, which has nothing to do with what your application does. As the logic grows, you must carefully consider whether something should work within the transaction or outside of it. A rollback will affect everything you put inside the function.
Not to mention the weird tx argument you must pass to the repository methods.
Testing becomes awkward because you need to pass the transaction even if the method doesn’t need it at the time
(the GetPoints method could also work without transaction in another context).
You can’t mock the SQL connection to test the command handler, so it becomes an integration test instead of a simple unit test checking the logic.
You could try to work around this with an abstract Transaction object or perhaps pass it through the Context,
but it only masks the root issue of mixing the implementation details with the logic.
❌ Anti-pattern: Transactions mixed with logic
Avoid mixing transactions with your application logic. It’s challenging to grasp how it works, test the logic, and debug issues.
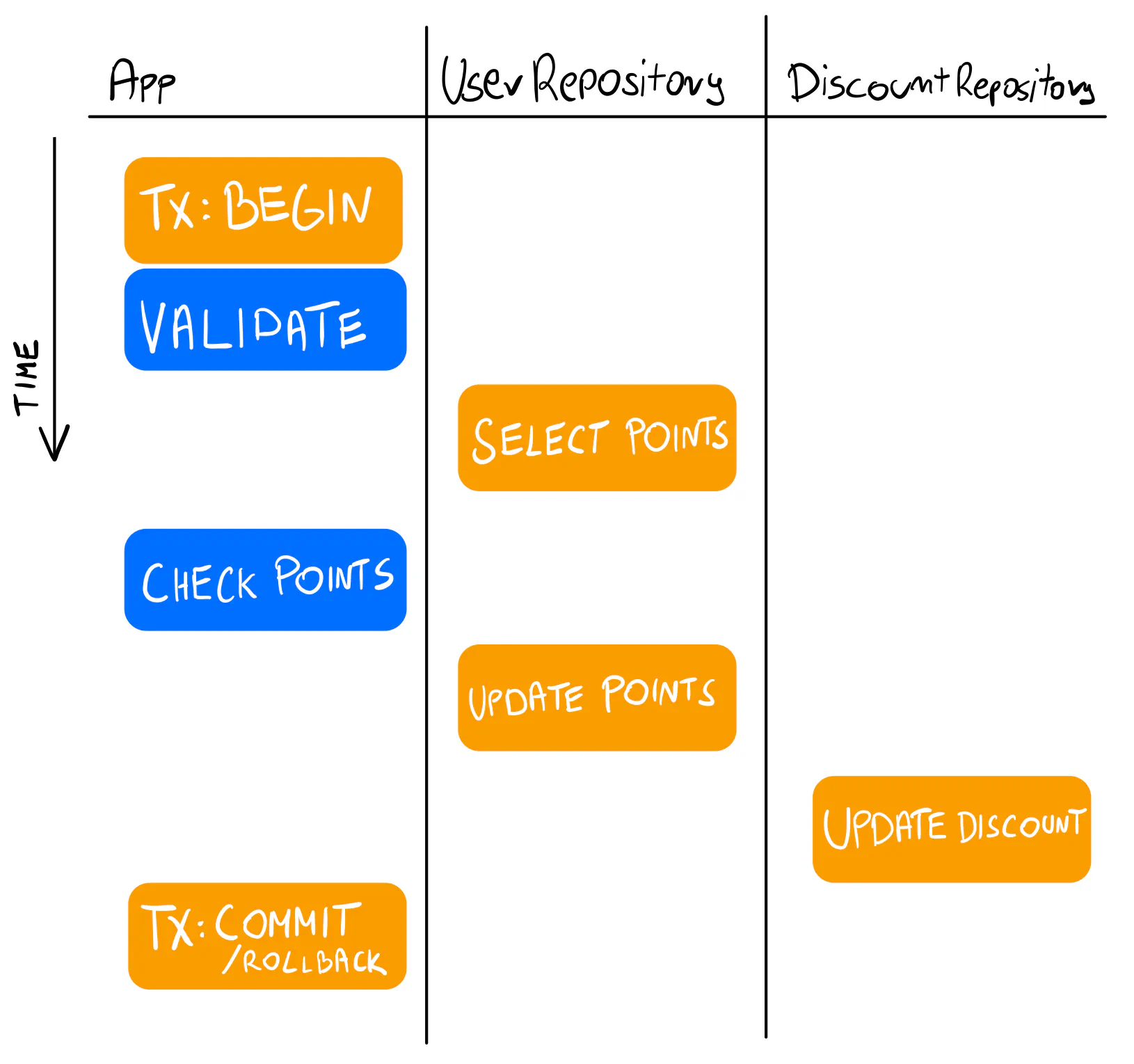
Transactions inside the repository (better, but far from perfect)
If the transaction belongs to the database layer, why not keep it there? The hard part is that we deal with two repositories, so they must somehow share the transaction object. Sometimes, it’s really the case (and I’ll show you how to do it in a bit). But first, we should consider if we really need two repositories.
