How to implement Clean Architecture in Go (Golang)

The authors of Accelerate dedicate an entire chapter to software architecture and how it affects development performance. One recurring theme is designing applications to be “loosely coupled”.
The goal is for your architecture to support the ability of teams to get their work done—from design through to deployment—without requiring high-bandwidth communication between teams.
Note
If you haven’t read Accelerate yet, I highly recommend it. The book presents scientific evidence on methods leading to high performance in development teams. The approach I describe is not only based on our experiences but also mentioned throughout the book.
While coupling seems mostly related to microservices across multiple teams, we find loosely coupled architecture just as useful for work within a single team. Maintaining architecture standards enables parallel work and helps onboard new team members.
You’ve probably heard of the “low coupling, high cohesion” concept, but it’s rarely obvious how to achieve it. The good news: it’s the main benefit of Clean Architecture.
The pattern is not only an excellent way to start a project but also helpful when refactoring a poorly designed application. I focus on the latter in this post. I show the refactoring of a real application, so it should be clear how to apply similar changes in your projects.
We’ve also noticed other benefits of this approach:
- a standard structure, so it’s easy to find your way in the project,
- faster development in the long term,
- mocking dependencies becomes trivial in unit tests,
- easy switching from prototypes to proper solutions (e.g., changing in-memory storage to an SQL database).
Clean Architecture
I had a hard time coming up with this post’s title because the pattern comes in many flavors. There’s Clean Architecture, Onion Architecture, Hexagonal Architecture, and Ports and Adapters.
Over the past few years, we’ve tried to use these patterns in Go in an idiomatic way. This involved trying out approaches, failing, changing them, and trying again.
We arrived at a mix of the ideas above, sometimes not strictly following the original patterns, but we found it works well in Go. I’ll demonstrate our approach by refactoring Wild Workouts, our example application.
I want to point out that the idea is not new at all. A big part of it is abstracting away implementation details, a standard practice in technology, especially software.
Another name for it is separation of concerns. The concept is so old that it exists on several levels: structures, namespaces, modules, packages, and even (micro)services. All are meant to keep related things within a boundary. Sometimes, it feels like common sense:
- When you optimize an SQL query, you don’t want to risk changing the display format.
- When you change an HTTP response format, you don’t want to alter the database schema.
Our approach to Clean Architecture combines two ideas: separating Ports and Adapters, and limiting how code structures refer to each other.
Note
This is not just another article with random code snippets.
This post is part of a bigger series where we show how to build Go applications that are easy to develop, maintain, and fun to work with in the long term. We are doing it by sharing proven techniques based on many experiments we did with teams we lead and scientific research.
You can learn these patterns by building with us a fully functional example Go web application – Wild Workouts.
We did one thing differently – we included some subtle issues to the initial Wild Workouts implementation. Have we lost our minds to do that? Not yet. 😉 These issues are common for many Go projects. In the long term, these small issues become critical and stop adding new features.
It’s one of the essential skills of a senior or lead developer; you always need to keep long-term implications in mind.
We will fix them by refactoring Wild Workouts. In that way, you will quickly understand the techniques we share.
Do you know that feeling after reading an article about some technique and trying implement it only to be blocked by some issues skipped in the guide? Cutting these details makes articles shorter and increases page views, but this is not our goal. Our goal is to create content that provides enough know-how to apply presented techniques. If you did not read previous articles from the series yet, we highly recommend doing that.
We believe that in some areas, there are no shortcuts. If you want to build complex applications in a fast and efficient way, you need to spend some time learning that. If it was simple, we wouldn’t have large amounts of scary legacy code.
Here’s the full list of 14 articles released so far.
The full source code of Wild Workouts is available on GitHub. Don’t forget to leave a star for our project! ⭐
Before We Start
Before introducing Clean Architecture in Wild Workouts, I refactored the project a bit. The changes come from patterns we shared in previous posts.
The first one is using separate models for database entities and HTTP responses.
I’ve introduced changes in the users service in my post on the DRY principle.
I applied the same pattern now in trainer and trainings as well. See the full commit on GitHub.
The second change follows the Repository Pattern that Robert introduced in the previous article.
My refactoring moved database-related code in trainings to a separate structure.
Separating Ports and Adapters
Ports and Adapters can be called different names, like interfaces and infrastructure. The idea is to explicitly separate these two categories from the rest of your application code.
