Blog Posts
- Home /
- Blog Posts
Microservices test architecture. Can you sleep well without end-to-end tests?

Do you know the rare feeling when you develop a new application from scratch and can cover all lines with proper tests? I said “rare” because most of the time, you will work with software with a long history, multiple contributors, and not so obvious testing approach. Even if the code uses good patterns, the test suite doesn’t always follow.

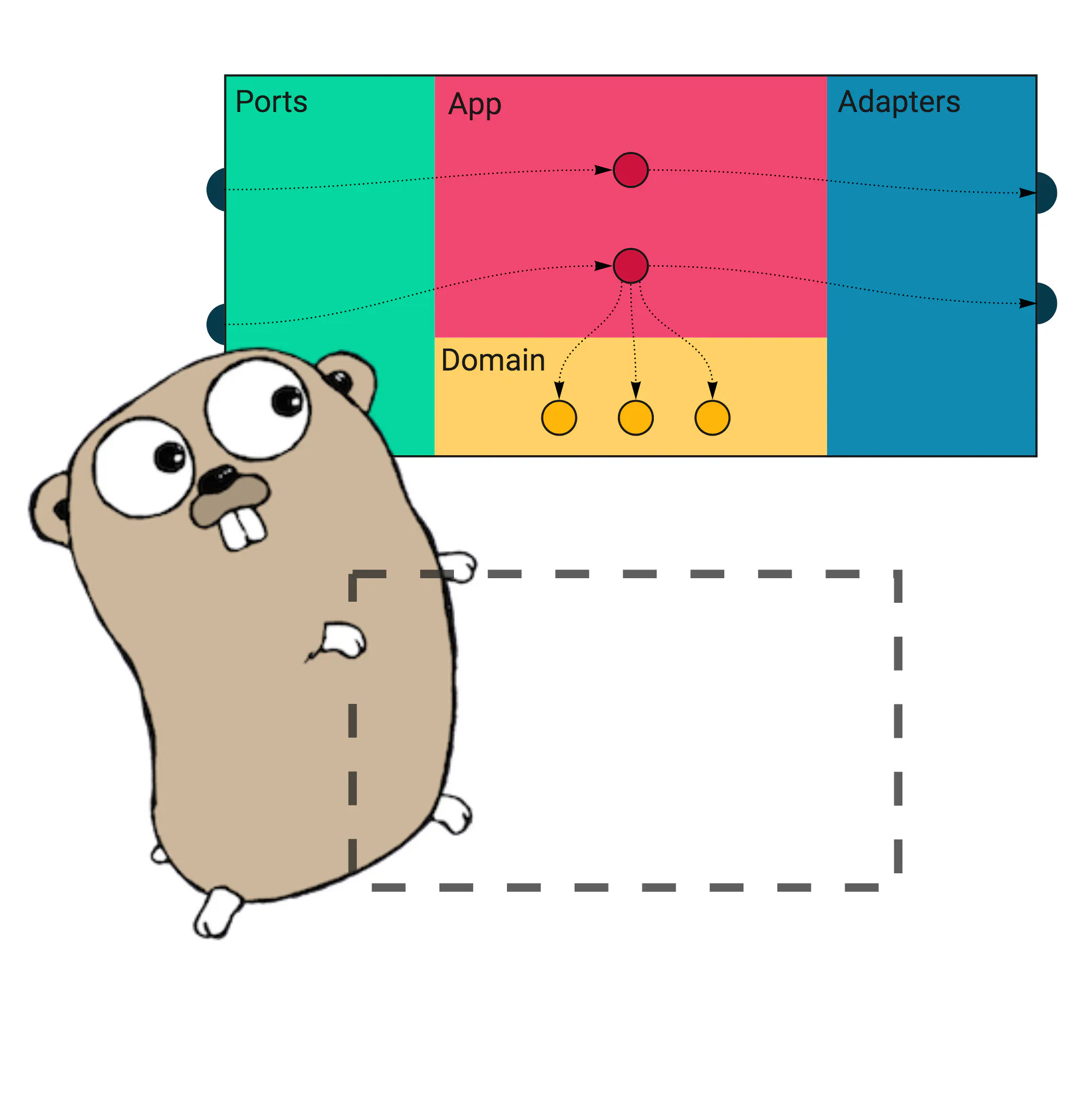
Combining DDD, CQRS, and Clean Architecture in Go