It’s common to think of the database tables as your entities. This way, you end up with one repository per table and the application logic orchestrating them. Often, this split of repositories has no practical value.

❌ Anti-pattern: One repository per database table
Don’t create a repository for each database table. Instead, think of the data that needs to be transactionally stored together.
Data that should be transactionally consistent should also be coherent and kept as one. Domain-Driven Design proposes the idea of an aggregate — a set of data that must always be consistent. If you follow this idea, you don’t keep a repository per SQL table, but a repository per aggregate. (It’s the short version of the whole idea. We have a proper article coming up on aggregates soon.)
Join over 18k subscribers of our newsletter and get a free e-book!

Go With The Domain Three Dots Labs
We think of the user and the discounts as separate concepts (entities, structs, etc.). And it makes sense, as conceptually, they are different things. The user is used for identity and authentication. Placing orders with discounts is just one of many things a user can do on the website. But we also want to keep the user’s points and discounts consistent. We can consider them part of the same aggregate — a set of objects stored together transactionally.
In practice, we can consider discounts part of the User aggregate, even if we store them in another SQL table.
In that case, we need just one repository. And this lets us move the transaction handling there.
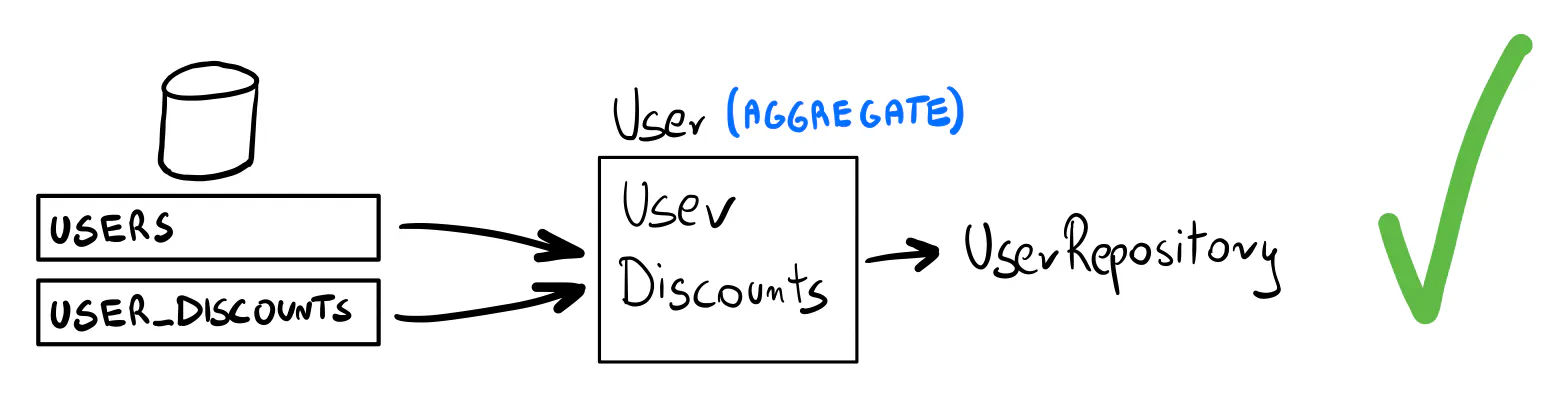
The application logic becomes trivial now.
func (h UsePointsAsDiscountHandler) Handle(ctx context.Context, cmd UsePointsAsDiscount) error {
if cmd.Points <= 0 {
return errors.New("points must be greater than 0")
}
err := h.userRepository.UsePointsForDiscount(ctx, cmd.UserID, cmd.Points)
if err != nil {
return fmt.Errorf("could not use points as discount: %w", err)
}
return nil
}
And the repository exposes a method specific to this one operation.