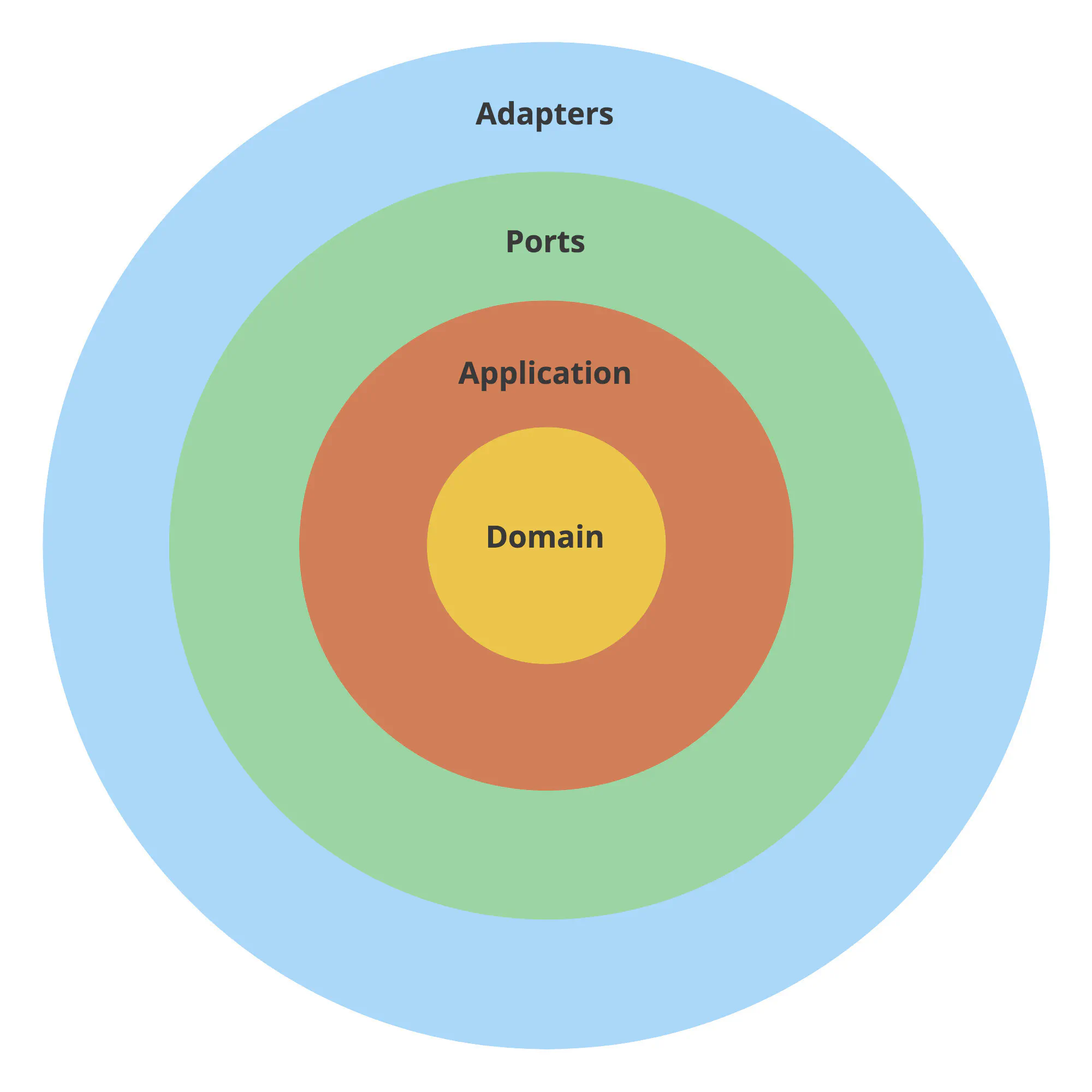
We take the code in these groups and place it in different packages. We refer to them as “layers”. The layers we usually use are adapters, ports, application, and domain.
Note
Read this if you know Hexagonal Architecture
You might be confused about the ports and adapters. We accidentally picked the same names for different things (even if they fit well).
- Our ports are Hexagonal Architecture’s Primary Adapters.
- Our adapters are Hexagonal Architecture’s Secondary Adapters.
The idea stays the same. We find the original primary/secondary naming hard to grasp, so feel free to use what works for you. You could use gateways, entry points, interfaces, infrastructure, and so on. Just make sure it’s consistent and your team knows what goes where.