In the previous articles, we introduced techniques like DDD Lite, CQRS, and Clean (Hexagonal) Architecture. Even if using them alone is beneficial, they work the best together. Like Power Rangers. Unfortunately, it is not easy to use them together in a real project. In this article, I will show you how to connect DDD Lite, CQRS, and Clean Architecture in the most pragmatic and efficient way.
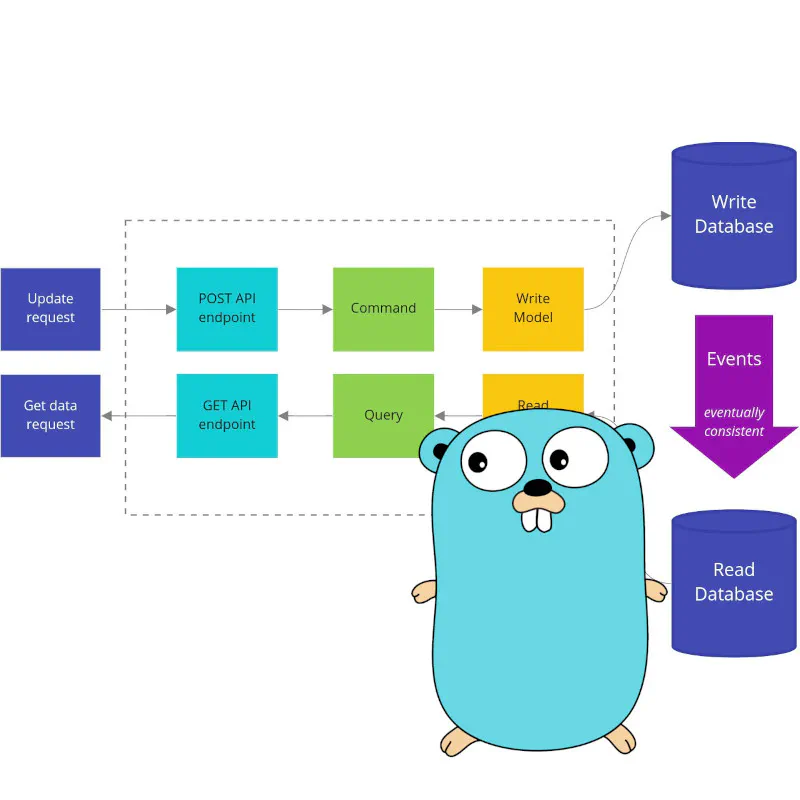
How to use basic CQRS in Go
It’s highly likely you know at least one service that: has one big, unmaintainable model that is hard to understand and change, or where work in parallel on new features is limited, or can’t be scaled optimally. But often, bad things come in threes. It’s not uncommon to see services with all these problems. What is an idea that comes to mind first for solving these issues?
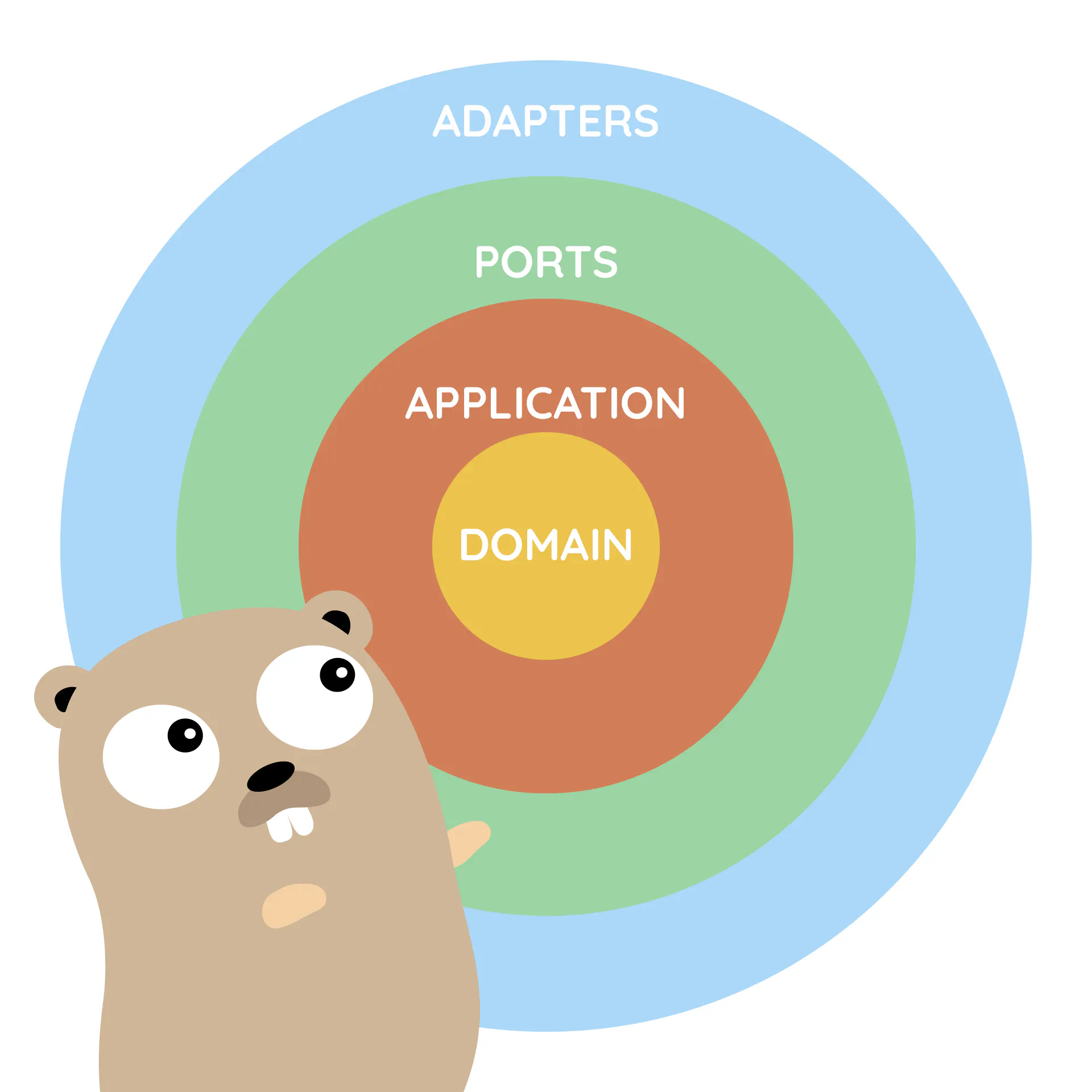
How to implement Clean Architecture in Go (Golang)
The authors of Accelerate dedicate a whole chapter to software architecture and how it affects development performance. One thing that often comes up is designing applications to be “loosely coupled”. The goal is for your architecture to support the ability of teams to get their work done—from design through to deployment—without requiring high-bandwidth communication between teams. Accelerate Note If you haven’t read Accelerate yet, I highly recommend it.