func (r *PostgresUserRepository) UsePointsForDiscount(ctx context.Context, userID int, points int) error {
return runInTx(r.db, func(tx *sql.Tx) error {
row := tx.QueryRowContext(ctx, "SELECT points FROM users WHERE id = $1 FOR UPDATE", userID)
var currentPoints int
err := row.Scan(¤tPoints)
if err != nil {
return err
}
if currentPoints < points {
return errors.New("not enough points")
}
_, err = tx.ExecContext(ctx, "UPDATE users SET points = points - $1 WHERE id = $2", points, userID)
if err != nil {
return err
}
_, err = tx.ExecContext(ctx, "UPDATE user_discounts SET next_order_discount = next_order_discount + $1 WHERE user_id = $2", points, userID)
if err != nil {
return err
}
return nil
})
}
✅ Tactic: Aggregates
Keep the data that needs to be strongly consistent within the same aggregate. Keep a repository for the aggregate.
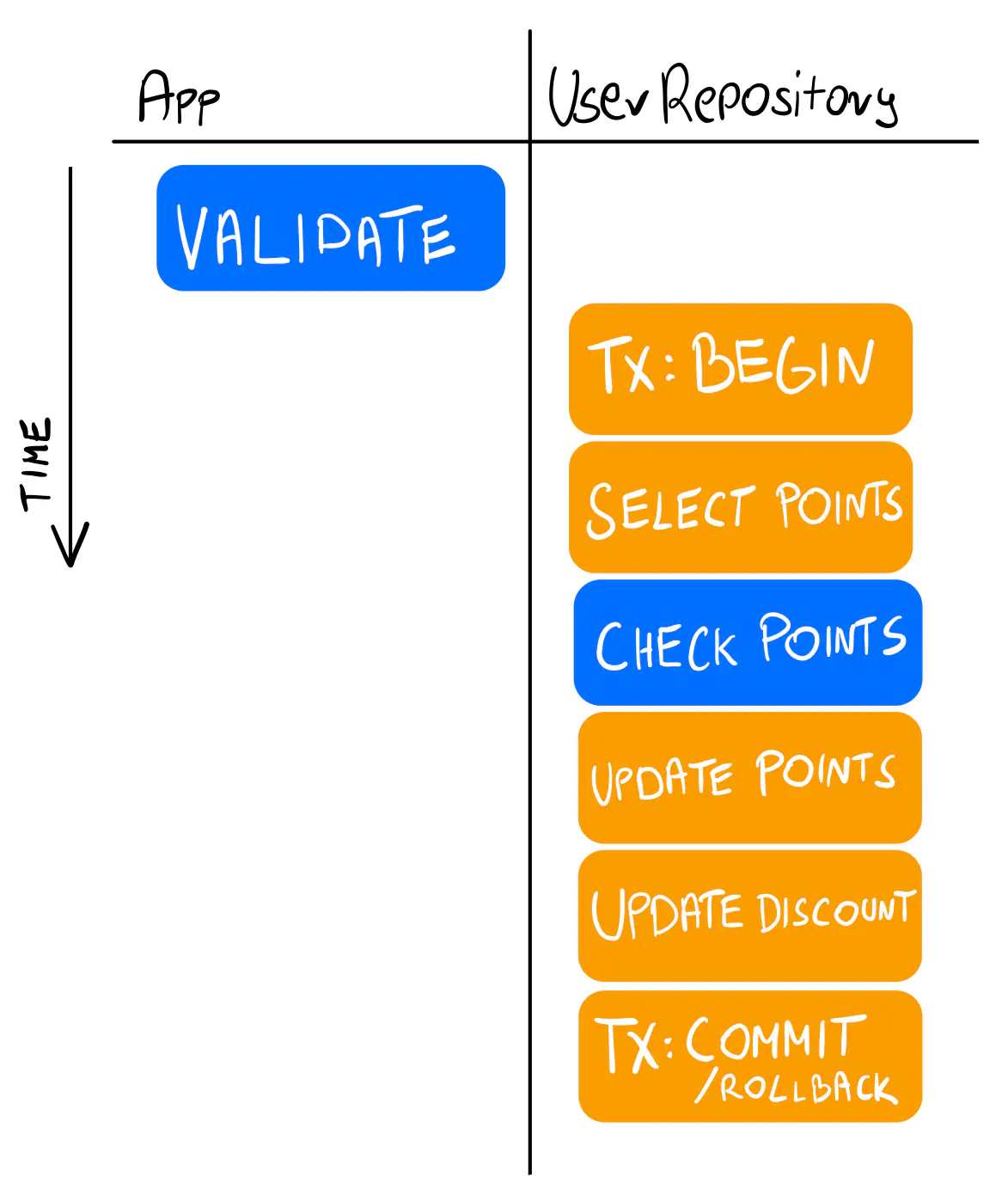
This approach still has some downsides. One is that we had to move the “has enough points” logic to the repository.