What about the original ports? Thanks to Go’s implicit interfaces, we see no value in keeping a dedicated layer for them. We keep interfaces close to where they’re used (see below).
- An adapter is how your application talks to the external world. You have to adapt your internal structures to what the external API expects. Think SQL queries, HTTP or gRPC clients, file readers and writers, Pub/Sub message publishers.
- A port is an input to your application, and the only way the external world can reach it. It could be an HTTP or gRPC server, a CLI command, or a Pub/Sub message subscriber.
- The application logic is a thin layer that “glues together” other layers. It’s also known as “use cases”. If you read this code and can’t tell what database it uses or what URL it calls, it’s a good sign. Sometimes it’s very short, and that’s fine. Think about it as an orchestrator.
- If you also follow Domain-Driven Design, you can introduce a domain layer that holds just the business logic.
Note
If the idea of separating layers is still unclear, look at your smartphone. It uses similar concepts.
You can control your smartphone using physical buttons, the touchscreen, or a voice assistant. Whether you press the “volume up” button, swipe the volume bar up, or say “Siri, volume up,” the effect is the same. There are several entry points (ports) to the “change volume” logic.
When you play music, you hear it from the speaker. If you plug in headphones, the audio automatically switches to them. Your music app doesn’t care. It’s not talking to the hardware directly but using one of the adapters the OS provides.
Can you imagine creating a mobile app that has to know which headphones model is connected to the smartphone? Including SQL queries directly inside application logic is similar: it exposes implementation details.
Let’s start refactoring by introducing the layers in the trainings service. The project looks like this so far:
trainings/
├── firestore.go
├── go.mod
├── go.sum
├── http.go
├── main.go
├── openapi_api.gen.go
└── openapi_types.gen.go
This part of refactoring is simple:
- Create
ports,adapters, andappdirectories. - Move each file to the proper directory.
trainings/
├── adapters
│ └── firestore.go
├── app
├── go.mod
├── go.sum
├── main.go
└── ports
├── http.go
├── openapi_api.gen.go
└── openapi_types.gen.go
I introduced similar packages in the trainer service. We won’t make any changes to the users service this time. There’s no application logic there, and overall it’s tiny. As with every technique, apply Clean Architecture where it makes sense.
Note
If the project grows in size, you may find it helpful to add another level of subdirectories.
For example, adapters/hour/mysql_repository.go or ports/http/hour_handler.go.
You probably noticed there are no files in the app package. We now have to extract the application logic from HTTP handlers.
The Application Layer
Let’s see where our application logic lives. Take a look at the CancelTraining method in the trainings service.
func (h HttpServer) CancelTraining(w http.ResponseWriter, r *http.Request) {
trainingUUID := r.Context().Value("trainingUUID").(string)
user, err := auth.UserFromCtx(r.Context())
if err != nil {
httperr.Unauthorised("no-user-found", err, w, r)
return
}
err = h.db.CancelTraining(r.Context(), user, trainingUUID)
if err != nil {
httperr.InternalError("cannot-update-training", err, w, r)
return
}
}
This method is the entry point to the application. There’s not much logic there, so let’s go deeper into the db.CancelTraining method.

Inside the Firestore transaction, there’s a lot of code that doesn’t belong in database handling.
What’s worse, the application logic inside this method uses the database model (TrainingModel) for decision-making:
if training.canBeCancelled() {
// ...
} else {
// ...
}
Mixing business rules (like when a training can be canceled) with the database model slows down development because the code becomes hard to understand and reason about. It’s also difficult to test such logic.
To fix this, we add an intermediate Training type in the app layer:
type Training struct {
UUID string
UserUUID string
User string
Time time.Time
Notes string
ProposedTime *time.Time
MoveProposedBy *string
}
func (t Training) CanBeCancelled() bool {
return t.Time.Sub(time.Now()) > time.Hour*24
}
func (t Training) MoveRequiresAccept() bool {
return !t.CanBeCancelled()
}
It should now be clear on first read when a training can be canceled. We can’t tell how the training is stored in the database or what JSON format the HTTP API uses. That’s a good sign.