4 practical principles of high-quality database integration tests in Go
Did you ever hear about a project where changes were tested on customers that you don’t like or countries that are not profitable? Or even worse – did you work on such project? It’s not enough to say that it’s just not fair and not professional. It’s also hard to develop anything new because you are afraid to make any change in your codebase.

The Repository pattern in Go: a painless way to simplify your service logic
I’ve seen a lot of complicated code in my life. Pretty often, the reason of that complexity was application logic coupled with database logic. Keeping logic of your application along with your database logic makes your application much more complex, hard to test, and maintain. There is already a proven and simple pattern that solves these issues. The pattern that allows you to separate your application logic from database logic.

Introduction to DDD Lite: When microservices in Go are not enough
When I started working in Go, the community was not looking positively on techniques like DDD (Domain-Driven Design) and Clean Architecture. I heard multiple times: “Don’t do Java in Golang!”, “I’ve seen that in Java, please don’t!”. These times, I already had almost 10 years of experience in PHP and Python. I’ve seen too many bad things already there. I remember all these “Eight-thousanders” (methods with +8k lines of code 😉) and applications that nobody wanted to maintain.

When to avoid DRY in Go
In case you’re here for the first time, this post is the next in our Business Applications in Go series. Previously, we introduced Wild Workouts, our example application built in a modern way with some subtle anti-patterns. We added them on purpose to present common pitfalls and tips on how to avoid them. In this post, we begin refactoring of Wild Workouts.

You should not build your own authentication
Welcome in the third and last article covering how to build “Too Modern Go application”. But don’t worry. It doesn’t mean that we are done with showing you how to build applications that are easy to develop, maintain, and fun to work with in the long term. It’s actually just the beginning of a bigger series! We intentionally built the current version of the application to make it hard to maintain and develop in the future.

Robust gRPC communication on Google Cloud Run (but not only!)
Welcome in the third article form the series covering how to build business-oriented applications in Go! In this series, we want to show you how to build applications that are easy to develop, maintain, and fun to work in the long term. In this week’s article I will describe how you can build robust, internal communication between your services using gRPC.
Series
Popular articles
- The Go libraries that never failed us: 22 libraries you need to know
- Safer Enums in Go
- Common Anti-Patterns in Go Web Applications
- How to implement Clean Architecture in Go (Golang)
- The Repository pattern in Go: a painless way to simplify your service logic
- Introduction to DDD Lite: When microservices in Go are not enough
Tags
- go
- golang
- watermill
- ddd
- clean-architecture
- domain-driven design
- events
- web-applications
- anti-patterns
- event-driven
- ci
- firestore
- software-development
- architecture
- cloudrun
- gcloud
- googlecloud
- serverless
- testing
- advanced
- databases
- devops
- firebase
- gitlab
- microservices
- reactive
- repository
- backend
- basics
- building-business-applications
- building-in-public
- cqrs
- frameworks
- kafka
- mysql
- nats
- pipelines
- scalability
- software-architecture
- transactions
- amqp
- authentication
- balance
- bounded-context
- c4
- cicd
- code-quality
- code-review
- design-patterns
- diagrams
- docker
- dry
- e-book
- efficiency
- enums
- event-storming
- gamedev
- generics
- google-cloud
- grpc
- htmx
- intermediate
- iteration
- javascript
- learning
- libraries
- maintainability
- metrics
- monolith
- open-source
- openapi
- over-engineering
- overengineering
- parallelism
- productivity
- programming-languages
- prometheus
- pull-requests
- python
- rabbitmq
- retrospective
- security
- sql
- sse
- startups
- strategic-ddd
- swagger
- terraform
- tips
- unpopular-opinions
- versioning