The method name (UsePointsForDiscount) makes it obvious the repository knows something about the logic, and occasionally it may be fine.
But ideally, we’d have the logic in the command handler.
The other issue is that with many methods like this, the repository’s interface grows and gets difficult to maintain and test. This is against the layers split we wanted to achieve.
While useful, this approach doesn’t scale well. It seems we could use a more generic Update method.
The UpdateFn Pattern (our go-to solution)
A universal Update method should load the user from the database, allow us to make any changes, and store the result.
The challenge, again, is how to make it work with transactions.
First, we need a model that combines the user with discounts (our aggregate). I use encapsulation to hide the fields, as we want the model to be always valid in memory. The only way to change the state is by calling exported methods.
type User struct {
id int
email string
points int
discounts *Discounts
}
func (u *User) ID() int {
return u.id
}
func (u *User) Email() string {
return u.email
}
func (u *User) Points() int {
return u.points
}
func (u *User) Discounts() *Discounts {
return u.discounts
}
type Discounts struct {
nextOrderDiscount int
}
func (c *Discounts) NextOrderDiscount() int {
return c.nextOrderDiscount
}
Adding a discount works by calling UsePointsAsDiscount.
func (u *User) UsePointsAsDiscount(points int) error {
if points <= 0 {
return errors.New("points must be greater than 0")
}
if u.points < points {
return errors.New("not enough points")
}
u.points -= points
u.discounts.nextOrderDiscount += points
return nil
}
Easy to grasp, trivial to test. No need to think about database transactions when reading it. In fact, no need to think about database tables, too. That’s the kind of code I want to work with.
Now, let’s introduce the update method interface.
type UserRepository interface {
UpdateByID(ctx context.Context, userID int, updateFn func(user *User) (bool, error)) error
}
The updateFn argument is how we keep the logic separate from the database details.
The function receives the User model that can be modified.
Any changes made to it are saved to the storage if no error is returned.
The updateFn returns an updated boolean value indicating whether the user has been updated.
If true is returned, the repository saves the user.
We don’t have a use case for returning false now, but it’s often helpful when updating multiple values (like in a generic PATCH update request).
The update may be unnecessary and can be skipped then.
The command handler looks like this now.
func (h UsePointsAsDiscountHandler) Handle(ctx context.Context, cmd UsePointsAsDiscount) error {
return h.userRepository.UpdateByID(ctx, cmd.UserID, func(user *User) (bool, error) {
err := user.UsePointsAsDiscount(cmd.Points)
if err != nil {
return false, err
}
return true, nil
})
}
Let’s take a look at the repository implementation.
func (r *PostgresUserRepository) UpdateByID(ctx context.Context, userID int, updateFn func(user *User) (bool, error)) error {
return runInTx(r.db, func(tx *sql.Tx) error {
row := tx.QueryRowContext(ctx, "SELECT email, points FROM users WHERE id = $1 FOR UPDATE", userID)
var email string
var currentPoints int
err := row.Scan(&email, ¤tPoints)
if err != nil {
return err
}
row = tx.QueryRowContext(ctx, "SELECT next_order_discount FROM user_discounts WHERE user_id = $1 FOR UPDATE", userID)
var discount int
err = row.Scan(&discount)
if err != nil {
return err
}
discounts := UnmarshalDiscounts(discount)
user := UnmarshalUser(userID, email, currentPoints, discounts)
updated, err := updateFn(user)
if err != nil {
return err
}
if !updated {
return nil
}
_, err = tx.ExecContext(ctx, "UPDATE users SET email = $1, points = $2 WHERE id = $3", user.Email(), user.Points(), user.ID())
if err != nil {
return err
}
_, err = tx.ExecContext(ctx, "UPDATE user_discounts SET next_order_discount = $1 WHERE user_id = $2", user.Discounts().NextOrderDiscount(), user.ID())
if err != nil {
return err
}
return nil
})
}
The repository has no logic at all.