We can now update the database layer methods to return this generic application type instead of the database-specific structure (TrainingModel). The mapping is trivial because the structs have the same fields (but from now on, they can evolve independently from each other).
t := TrainingModel{}
if err := doc.DataTo(&t); err != nil {
return nil, err
}
trainings = append(trainings, app.Training(t))
The Application Service
We then create a TrainingsService struct in the app package that will serve as the entry point to the trainings application logic.
type TrainingService struct {
}
func (c TrainingService) CancelTraining(ctx context.Context, user auth.User, trainingUUID string) error {
}
So how do we call the database now? Let’s try to replicate what was used so far in the HTTP handler.
type TrainingService struct {
db adapters.DB
}
func (c TrainingService) CancelTraining(ctx context.Context, user auth.User, trainingUUID string) error {
return c.db.CancelTraining(ctx, user, trainingUUID)
}
This code won’t compile, though.
import cycle not allowed
package github.com/ThreeDotsLabs/wild-workouts-go-ddd-example/internal/trainings
imports github.com/ThreeDotsLabs/wild-workouts-go-ddd-example/internal/trainings/adapters
imports github.com/ThreeDotsLabs/wild-workouts-go-ddd-example/internal/trainings/app
imports github.com/ThreeDotsLabs/wild-workouts-go-ddd-example/internal/trainings/adapters
We need to decide how the layers should refer to each other.
The Dependency Inversion Principle
A clear separation between ports, adapters, and application logic is useful by itself. Clean Architecture takes it further with Dependency Inversion.
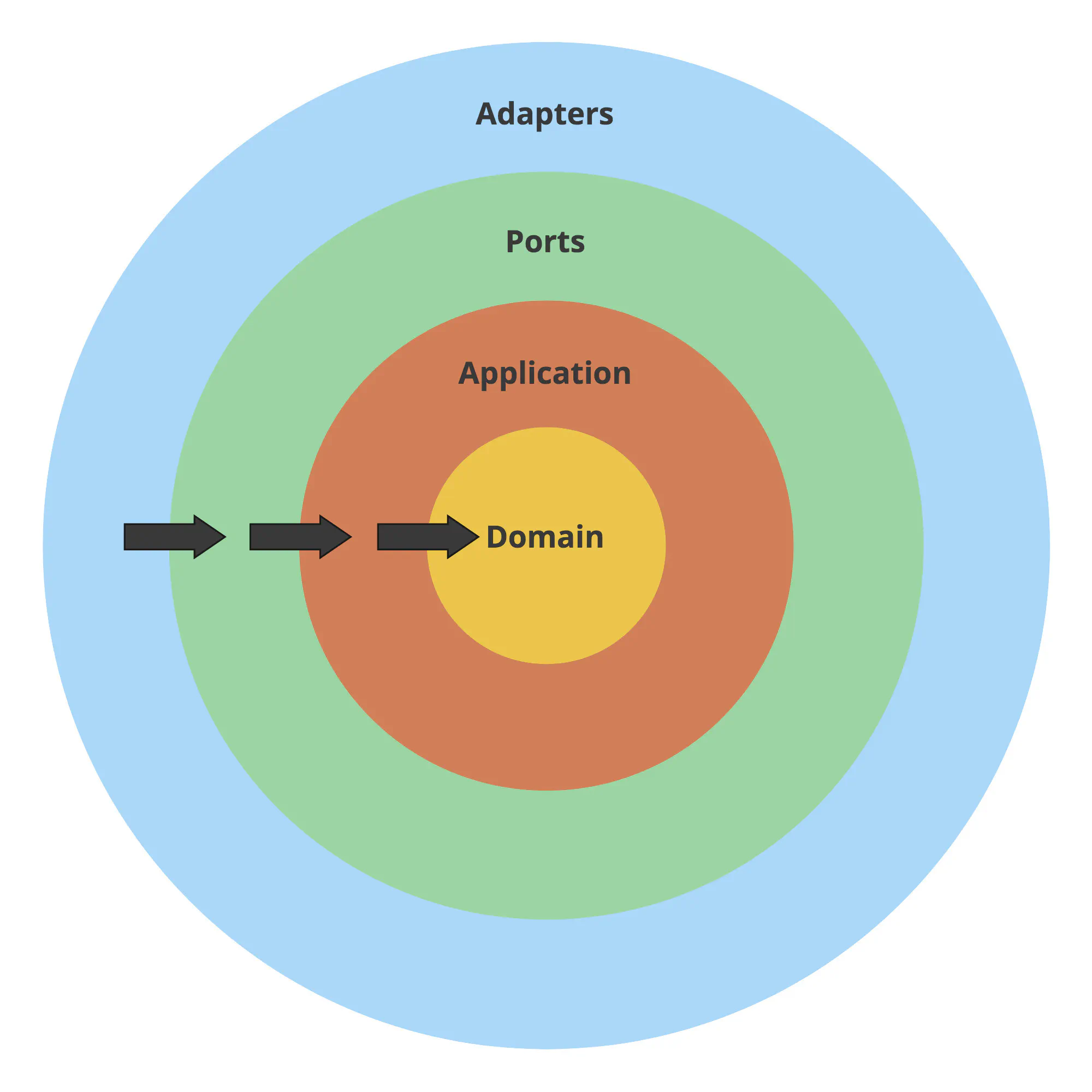
The rule states that outer layers (implementation details) can refer to inner layers (abstractions), but not the other way around. The inner layers should instead depend on interfaces.