It fetches the complete data from the user and discounts tables, translates them to application models (with the Unmarshal functions), and calls the updateFn function.
Then, it stores everything back in the database. All of it happens within a transaction.
Tip
The repository is quite verbose now. Using an ORM can help you get rid of the boilerplate. But be careful what library you choose, as some ORMs can do more harm than good. Check the libraries that never failed us.
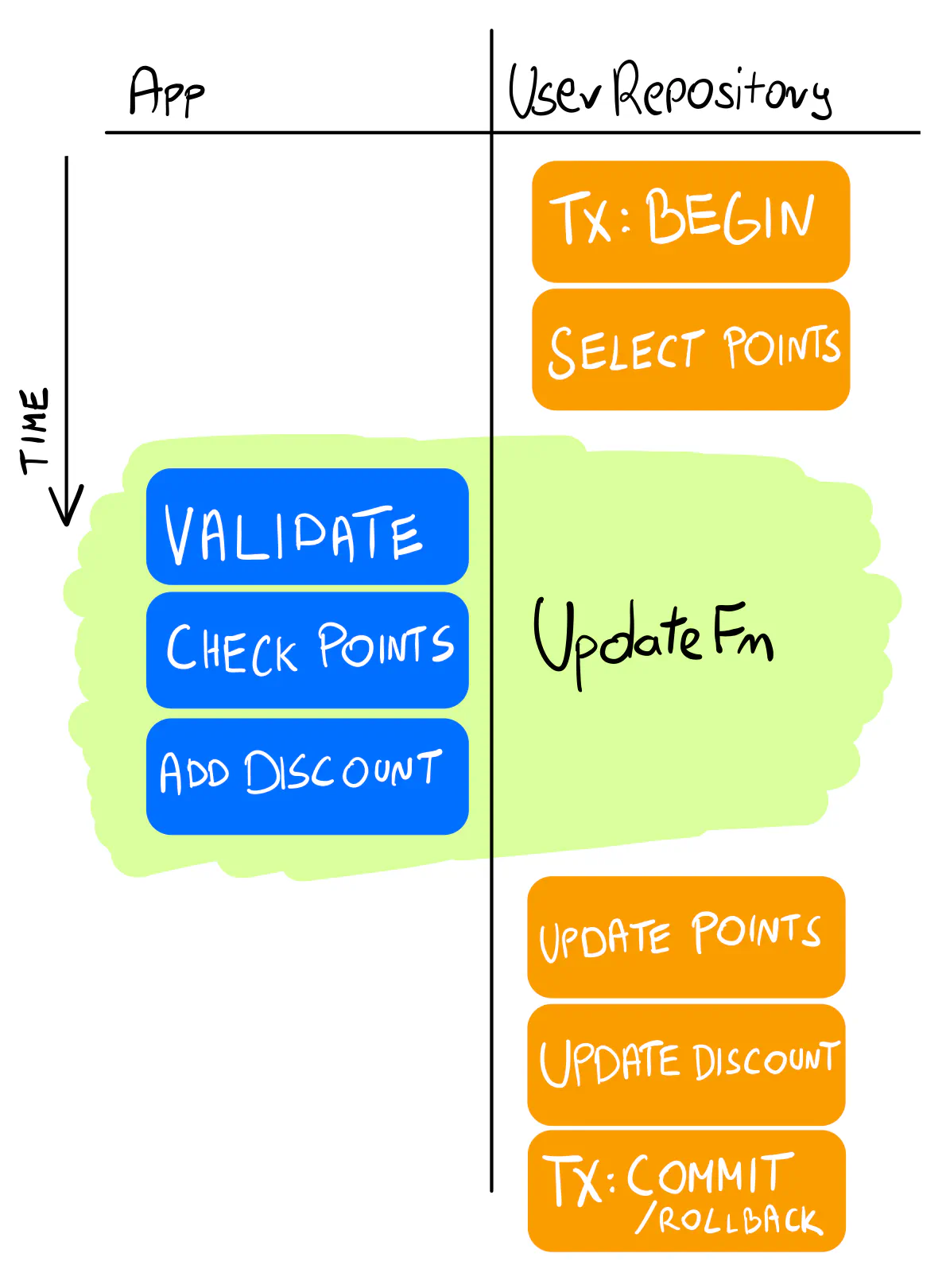
With this, we achieved the goal: the logic stays in the command handler, and the transaction remains in the repository.
✅ Tactic: The UpdateFn pattern
Use an Update method that loads and stores the aggregate. Keep the logic in the updateFn closure.
Note
Isn’t this inefficient?
A common concern about the Update method is that it needlessly updates all the fields even if they didn’t change (for example, the email in the example above).
Unless you’re saving huge datasets or dealing with massive scale, it shouldn’t really matter. You could track which fields changed and update only these, but it will likely only complicate your architecture with no actual performance gains. Be pragmatic and avoid premature optimization. If in doubt, run stress tests.
The Transaction Provider (for the edge cases)
I mentioned that sometimes, keeping a transaction across two repositories makes sense. While your first reaction should be, “Why isn’t this a single repository?” there may be a valid use case for it.
It usually works well for things that are not strictly related to your application’s domain but are more technical or platform-related.
For example, consider keeping an audit log of the users’ actions.
Saving it within the same transaction makes sense, but keeping it inside the User aggregate seems like overkill.
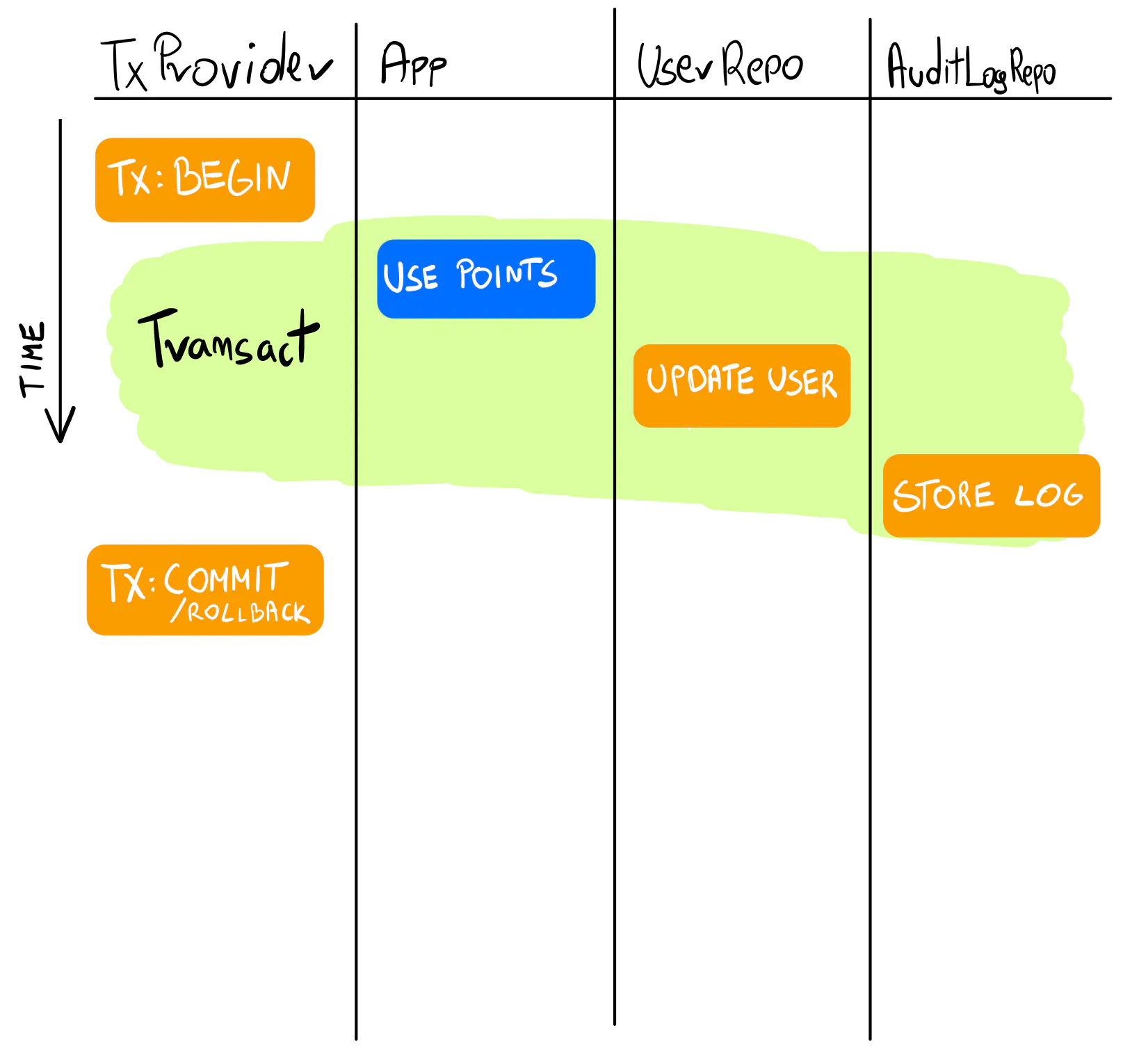
We can work around having an explicit transaction object mixed with logic using the Transaction Provider pattern. It works similarly to the first approach, but the application code is easier to read with the transaction mechanism working in the background.