- The Domain knows nothing about other layers whatsoever. It contains pure business logic.
- The Application can import domain but knows nothing about outer layers. It has no idea whether it’s being called by an HTTP request, a Pub/Sub handler, or a CLI command.
- Ports can import inner layers. Ports are the entry points to the application, so they often execute application services or commands. However, they can’t directly access Adapters.
- Adapters can import inner layers. Usually, they will operate on types found in Application and Domain, for example, retrieving them from the database.
Again, this is not a new idea. The Dependency Inversion Principle is the “D” in SOLID. Do you think it applies only to OOP? It turns out Go interfaces are a perfect match.
The principle addresses how packages should refer to each other. The best approach is rarely obvious, especially in Go, where import cycles are forbidden. Perhaps that’s why some developers claim it’s best to avoid “nesting” and keep all code in one package. But packages exist for a reason: separation of concerns.
Going back to our example, how should we refer to the database layer?
Because Go interfaces don’t need to be explicitly implemented, we can define them next to the code that needs them.
So the application service says: “I need a way to cancel a training with a given UUID. I don’t care how you do it, but I trust you to do it right if you implement this interface.”
type trainingRepository interface {
CancelTraining(ctx context.Context, user auth.User, trainingUUID string) error
}
type TrainingService struct {
trainingRepository trainingRepository
}
func (c TrainingService) CancelTraining(ctx context.Context, user auth.User, trainingUUID string) error {
return c.trainingRepository.CancelTraining(ctx, user, trainingUUID)
}
The database method calls gRPC clients of the trainer and users services. That’s not the proper place, so we introduce two new interfaces for the service to use.
type userService interface {
UpdateTrainingBalance(ctx context.Context, userID string, amountChange int) error
}
type trainerService interface {
ScheduleTraining(ctx context.Context, trainingTime time.Time) error
CancelTraining(ctx context.Context, trainingTime time.Time) error
}
Note
Note that “user” and “trainer” in this context are not microservices, but application (business) concepts. It just happens that in this project, they live in the scope of microservices with the same names.
We move implementations of these interfaces to adapters as UsersGrpc and TrainerGrpc. As a bonus, the timestamp conversion now happens there as well, invisible to the application service.
Extracting the Application Logic
The code compiles, but our application service doesn’t do much yet. Now it’s time to extract the logic and put it in the proper place.
Finally, we can use the update function pattern from the Repositories post to extract the application logic out of the repository.
func (c TrainingService) CancelTraining(ctx context.Context, user auth.User, trainingUUID string) error {
return c.repo.CancelTraining(ctx, trainingUUID, func(training Training) error {
if user.Role != "trainer" && training.UserUUID != user.UUID {
return errors.Errorf("user '%s' is trying to cancel training of user '%s'", user.UUID, training.UserUUID)
}
var trainingBalanceDelta int
if training.CanBeCancelled() {
// just give training back
trainingBalanceDelta = 1
} else {
if user.Role == "trainer" {
// 1 for cancelled training +1 fine for cancelling by trainer less than 24h before training
trainingBalanceDelta = 2
} else {
// fine for cancelling less than 24h before training
trainingBalanceDelta = 0
}
}
if trainingBalanceDelta != 0 {
err := c.userService.UpdateTrainingBalance(ctx, training.UserUUID, trainingBalanceDelta)
if err != nil {
return errors.Wrap(err, "unable to change trainings balance")
}
}
err := c.trainerService.CancelTraining(ctx, training.Time)
if err != nil {
return errors.Wrap(err, "unable to cancel training")
}
return nil
})
}
The amount of logic suggests we might want to introduce a domain layer in the future. For now, let’s keep it as is.