type UsePointsAsDiscountHandler struct {
txProvider txProvider
}
type txProvider interface {
Transact(txFunc func(adapters Adapters) error) error
}
type Adapters struct {
UserRepository UserRepository
AuditLogRepository AuditLogRepository
}
The transaction provider has a Transact method that takes a function as an argument.
Within it, we can access adapters — a struct of all the dependencies we need, working within the same transaction.
Here’s how it looks in the command handler.
func (h UsePointsAsDiscountHandler) Handle(ctx context.Context, cmd UsePointsAsDiscount) error {
return h.txProvider.Transact(func(adapters Adapters) error {
err := adapters.UserRepository.UpdateByID(ctx, cmd.UserID, func(user *User) (bool, error) {
err := user.UsePointsAsDiscount(cmd.Points)
if err != nil {
return false, err
}
return true, nil
})
if err != nil {
return fmt.Errorf("could not use points as discount: %w", err)
}
log := fmt.Sprintf("used %d points as discount for user %d", cmd.Points, cmd.UserID)
err = adapters.AuditLogRepository.StoreAuditLog(ctx, log)
if err != nil {
return fmt.Errorf("could not store audit log: %w", err)
}
return nil
})
}
Note that both UserRepository and AuditLogRepository come from adapters, not the handler.
Also, we pass no transaction object to the repository methods.
The repositories now take the tx in the constructor.
It’s handy not to depend on *sql.Tx directly but to use an interface.
It also lets you pass an *sql.DB (for example, in tests).
type db interface {
QueryRowContext(ctx context.Context, query string, args ...interface{}) *sql.Row
ExecContext(ctx context.Context, query string, args ...interface{}) (sql.Result, error)
}
type PostgresUserRepository struct {
db db
}
func NewPostgresUserRepository(db db) *PostgresUserRepository {
return &PostgresUserRepository{
db: db,
}
}
The TransactionProvider implementation looks like this:
type TransactionProvider struct {
db *sql.DB
}
func NewTransactionProvider(db *sql.DB) *TransactionProvider {
return &TransactionProvider{
db: db,
}
}
func (p *TransactionProvider) Transact(txFunc func(adapters Adapters) error) error {
return runInTx(p.db, func(tx *sql.Tx) error {
adapters := Adapters{
UserRepository: NewPostgresUserRepository(tx),
AuditLogRepository: NewPostgresAuditLogRepository(tx),
}
return txFunc(adapters)
})
}
This approach seems clean enough, although you have to be careful.
With a set of transaction adapters, it’s easy to go too far and start calling methods from different repositories in a single handler.
It shouldn’t become your go-to tool. Stick to the UpdateFn pattern instead.
✅ Tactic: The Transaction Provider
Sometimes, it makes sense to share a transaction across repositories. In such a scenario, use the transaction provider pattern. Be careful not to over-use it.
Warning
The transaction provider is a risky pattern. If you use it together with FOR UPDATE,
you need to be extra careful, as all the SELECTs need to include the FOR UPDATE clause to work correctly.
This can quickly get out of control when working within a team with rapid changes.
Once again, consider using a different isolation level, like REPEATABLE READ.
Distributed Transactions
This wraps up our way of working with SQL transactions within a single service. But there’s a related topic that often comes up and that we should consider: transactions across services. I cover this in Distributed Transactions in Go: Read Before You Try.
Check the Source Code
You can see the complete source code on GitHub. There are basic tests that verify that all examples work in the same way. You can run it all locally with Docker Compose.