I described the process for just a single CancelTraining method. Refer to the full diff to see how I refactored all other methods.
Dependency Injection
How do we tell the service which adapter to use? First, we define a simple constructor for the service.
func NewTrainingsService(
repo trainingRepository,
trainerService trainerService,
userService userService,
) TrainingService {
if repo == nil {
panic("missing trainingRepository")
}
if trainerService == nil {
panic("missing trainerService")
}
if userService == nil {
panic("missing userService")
}
return TrainingService{
repo: repo,
trainerService: trainerService,
userService: userService,
}
}
Then, in main.go we inject the adapter.
trainingsRepository := adapters.NewTrainingsFirestoreRepository(client)
trainerGrpc := adapters.NewTrainerGrpc(trainerClient)
usersGrpc := adapters.NewUsersGrpc(usersClient)
trainingsService := app.NewTrainingsService(trainingsRepository, trainerGrpc, usersGrpc)
Using the main function is the simplest way to inject dependencies. We’ll explore the wire library as the project becomes more complex in future posts.
Join over 18k subscribers of our newsletter and get a free e-book!

Go With The Domain Three Dots Labs
Adding tests
Initially, the project had all layers mixed, and it wasn’t possible to mock dependencies. The only way to test it was with integration tests, requiring a proper database and all services running.
While it’s fine to cover some scenarios with such tests, they tend to be slower and not as enjoyable to work with as unit tests. After introducing these changes, I was able to cover CancelTraining with a unit test suite.
I used the standard Go approach of table-driven tests to make all cases easy to read and understand.
{
Name: "return_training_balance_when_trainer_cancels",
UserRole: "trainer",
Training: app.Training{
UserUUID: "trainer-id",
Time: time.Now().Add(48 * time.Hour),
},
ShouldUpdateBalance: true,
ExpectedBalanceChange: 1,
},
{
Name: "extra_training_balance_when_trainer_cancels_before_24h",
UserRole: "trainer",
Training: app.Training{
UserUUID: "trainer-id",
Time: time.Now().Add(12 * time.Hour),
},
ShouldUpdateBalance: true,
ExpectedBalanceChange: 2,
},
I didn’t use any libraries for mocking. You can use them if you like, but your interfaces should usually be small enough to write dedicated mocks by hand.
type trainerServiceMock struct {
trainingsCancelled []time.Time
}
func (t *trainerServiceMock) CancelTraining(ctx context.Context, trainingTime time.Time) error {
t.trainingsCancelled = append(t.trainingsCancelled, trainingTime)
return nil
}
Did you notice the unusually high number of unimplemented methods in repositoryMock? That’s because we use a single training service for all methods, so we need to implement the full interface even when testing just one method.
What about the boilerplate?
You might be wondering if we introduced too much boilerplate. The project did grow in lines of code, but that alone doesn’t do any harm. It’s an investment in loose coupling that will pay off as the project grows.
Keeping everything in one package may seem easier at first, but having boundaries helps when working in a team. If all your projects have a similar structure, onboarding new team members is straightforward. Consider how much harder it would be with all layers mixed (Mattermost’s app package is an example of this approach).
Handling application errors
One extra thing I added is port-agnostic errors with slugs. They allow the application layer to return generic errors that both HTTP and gRPC handlers can handle.
if from.After(to) {
return nil, errors.NewIncorrectInputError("date-from-after-date-to", "Date from after date to")
}
The error above translates to a 400 Bad Request HTTP response in ports. It includes a slug that can be translated on the frontend and shown to the user. It’s yet another pattern to avoid leaking implementation details into application logic.
What else?
I encourage you to read through the full commit to see how I refactored other parts of Wild Workouts.
You might be wondering how to enforce correct usage of layers. Is it yet another thing to remember in code reviews?
Luckily, you can check the rules with static analysis. Use Robert’s go-cleanarch linter locally or include it in your CI pipeline.
With layers separated, we’re ready to introduce more advanced patterns.
Next time, Robert will show how to improve the project by applying CQRS.
If you’d like to read more on Clean Architecture, see Why using Microservices or Monolith can be just a detail?.